Part II: Explore & Customize Site Level, Time Series Wetlands Data
The publicly available datasets we just explored are helpful for familiarizing yourself with your study area or for regional or other large-scale analyses. However, they do not contain the level of detail for the site level analysis we want to conduct. The highest resolution data you can usually find is 1:24,000 scale for vector data and 30 m cell size for raster data. Publicly available datasets also typically do not have time-series information available. In Part II, we are going to explore a high resolution, time-series dataset that was digitized from the aerial photos we reviewed in Part I. Oftentimes, you will need to digitize information in this manner if you have a small study site or if you want to do an in-depth, time series analysis. The work required to create the data is significant. However, you can do a lot more with your data.
We want to explore how vegetation has changed over time in our study area. To answer our research questions, we need the following datasets: 1) polygons of vegetation species over time 2) polygons of vegetation groups over time, and 3) polygons of invasive species over time. All of the files need to show just the region within our study site. We will create these custom datasets for three time periods using the Join, Union, Clip, and Dissolve tools. The workflow we will follow is illustrated in the diagram below using the data for the seventies time period. You may wish to consult this diagram after completing each step.
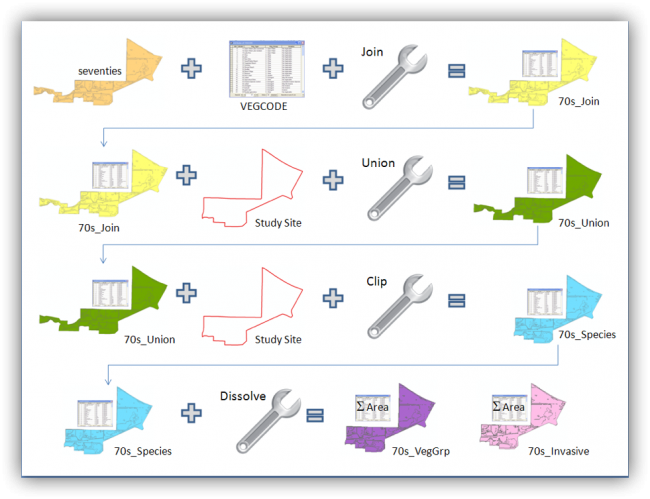
- Seventies + VEGCODE + join = 70s_Join
- 70s_Join + Study Site + union = 70s_union
- 70s_union + Study Site + clip = 70s_species
- 70s_species + dissolve = 70s_VegGrp + 70s_Invasive
-
Explore the Site Level Vegetation Data
- Open the map from Part I.
- Add the “sixties,” “seventies,” and “twothousands” vegetation shapefiles from the L3 folder to your map.
- The default symbology should show the vegetation polygons filled in. Do you see any gaps in coverage between the vegetation data and site boundary? Hint: turn some of the layers on and off and use the zoom tools. Look along the coastline along the northeast boundary.
- Compare the extents of the vegetation data and study site. Do you see any differences?
- Open the attribute tables. Do you notice any differences in the number of records in each dataset? Do you see any coded or missing values? Missing data may sometimes be coded as values of “0.”
- Notice how the vegetation files contain a lot more spatial detail than the publicly available datasets we looked at earlier. At this point, we do not know what the values in “VEG_ID” mean, though we can assume they correspond to different types of vegetation. Even without knowing what the “VEG_ID’s” mean, we can still tell that the "twothousands" data has a lot more polygons than the other time periods. What do you think the VEG_ID code “11” means?
-
Understand Coded Values
- Now that we have a general sense of what our starting data looks like, we can work on customizing it for our purposes. Let’s start by figuring out what the coded values in the “VEG_ID” fields mean.
- Add the “VEGCODE.dbf” table from your L3 folder to your map. Open the table.
- The VEGCODE table is a master lookup table that tells us what the coded values (VEG_IDs) mean. The VEG_IDs correspond with detailed vegetation types (Veg_Type).
- I have reclassified this information for you into 2 simpler categories: Veg_Group and Invasive. The numbers at the beginning allow us to sort the values based on the depth of water they prefer (e.g., most water (open water) to least water (upland vegetation) instead of alphabetically by name).
Note: You may notice that some of the Veg_IDs are listed as “May Be Invasive” in the “Invasive” field. Two of the most common invasive species in the wetland (narrow-leaved and hybrid narrow/broad-leaved cattails) look very similar to native species (broad-leaved cattails,) which makes them difficult to distinguish in aerial photos.
- Join the VEGCODE table to the sixties vegetation shapefile Right-click on the “sixties” shapefile > Joins and Relates > Add Join. Base the join on the Veg_IDs. Keep All Target Features. Validate the join and then click OK.
Caution - watch out for similar attribute names like OID. This is not the same as Veg_ID.
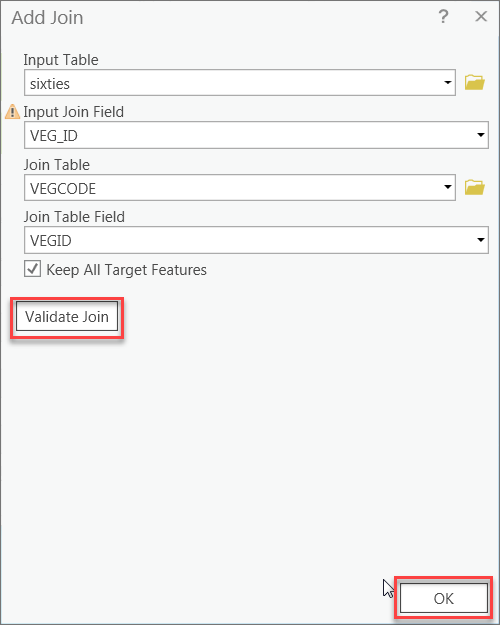 Add Join
Add Join - Open the attribute table of the sixties shapefile to make sure the join worked properly.
- To make the join permanent, export features to a new shapefile in your L3 folder called “60s_Join.” Be sure the new shapefile is added to your map.
- Repeat steps e - g for the remaining two vegetation data sets. Name them “70s_Join” and “00s_Join.” Remove the “sixties,” “seventies,” “twothousands,” and VEGCODE table from your map and save.

Make sure you have the correct answer before moving on to the next step.
The 60s_Join, 70s_Join, and 00s_Join shapefiles should have the number of records and all of the attributes shown below. If your data does not match this, go back and redo the previous step.
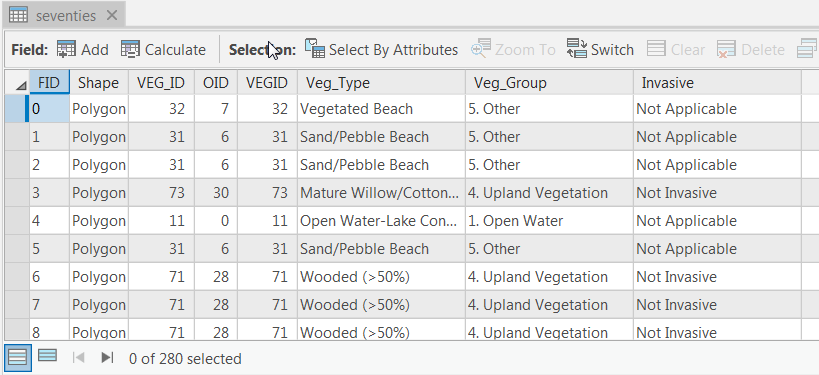 60s_Join - 352, 70s_Join – 280 records and 00s_Join – 449 records.
60s_Join - 352, 70s_Join – 280 records and 00s_Join – 449 records. -
Modify Extents - Fill in Gaps
- We want all of our input data sets to have the same total area so we can compare changes in the area of different vegetation types over time. This means we need to remove pieces from some study years and fill in gaps for other years so they all cover the same extent.
- First, we will fill in gaps. A quick way to fill in gaps is to use the union tool to create new polygons in areas that overlap within the extent of two datasets. We will union the vegetation shapefiles with the study boundary since this file does not have any gaps and it covers the area we are interested in. Follow the steps below to union the two files:
- Go to the Analysis tab, Tools group > Union
 Union tool.
Union tool. - Click on the “Show Help”
 button for more information about what the tool does and what the different input criterion means.
button for more information about what the tool does and what the different input criterion means. - Input Features: Study Site; 60s_Join (make sure the study site is listed first).
- Output Feature Class: 60s_Union.shp (save it in your L3 folder not in the default.gdb).
- Keep the defaults for Join Attributes (ALL).
- Make sure the “Gaps Allowed” checkbox is NOT checked. Read the help topic about this, so you understand why.
- Keep the defaults for the Environments.
- Click Run.
- Compare the output file to the original shapefile from the same time period to make sure the tool worked as expected. Notice the records that have an FID_Study_ value of -1. What do these mean? Hint: See step vi.
- Repeat union for the remaining two vegetation shapefiles “70s_Join” and “00s_Join.” Name them “70s_Union” and “00s_Union.”

Geodatabases may have naming restrictions for table and field names. For instance, a table in a file geodatabase cannot start with a number or a special character such as an asterisk (*) or percent sign (%). Shapefiles do not have such restrictions and allow us to use names such as 60s_Join.
If you receive an Error 000361: The name starts with an invalid character during geoprocessing, check to make sure you are saving your output as a shapefile.
It’s very easy to make mistakes when using geoprocessing tools. For example, you can select the wrong input files by mistake. Another common error is running tools while unknowingly having records selected. Any output from geoprocessing tools will only contain the selected records. Comparing your results with your input datasets after using automated tools is a good habitat to get into.
If you want to double-check the input files you used previously, the parameter settings, environment settings, etc., you can view them under Geoprocessing > History.
Make sure you have the correct answer before moving on to the next step.
- 60s_Union should have 367 records
- 70s_Union should have 289 records
- 00s_Union should have 458 records
If your data does not match this, go back and redo the previous step.
-
Modify Extents - Remove Excess Area
- Notice that some of the study years still cover a larger area than others. For example, compare the 60s_Union shapefile with the 70s_Union shapefile. Let’s change the extent of all data sources to match the study area boundary by using the clip tool. Note: The Clip tool is only for vector datasets. In later lessons, we will look at tools to clip raster datasets.
- Go to the Analysis tab, Tools group > Clip

- Click on the “Show Help” button for more information about what the tool does and what the different input criteria mean.
- Input Features: 60s_Union.
- Clip Features: Study_Site.
- Output Feature Class: 60s_Species.shp (save it in your L3 folder).
- Keep the defaults for Environments.
- Click Run.
- Go to the Analysis tab, Tools group > Clip
- Compare the output file to the joined shapefile and unioned shapefile from the same time period. What differences do you notice?
- Clip 70s_Union and 00s_Union using the directions above. Name them “70s_Species” and “00s_Species.”
Make sure you have the correct answer before moving on to the next step.
- 60s_Species should have 240 records
- 70s_Species should have 206 records
- 00s_Species should have 325 records
If your data does not match this, go back and redo the previous step.
- Remove the original vegetation, unioned, and joined shapefiles from your map and save the project.
- All of our study years should now have the same extent. Let’s confirm this by calculating the area of each study year. Add a new double field
 to each year called “sqm” with the default scale and precision values. I find it helpful to name fields by their units so I remember what they mean later on. Remember to
to each year called “sqm” with the default scale and precision values. I find it helpful to name fields by their units so I remember what they mean later on. Remember to  your changes.
your changes.
Specifying a specific precision and scale when adding a field to a shapefile gives you the option to limit the number of digits (precision) and decimal places (scale) of values within number fields. There are many situations where you would want to do this. However, there are also occasions where it is best to keep all of your options open. Accepting the default value of 0 for both properties gives you the most versatility. It may seem counterintuitive, but the value of 0 acts somewhat similar to the value of infinity in this case. Setting custom precision and scale values is only relevant to data stored in an enterprise geodatabase. Default values are always enforced when editing data in a shapefile or file geodatabase. Refer to the ArcGIS field data types for more information.
I recommend using values of 0 when you are in the preliminary stages of data exploration. That way you won’t unknowingly exclude values in your results. For example, if you are calculating area values for the first time, you probably won’t know how many digits you will need to store your calculated values (precision) until after you’ve made the calculation. If you estimate a number to use for precision that ends up being too low, you will not be able to store the full range of values. For example, a precision of 2 would limit your values to two digits, whereas a precision of 4 would limit your values to four digits.
- In the open attribute table, right-click on the “sqm” field and click Calculate Geometry. Choose area and units of square meters. Use the coordinate system of the data source. Repeat this step for the remaining two shapefiles.
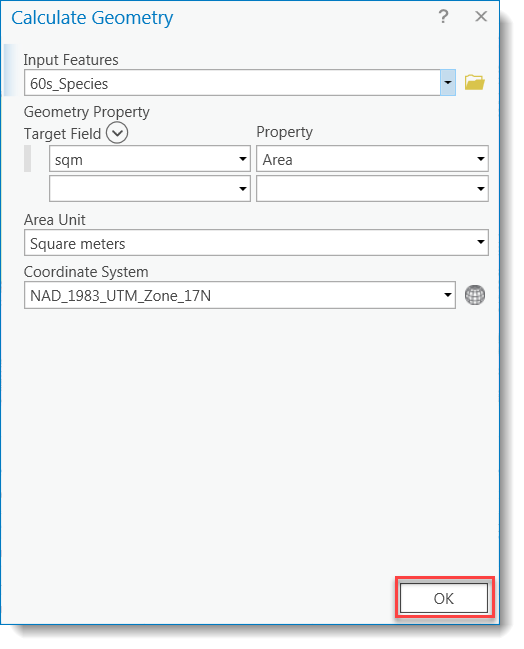 Calculate Geometry
Calculate Geometry - Use the statistics tool to find the total area for each year by right-clicking on the “sqm” field and choosing “Statistics”. All of the study years should have the same “SUM” value. You may notice very small differences between the layers. This is due to tiny topology errors such as overlapping sliver polygons. We could have corrected these with the Environments > XY Tolerance settings during our union and clip operations if we needed this level of precision for our analysis. In this case, we don’t, but I wanted to point out this issue in case you come across it in other projects. For more information about XY Tolerance, see the Esri Help.
- Notice that some of the study years still cover a larger area than others. For example, compare the 60s_Union shapefile with the 70s_Union shapefile. Let’s change the extent of all data sources to match the study area boundary by using the clip tool. Note: The Clip tool is only for vector datasets. In later lessons, we will look at tools to clip raster datasets.
-
Explore Attributes & Missing Data
- Now that we’ve fixed the geometry of our input data, we can start to work with the attributes. Before inputting data into an analysis, you should have a good understanding of the distribution of your values. You should also be aware of any missing values or outliers that can skew your results, so you can exclude or recode these if necessary.
- One way to quickly get a sense of the distribution of data values and missing data is to change the symbology to be categorical based on each attribute.
- Right-click on the 60s_Species shapefile in the Contents pane > Symbology. The Symbology pane will open to the right. Under Primary symbology > Unique values > Field 1 Veg_Type.
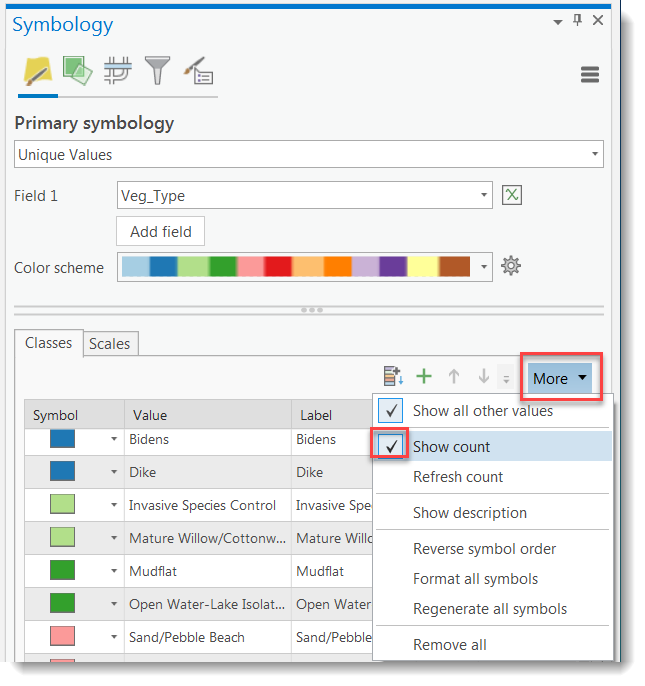 Symbology pane
Symbology pane - Expand the More dropdown list and click on Show Count. How many polygons have missing data (blank entry) in the “Value” column? Do you see any values with typos?
- Repeat this process for the “Veg_Group” and “Invasive” variables.
- Repeat steps c and d for the remaining two time periods (“70s_Species” and “00s_Species”).
-
Generalize Data
- For our analysis, we are particularly interested in two attributes, “Veg_Group” and “Invasive.” Right now, each polygon represents vegetation clusters of the same species, which is more detailed than we need. We want to create two new data sets in which the polygons represent clusters of vegetation groups and clusters of invasive types over time. We will use these customized data sets in Lesson 4, where we will discuss how to interpret and present results from several datasets.
- First, let’s create the time series shapefiles of vegetation groups.
- Go to the Analysis tab, Geoprocessing group > Tools
 .
. - In the Geoprocessing pane, search for "Dissolve".
- Click on the “Show Help” button for more information about what the tool does and what the different input criteria mean.
- Input Features: 60s_Species.
- Output Feature Class: 60s_VegGrp.shp (save it in your L3 folder, not the default.gdb).
- Dissolve Field: Veg_Group.
- Statistics Field: Select “sqm” as the field and “SUM” as the statistics type.
- “Create multipart features” should be checked.
- “Unsplit lines” should NOT be checked.
- Go to the Analysis tab, Geoprocessing group > Tools
- Compare the output file to the input file from the same time period.
- Repeat the dissolve for the remaining two time periods. Name them “70s_VegGrp” and “00s_VegGrp.”
Summary Statistics tool (go to the Analysis tab, Geoprocessing group >Tools
> search "Summary_Statistics") is another option you can use to calculate statistics for your data. This tool is similar to the “Summarize” option available by right clicking on a field in an attribute table. The advantage of the Summary Statistics tool is that it allows you to create statistics based on multiple fields. For example, you could use it to find the total area for every unique combination of vegetation type and invasive classification. You could interpret the results to find out which plant type makes up the majority of invasive species for each time period.Multipart polygons are features that have more than one polygon for each row in the attribute table. If you want to explode these into individual records at a later time, there is a tool available on the Edit tab, in the Tools group.
- Now, let’s create the time series shapefiles by invasive type.
- Go to the Analysis tab, Geoprocessing group > Tools.
- In the Geoprocessing pane, search for "Dissolve".
- Input Features: 60s_Species.
- Output Feature Class: 60s_Invasive.shp (save it in your L3 folder).
- Dissolve Field: Invasive.
- Statistics Field: Select “sqm” as the field and “SUM” as the Statistics Type.
- “Create multipart features” should be checked.
- “Unsplit lines” should NOT be checked.
- Go to the Analysis tab, Geoprocessing group > Tools.
- Compare the output file to the input file from the same time period.
- Repeat step c for the remaining two time periods. Name the output files “70s_Invasive” and “00s_Invasive.”
- Remove the “60s_Species,” “70s_Species,” and “00s_Species” from your map and save.
That’s it for the required portion of the Lesson 3 Step-by-Step Activity. Please consult the Lesson Checklist for instructions on what to do next.

After experimenting with online data services in Lesson 2 and raw data in Lesson 3, which do you think is easier to work with? What are the pros and cons of each one? Can you think of any scenarios in which one is preferable over the over?
Do you have a good understanding of why we completed each step in Part II? If not, compare the starting vegetation files and final outputs (XX_Species, XX_VegGrp, XX_Invasive) in terms of extent, area, gaps, spatial detail, and attributes.
Try This!
- In Lesson 3, we familiarized ourselves with the study site using the “Open Street Map” layer from Esri. Google Earth Pro is another excellent application for this purpose. If you are willing to install the software, try one or more of the activities listed below.
- Open the KMZ file of the Study Area (in the L3 Data folder) in Google Earth, zoom to the study boundary, and explore the area around the study site. For example, look for Street View images or other sources of imagery (Layers > More > DigitalGlobe Coverage). If you receive an error message by double-clicking directly on the KMZ file from Windows Explorer, open the file from within Google Earth > File > Open > Study_Boundary.kmz. You can also right-click on the KMZ file from your desktop > Opens With > Google Earth.
- Experiment with the “view historical imagery” tool by clicking on the clock icon to see if you can find these. How far back in time do the images go?

- Explore Great Lakes Phragmites Collaborative. Can you find any other Phragmites projects along the Lake Erie shoreline?
Note: Try This! Activities are voluntary and are not graded, though I encourage you to complete the activity and share comments about your experience on the lesson discussion board.