1.6.5 First steps with Multiprocessing
From the brief description in the previous section, you might have realized that there are generally two broad types of tasks – those that are input/output (I/O) heavy which require a lot of data to be read, written or otherwise moved around; and those that are CPU (or processor) heavy that require a lot of calculations to be done. Because getting data is the slowest part of our operation, I/O heavy tasks do not demonstrate the same improvement in performance from multiprocessing as CPU heavy tasks. The more work there is to do for the CPU the greater the benefit in splitting that workload among a range of processors so that they can share the load.
The other thing that can slow us down is outputting to the screen – although this isn’t really an issue in multiprocessing because printing to our output window can get messy. Think about two print statements executing at exactly the same time – you’re likely to get the content of both intermingled, leading to a very difficult to understand message. Even so, updating the screen with print statements is a slow task.
Don’t believe me? Try this sample piece of code that sums the numbers from 0-100.
# Setup _very_ simple timing.
import time
start_time = time.time()
sum = 0
for i in range(0,100):
sum += i
print(sum)
# Output how long the process took.
print ("--- %s seconds ---" % (time.time() - start_time))
If I run it with the print function in the loop the code takes 0.049 seconds to run on my PC. If I comment that print function out, the code runs in 0.0009 seconds.
4278
4371
4465
4560
4656
4753
4851
4950
--- 0.04900026321411133 seconds ---
runfile('C:/Users/jao160/Documents/Teaching_PSU/Geog489_SU_21/Lesson 1/untitled1.py', wdir='C:/Users/jao160/Documents/Teaching_PSU/Geog489_SU_21/Lesson 1')
--- 0.0009996891021728516 seconds ---
In Penn State's GEOG 485 course, we simulated 10,000 runs of the children's game Cherry-O to determine the average number of turns it takes. If we printed out the results, the code took a minute or more to run. If we skipped all but the final print statement the code ran in less than a second. We’ll revisit that Cherry-O example as we experiment with moving code from the single processor paradigm to multiprocessor. We’ll start with it as a simple, non arcpy example and then move on to two arcpy examples – one raster (our raster calculation example from before) and one vector.
Since you most likely did not take GEOG 485, you may want to have a quick look at the description [1].
Following is the original Cherry-O code.
# Simulates 10K game of Hi Ho! Cherry-O
# Setup _very_ simple timing.
import time
start_time = time.time()
import random
spinnerChoices = [-1, -2, -3, -4, 2, 2, 10]
turns = 0
totalTurns = 0
cherriesOnTree = 10
games = 0
while games < 10001:
# Take a turn as long as you have more than 0 cherries
cherriesOnTree = 10
turns = 0
while cherriesOnTree > 0:
# Spin the spinner
spinIndex = random.randrange(0, 7)
spinResult = spinnerChoices[spinIndex]
# Print the spin result
# print ("You spun " + str(spinResult) + ".")
# Add or remove cherries based on the result
cherriesOnTree += spinResult
# Make sure the number of cherries is between 0 and 10
if cherriesOnTree > 10:
cherriesOnTree = 10
elif cherriesOnTree < 0:
cherriesOnTree = 0
# Print the number of cherries on the tree
# print ("You have " + str(cherriesOnTree) + " cherries on your tree.")
turns += 1
# Print the number of turns it took to win the game
# print ("It took you " + str(turns) + " turns to win the game.")
games += 1
totalTurns += turns
print("totalTurns " + str(float(totalTurns) / games))
# lastline = raw_input(">")
# Output how long the process took.
print("--- %s seconds ---" % (time.time() - start_time))
We've added in our very simple timing from earlier and this example runs for me in about 1/3 of a second (without the intermediate print functions). That is reasonably fast and you might think we won't see a significant improvement from modifying the code to use multiprocessor mode but let's experiment.
The Cherry-O task is a good example of a CPU bound task; we’re limited only by the calculation speed of our random numbers, as there is no I/O being performed. It is also an embarrassingly parallel task as none of the 10,000 runs of the game are dependent on each other. All we need to know is the average number of turns; there is no need to share any other information. Our logic here could be to have a function (Cherry-O) which plays the game and returns to our calling function the number of turns. We can add that value returned to a variable in the calling function and when we’re done divide by the number of games (e.g. 10,000) and we’ll have our average.
1.6.5.1 Converting from sequential to multiprocessing
So with that in mind, let us examine how we can convert a simple program like Cherry-O from sequential to multiprocessing.
There are a couple of basic steps we need to add to our code in order to support multiprocessing. The first is that our code needs to import multiprocessing which is a Python library which as you will have guessed from the name enables multiprocessing support. We’ll add that as the first line of our code.
The second thing our code needs to have is a __main__ method defined. We’ll add that into our code at the very bottom with:
if __name__ == '__main__':
mp_handler()
With this, we make sure that the code in the body of the if-statement is only executed for the main process we start by running our script file in Python, not the subprocesses we will create when using multiprocessing, which also are loading this file. Otherwise, this would result in an infinite creation of subprocesses, subsubprocesses, and so on. Next, we need to have that mp_handler() function we are calling defined. This is the function that will set up our pool of processors and also assign (map) each of our tasks onto a worker (usually a processor) in that pool.
Our mp_handler() function is very simple. It has two main lines of code based on the multiprocessing module:
The first instantiates a pool with a number of workers (usually our number of processors or a number slightly less than our number of processors). There’s a function to determine how many processors we have, multiprocessing.cpu_count(), so that our code can take full advantage of whichever machine it is running on. That first line is:
with multiprocessing.Pool(multiprocessing.cpu_count()) as myPool: ... # code for setting up the pool of jobs
You have probably already seen this notation from working with arcpy cursors. This with ... as ... statement creates an object of the Pool class defined in the multiprocessing module and assigns it to variable myPool. The parameter given to it is the number of processors on my machine (which is the value that multiprocessing.cpu_count() is returning), so here we are making sure that all processor cores will be used. All code that uses the variable myPool (e.g., for setting up the pool of multiprocessing jobs) now needs to be indented relative to the "with" and the construct makes sure that everything is cleaned up afterwards. The same could be achieved with the following lines of code:
myPool = multiprocessing.Pool(multiprocessing.cpu_count()) ... # code for setting up the pool of jobs myPool.close() myPool.join()
Here the Pool variable is created without the with ... as ... statement. As a result, the statements in the last two lines are needed for telling Python that we are done adding jobs to the pool and for cleaning up all sub-processes when we are done to free up resources. We prefer to use the version using the with ... as ... construct in this course.
The next line that we need in our code after the with ... as ... line is for adding tasks (also called jobs) to that pool:
res = myPool.map(cherryO, range(10000))
What we have here is the name of another function, cherryO(), which is going to be doing the work of running a single game and returning the number of turns as the result. The second parameter given to map() contains the parameters that should be given to the calls of thecherryO() function as a simple list. So this is how we are passing data to process to the worker function in a multiprocessing application. In this case, the worker function cherryO() does not really need any input data to work with. What we are providing is simply the number of the game this call of the function is for, so we use the range from 0-9,999 for this. That means we will have to introduce a parameter into the definiton of the cherryO() function for playing a single game. While the function will not make any use of this parameter, the number of elements in the list (10000 in this case) will determine how many timescherryO() will be run in our multiprocessing pool and, hence, how many games will be played to determine the average number of turns. In the final version, we will replace the hard-coded number by a variable called numGames. Later in this part of the lesson, we will show you how you can use a different function called starmap(...) instead of map(...) that works for worker functions that do take more than one argument so that we can pass different parameters to it.
Python will now run the pool of calls of the cherryO() worker function by distributing them over the number of cores that we provided when creating the Pool object. The returned results, so the number of turns for each game played, will be collected in a single list and we store this list in variable res. We’ll average those turns per game to get an average using the Python library statistics and the function mean().
To prepare for the multiprocessing version, we’ll take our Cherry-O code from before and make a couple of small changes. We’ll define function cherryO() around this code (taking the game number as parameter as explained above) and we’ll remove the while loop that currently executes the code 10,000 times (our map range above will take care of that) and we’ll therefore need to “dedent“ the code.
Here’s what our revised function will look like :
def cherryO(game):
spinnerChoices = [-1, -2, -3, -4, 2, 2, 10]
turns = 0
cherriesOnTree = 10
# Take a turn as long as you have more than 0 cherries
while cherriesOnTree > 0:
# Spin the spinner
spinIndex = random.randrange(0, 7)
spinResult = spinnerChoices[spinIndex]
# Print the spin result
#print ("You spun " + str(spinResult) + ".")
# Add or remove cherries based on the result
cherriesOnTree += spinResult
# Make sure the number of cherries is between 0 and 10
if cherriesOnTree > 10:
cherriesOnTree = 10
elif cherriesOnTree < 0:
cherriesOnTree = 0
# Print the number of cherries on the tree
#print ("You have " + str(cherriesOnTree) + " cherries on your tree.")
turns += 1
# return the number of turns it took to win the game
return(turns)
1.6.5.2 Putting it all together
Now lets put it all together. We’ve made a couple of other changes to our code to define a variable at the very top called numGames = 10000 to define the size of our range.
# Simulates 10K game of Hi Ho! Cherry-O
# Setup _very_ simple timing.
import time
start_time = time.time()
import multiprocessing
from statistics import mean
import random
numGames = 10000
def cherryO(game):
spinnerChoices = [-1, -2, -3, -4, 2, 2, 10]
turns = 0
cherriesOnTree = 10
# Take a turn as long as you have more than 0 cherries
while cherriesOnTree > 0:
# Spin the spinner
spinIndex = random.randrange(0, 7)
spinResult = spinnerChoices[spinIndex]
# Print the spin result
#print ("You spun " + str(spinResult) + ".")
# Add or remove cherries based on the result
cherriesOnTree += spinResult
# Make sure the number of cherries is between 0 and 10
if cherriesOnTree > 10:
cherriesOnTree = 10
elif cherriesOnTree < 0:
cherriesOnTree = 0
# Print the number of cherries on the tree
#print ("You have " + str(cherriesOnTree) + " cherries on your tree.")
turns += 1
# return the number of turns it took to win the game
return(turns)
def mp_handler():
with multiprocessing.Pool(multiprocessing.cpu_count()) as myPool:
## The Map function part of the MapReduce is on the right of the = and the Reduce part on the left where we are aggregating the results to a list.
turns = myPool.map(cherryO,range(numGames))
# Uncomment this line to print out the list of total turns (but note this will slow down your code's execution)
#print(turns)
# Use the statistics library function mean() to calculate the mean of turns
print(mean(turns))
if __name__ == '__main__':
mp_handler()
# Output how long the process took.
print ("--- %s seconds ---" % (time.time() - start_time))
You will also see that we have the list of results returned on the left side of the = before our map function (line 40). We’re taking all of the returned results and putting them into a list called turns (feel free to add a print or type statement here to check that it's a list). Once all of the workers have finished playing the games, we will use the Python library statistics function mean, which we imported at the very top of our code (right after multiprocessing) to calculate the mean of our list in variable turns. The call to mean() will act as our reduce as it takes our list and returns the single value that we're really interested in.
When you have finished writing the code in spyder, you can run it. However, it is important to know that there are some well-documented problems with running multiprocessing code directly in spyder. You may only experience these issues with the more complicated arcpy based examples in Section 1.6.6 but we recommend that you run all multiprocessing examples from the command line rather than inside spyder.
The Windows command line and its commands have already been explained in Section 1.6.2 but since this was an optional section, we are repeating the explanation here: Use the shortcut called "Python command prompt" that can be found within the ArcGIS program group on the start menu. This will open a command window running within the Pro conda environment indicating that this is Python 3 (py3). You actually may have several shortcuts with rather similar sounding names, e.g. if you have both ArcGIS Pro and ArcGIS Desktop installed, and it is important that you pick the right one from ArcGIS Pro that mentions Python 3. The prompt will tell you that you are in the folder C:\Users\<username>\AppData\Local\ESRI\conda\envs\arcgispro-py3-clone\ or C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\ depending on your version of ArcGIS Pro.
We could dedicate an entire class to operating system commands that you can use in the command window but Microsoft has a good resource at this Windows Commands page [2] for those who are interested.
We just need a couple of the commands listed there :
- cd : change directory. We use this to move around our folders. Full help at this Commands/cd page [3].
- dir : list the files and folders in my directory. Full help at this Commands/dir page [4].
We’ll change the directory to where we saved the code from above (e.g. mine is in c:\489\lesson1) with the following command:
cd c:\489\lesson1
Before you run the code for the first time, we suggest you change the number of games to a much smaller number (e.g. 5 or 10) just to check everything is working fine so you don’t spawn 10,000 Python instances that you need to kill off. In the event that something does go horribly wrong with your multiprocessing code, see the information about the Windows taskkill command below. To now run the Cherry-O script (which we saved under the name cherry-o.py) in the command window, we use the command:
python cherry-o.py
You should now get the output from the different print statements, in particular the average number of turns and the time it took to run the script. If everything went ok, set the number of games back to 10000 and run the script again.
It is useful to know that there is a Windows command that can kill off all of your Python processes quickly and easily. Imagine having to open Task Manager and manually kill them off, answer a prompt and then move to the next one! The easiest way to access the command is by pressing your Windows key, typing taskkill /im python.exe and hitting Enter which will kill off every task called python.exe. It’s important to only use this when absolutely necessary as it will usually also stop your IDE from running and any other Python processes that are legitimately running in the background. The full help for taskkill is at the Microsoft Windows IT Pro Center taskkill page [5].
Look closely at the images below, which show a four processor PC running the sequential and multiprocessing versions of the Cherry-O code. In the sequential version, you’ll see that the CPU usage is relatively low (around 50%) and there are two instances of Python running (one for the code and (at least) one for spyder).
In the multiprocessing version, the code was run from the command line instead (which is why it’s sitting within a Windows Command Processor task) and you can see the CPU usage is pegged at 100% as all of the processors are working as hard as they can and there are five instances of Python running.
This might seem odd as there are only four processors, so what is that extra instance doing? Four of the Python instances, the ones all working hard, are the workers, the fifth one that isn’t working hard is the master process which launched the workers – it is waiting for the results to come back from the workers. There isn’t another Python instance for spyder because I ran the code from the command prompt – therefore spyder wasn’t running. We'll cover running code from the command prompt in the Profiling [6]section.
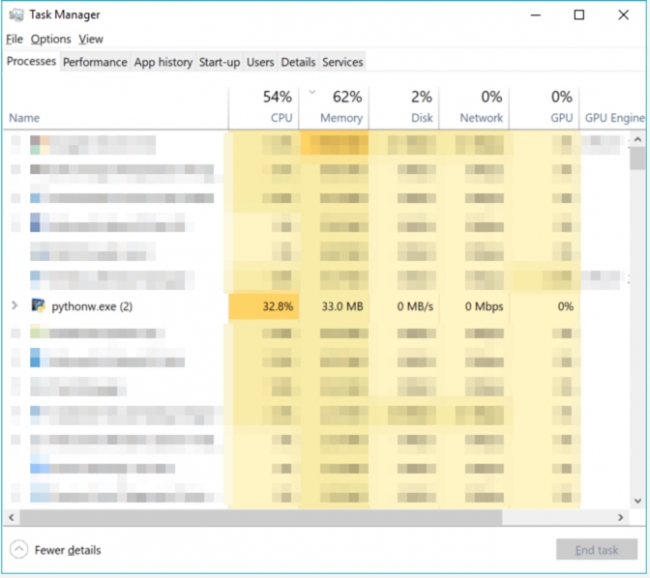
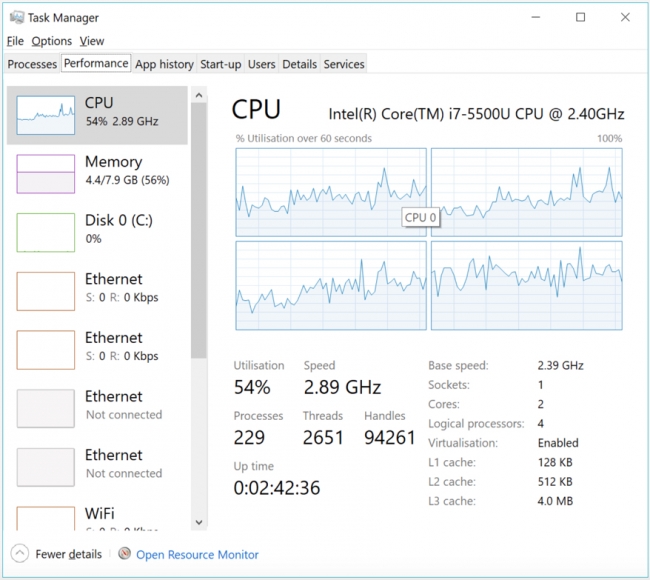
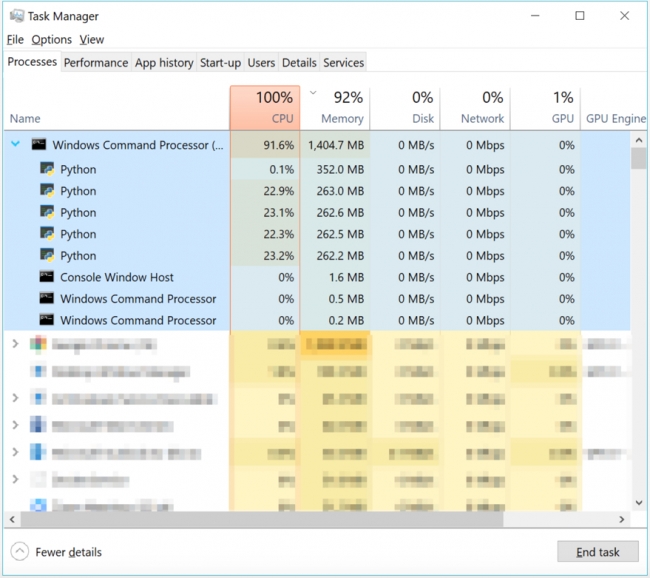
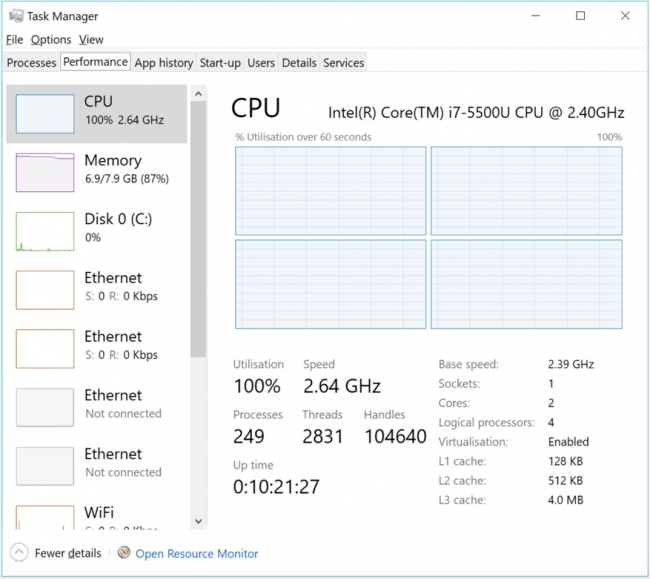
On this four processor PC, this code runs in about 1 second and returns an answer of between 15 and 16. That is about three times slower than my sequential version which ran in 1/3 of a second. If instead I play 1M games instead of 10K games, the parallel version takes 20 seconds on average and my sequential version takes on average 52 seconds. If I run the game 100M times, the parallel version takes around 1,600 seconds (26 minutes) while the sequential version takes 2,646 seconds (44 minutes). The more games I play, the better the performance of the parallel version. Those results aren’t as fast as you might expect with 4 processors in the multiprocessor version but it is still around half the time taken. When we look at profiling our code a bit later in this lesson, we’ll examine why this code isn’t running 4x faster.
When moving the code to a much more powerful PC with 32 processors, there is a much more significant performance improvement. The parallel version plays 100M games in 273 seconds (< 5 minutes) while the sequential version takes 3136 seconds (52 minutes) which is about 11 times slower. Below you can see what the task manager looks like for the 32 core PC in sequential and multiprocessing mode. In sequential mode, only one of the processors is working hard – in the middle of the third row – while the others are either idle or doing the occasional, unrelated background task. It is a different story for the multiprocessor mode where the cores are all running at 100%. The spike you can see from 0 is when the code was started.
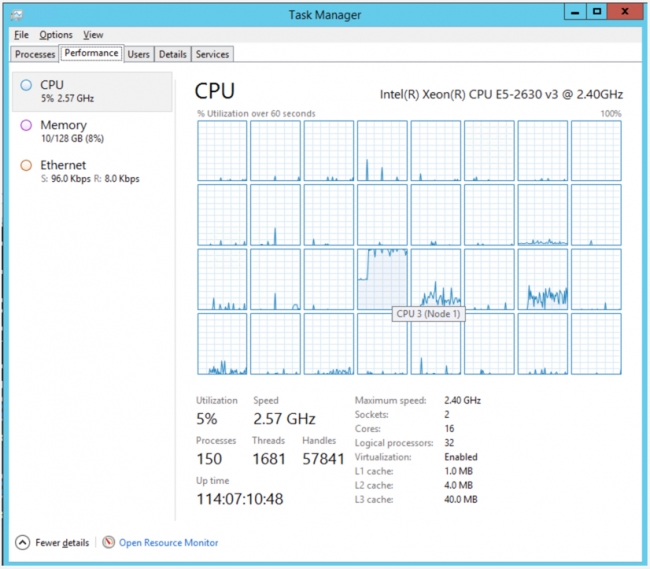
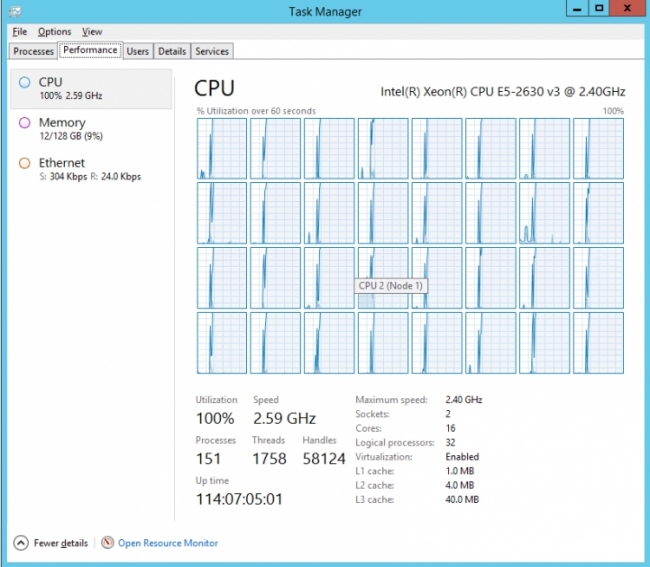
Let's examine some of the reasons for these speed differences. The 4-processor PC’s CPU runs at 3GHz while the 32-processor PC runs at 2.4GHz; the extra cycles that the 4-processor CPU can perform per second make it a little quicker at math. The reason the multiprocessor code runs much faster on the 32-processor PC than the 4-processor PC is straightforward enough –- there are 8 times as many processors (although it isn’t 8 times faster – but it is close at 6.4x (32 min / 5 min)). So while each individual processor is a little slower on the larger PC, because there are so many more, it catches up (but not quite to 8x faster due to each processor being a little slower).
Memory quantity isn’t really an issue here as the numbers being calculated are very small but if we were doing bigger operations, the 4-processor PC with just 8GB of RAM would be slower than the 32-processor PC with 128GB. The memory in the 32-processor PC is also faster at 2.13 GHz versus 1.6GHz in the 4-processor PC.
So the takeaway message here is if you have a lot of tasks that are largely the same but independent of each other, you can save a significant amount of time utilizing all of the resources within your PC with the help of multiprocessing. The more powerful the PC, the more time that can potentially be saved. However, the caveat is that as already noted multiprocessing is generally only faster for CPU-bound processes, not I/O-bound ones.