In the previous lesson, you learned that system architectures for web mapping include a data tier. This could be as simple as several shapefiles sitting in a folder on your server machine, or it could be as complex as several enterprise-grade servers housing an ecosystem of standalone files and relational databases. Indeed, in our system architecture diagram, I have represented the data tier as containing a file server and a database server.
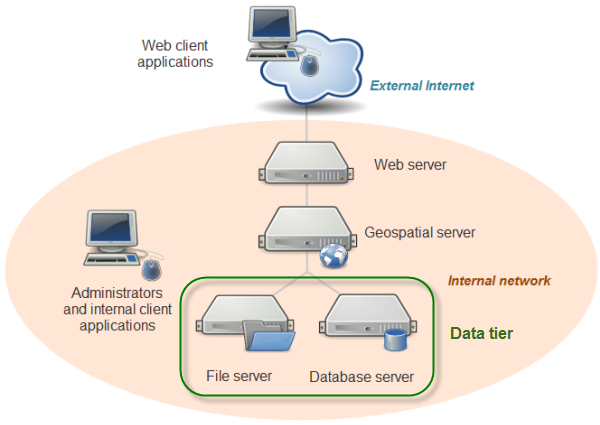
The data tier contains your datasets that will be included in the web map. Almost certainly, it will house the data for your thematic web map layers. It may also hold the data for your basemap layers, if you decide to create your own basemap and tile sets. Other times, you will pull in basemaps, and quite possibly some thematic layers, from other peoples' servers, relieving yourself of the burden of maintaining the data.
Some organizations are uneasy with the idea of taking the same database that they use for day-to-day editing and putting it on the web. There is justification for this uneasiness, for both security and performance reasons. If you are allowing web map users to modify items in the database, you want to avoid the possibility of your data being deleted, corrupted, or sabotaged. Also, you don't want web users' activities to tax the database so intensely that performance becomes slow for your own internal GIS users, and vice versa.
For these reasons, organizations will often create a copy or replica of their database and designate it solely for web use. If features in the web map are not designed to be edited by end users, this copy of the database is read-only. If, on the other hand, web users will be making edits to the database, it is periodically synchronized with the internal "production" database using automated scripts or web services. A quality assurance (QA) step can be inserted before synchronization if you would prefer for a GIS analyst to examine the web edits before committing them to the production database.
Where to put the data? On the server or its own machine?
You can generally increase web map performance by minimizing the number of "hops" between machines that your data has to take before it reaches the end user. If your data is file-based or is stored in a very simple database, you may just be able to store a copy of it directly on the machine that hosts your geospatial web services, thereby eliminating network traffic between the geospatial server and a data server. However, if you have a large amount of data, or a database with a large number of users, it may be best to keep the database on its own machine. Isolating the database onto its own hardware allows you to use more focused backup and security processes, as well as redundant storage mechanisms to mitigate data loss and corruption. It also helps prevent the database and the server competing for resources when either of these components is being accessed by many concurrent users.
If you choose to house your data on a machine separate from the server, you need to ensure that firewalls allow communication between the machines on all necessary ports. This may involve consulting your IT staff (bake them cookies, if necessary). You may also need to ensure that the system process running your web service is permitted to read the data from the other machine. Finally, you cannot use local paths such as C:\data\Japan to refer to the dataset; you must use the network name of the machine in a shared path; for example, \\dataserver\data\Japan.
Files vs. databases
When designing your data tier, you will need to decide whether to store your data in a series of simple files (such as shapefiles or KML) or in a database that incorporates spatial data support (such as PostGIS or SpatiaLite). A file-based data approach is simpler and easier to set up than a database if your datasets are not changing on a frequent basis and are of manageable size. File-based datasets can also be easier to transfer and share between users and machines.
Databases are more appropriate when you have a lot of data to store, the data is being edited frequently by different parties, you need to allow different tiers of security privileges, or you are maintaining relational tables to link datasets. Databases can also offer powerful native options for running SQL queries and calculating spatial relationships (such as intersections).
If you have a long-running GIS project housed in a database, and you just now decided to expose it on the web, you'll need to decide whether to keep the data in the database or extract copies of the data into file-based datasets.
Open data formats and proprietary formats
To review a key point from the previous section, in this course, we will be using open data formats, in other words, formats that are openly documented and have no legal restrictions or royalty requirements on their creation and use by any software package. You are likely familiar with many of these, such as shapefiles, KML files, JPEGs, and so forth. In contrast, proprietary data formats are created by a particular software vendor and are either undocumented or cannot legally be created from scratch or extended by any other developer. The Esri file geodatabase is an example of a well-known proprietary format. Although Esri has released an API for creating file geodatabases, the underlying format cannot be extended or reverse engineered.
Some of the most widely-used open data formats were actually designed by proprietary software vendors, who made the deliberate decision to release them as open formats. Two examples are the Esri shapefile and the Adobe PDF. Although opening a data format introduces the risk that FOSS alternatives will compete with the vendor's functionality, it increases the interoperability of the vendor's software, and, if uptake is widespread, augments the vendor's clout and credibility within the software community.