Digital Image Classification is an information extraction process (machine or automated interpretation) that involves the application of pattern recognition theory to multispectral imagery. It analyzes spectral properties of various surface features (e.g., crops) in a multiband image and sorts spectral data into spectrally related categories by the use of predefined, numerical decision rules.
The process involves:
- Categorizing images into different surface materials or conditions
- Collection of spectral signatures for specific surface materials
- Based upon spectral response
- Assumes unique spectral signatures exist for land covers
- Trains the computer to recognize those spectral signatures
- Statistical operation
- No direct site or situation information
- Does not rely on visual interpretation
- Not necessarily more accurate or objective than visual interpretation
- Someone must decide the classes and whether signatures are accurate or not
- Signature extraction
- Unsupervised classification using statistics or clustering algorithm
- Supervised classification using training sites
- Poor signatures lead to poor results
- Possibly stratify broad classes first
- Classify the imagery
- Spatial filtering for GIS compatibility
- Accuracy assessment
The process utilizes one or more of the following recognition types:
- Spectral pattern recognition: When decision rules are based on spectral radiance characteristics of the scene.
- Spatial pattern recognition: When decision rules are based on geometric characteristics of the scene (i.e. shape, size, patterns)
- Temporal pattern recognition: uses time as an aid in feature identification
- Object-oriented classification: involve combined use of both spectral and spatial recognition
Among the difficulties usually encountered with this technique are the following:
-
- Signature is not unique for given sensor characteristics
- Signature too unique
- Same cover type but with distinct differences
- Soil moisture, surface material, atmospheric conditions
- Same cover type but with distinct differences
- Mixed pixels
- Signature extension issue (over space and time)
There are two types of image classification algorithms, those are:
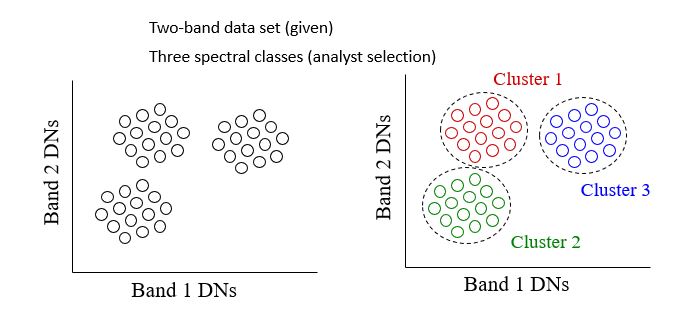
- Unsupervised Classification: uses an automatic clustering algorithm that analyzes the “unknown” pixels in the database and divide them into several spectrally distinct classes based upon their natural grouping or clusters.
In the unsupervised process, a user directs a computer software package to automatically identify and categorize pixels in an image. This is done on a purely statistical basis, though the user has control over the number of statistical classes, or clusters, to be created. With different classification algorithms, the user will also have control over statistical parameters, such as how much variation is permitted in a single class.
While there are no set rules on how many classes should be defined, a general rule of thumb is that the classes should total three times the number of final land cover categories sought. This allows for the possibility of different spectral signatures pertaining to the same land cover type (for example, if forest is sought as a class, deciduous and coniferous forests may require more than one spectral signature to accurately categorize them as forest). A number of these classes will likely represent meaningless categories or mixed pixels that may then be thrown out at a later point in the process.
Once a set of signatures has been defined, they may then be used to classify the entire image. Pixels with statistical characteristics similar to those in the signature set will be assigned the appropriate class. The resulting thematic layer has every pixel assigned a value representing the signature it was determined to be best represented by, Figure 8.1. This data set is then evaluated by the user to determine what land cover type is represented.
Processing Steps:
a - clustering or grouping
b – coloring
c – identification
Advantages and Disadvantages of Unsupervised Classification
Pros:
+ no extensive prior knowledge of the region required
+ opportunities for human error minimized
+ unique classes are recognized as distinct units
+ logistically less cumbersome
Cons:
- natural groupings do not necessarily correspond nicely with desired information classes
- no control over the menu of classes and their specific id
- spectral properties of informational classes vary over time, relationships between information and spectral classes change - make it difficult to compare unsupervised
classes from one image/date to another
- Supervised Classification: The process of using samples of known informational classes (training sets) to classify pixels of unknown identity. Identification and delineation of training areas is key to successful implementation. The basic strategy in using supervised classification is to sample areas of known cover types to determine representative spectral values of each cover type. Such samples are called training areas or training fields, Figure Training fields or spectral signatures are established from homogeneous cover type areas through:
- Map digitizing - transfer photo information to base map (use table digitizer)
- On-screen digitizing, Figure 8.2
- Seed-pixel approach
The main steps in supervised classification are the following:
- Training Class Selection
- Generation of statistical parameters to train the classification algorithm, such as:
- class means
- standard deviations
- covariance matrices
- correlation matrices
- Data Classification: Assigning each pixel of the data to one of the training class
- Evaluation and Refinement
- Documentation: Maps and tabular summaries
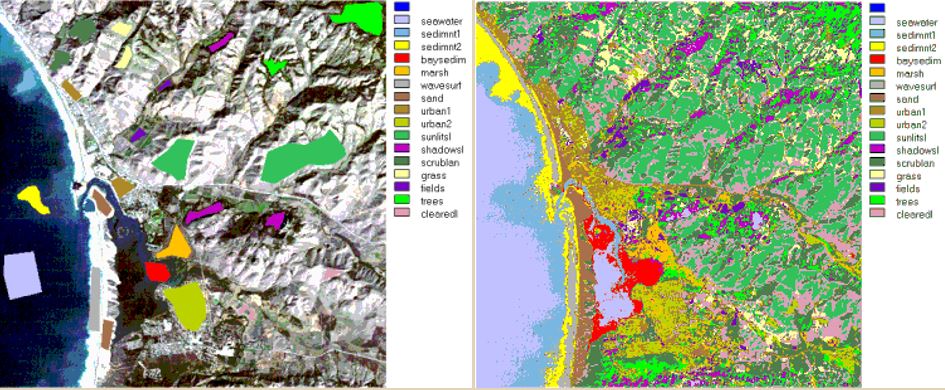
Figure 8.2 Left: Training samples Right: Supervised Classification on an image
Additional Remarks:
- With supervised classification, the process relies on user input to identify areas of specific cover types and to apply a classification algorithm that then utilizes that information to find the same cover type in other regions of the image. This process often involves having specific information on ground conditions collected through fieldwork or through high-resolution imagery/aerial photography. The sites of interest are referred to as training or calibration sites. Essentially, those portions of the image that will be used to identify other portions of the image with similar characteristics. A second set of “known” sites may be reserved for use in accuracy assessment. These are often referred to as calibration or truth sites.
- Statistics for training sites are used to define a spectral signature for specific cover types of interest. A range of supervised classification processes exist but the Maximum Likelihood classifier is one of the most common.
- Each pixel in an image is compared to the statistics compiled for the different signatures. The classification algorithm determines on a probability basis the likelihood that any given pixel should be assigned to any given class. The class providing the highest likelihood is the one that the pixel is assigned to.
Good Strategy for Supervised Classification
- Number of pixels - want to statistically characterize the spectral properties of an informational class (i.e. forest, crop, water), should have >= 100 pixels total for an informational class
- Location - geographically dispersed, boundaries away from edge/mixed pixels number of areas - depends on the number of information categories, 10 at a minimum, enough for accuracy assessment and incorporation of spectral subclasses
- Uniformity - unimodal distributions, use training areas to characterize mean, variance, covariances - sometimes not easy due to spectral variation present
Read more on Digital Image Classification.
To Read
To Do
- Submit materials for Digital Image Classification