Lesson 4: Doing Spatial Analysis
Lesson 4, Lecture 1
Spatial Analysis
Overlay (and Beyond)
Now that you’ve got a grasp on the basics about thinking like a geographer and understanding geographic information, it’s time to focus on how to understand geography through analysis.
The most basic method of spatial analysis uses a really simple technique: overlay. It’s exactly as it sounds – all you do is stick one layer (number of people currently talking too loudly on their cell phone) on top of another layer (one that shows Starbucks locations) and compare the results (look, lots of people talking too loudly are standing in/around a Starbucks!). You could do this with lots of layers and end up with a composite overlay that lets you explore all sorts of possible relationships.
Overlay analysis also goes beyond simply looking at where two things overlap. You could also do overlay analysis to extract just the area where two things intersect, to delete any areas where two or more things intersect, to join two datasets into one larger dataset, and more. Check out some of the options here at the ARC GIS Resources page, [1] if you’re interested.
Put A Ring On It
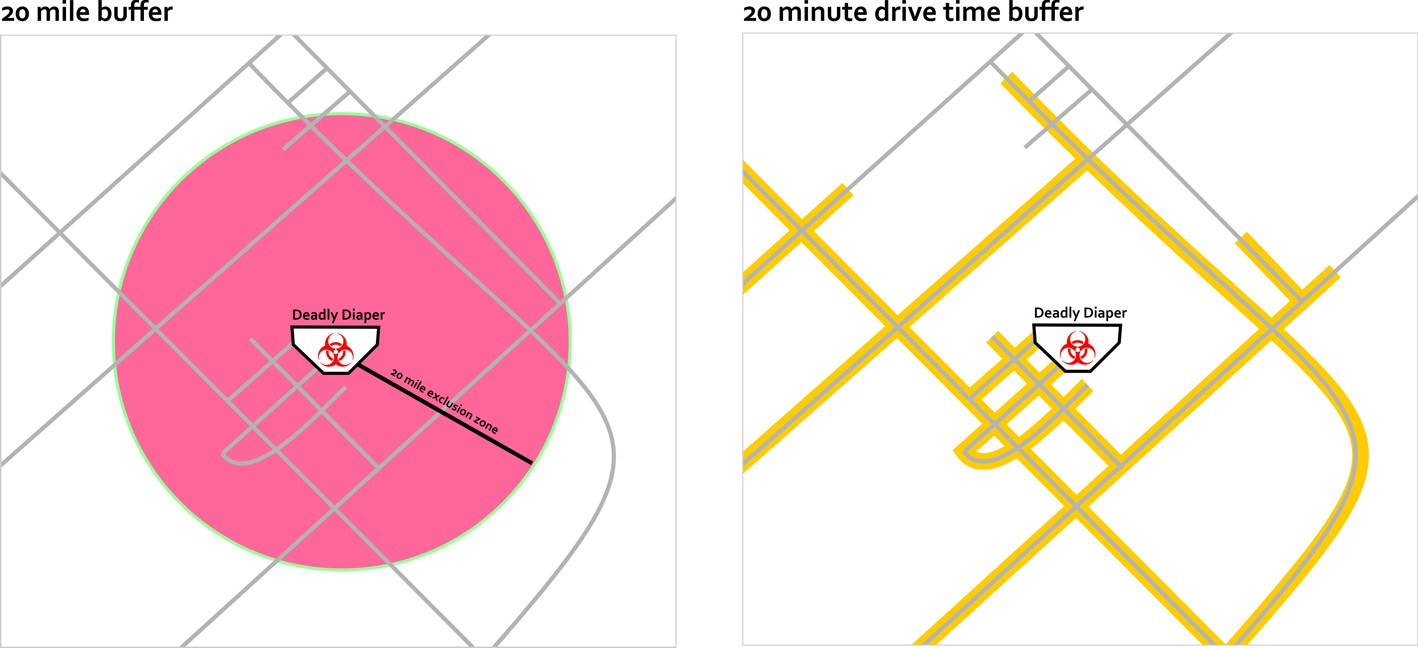
In the previous example, I mentioned the area around a Starbucks location. Identifying these areas is part of another common spatial analysis technique. Buffering identifies areas of interest around locations based on distance or time. This could include a 20-mile radius around a terribly disgusting diaper that my daughter creates, or an irregular shape that shows the places that are reachable within a 20-minute drive of my house if I try to escape this terrifying situation.
Surface Analysis and Interpolation (Heat Maps Are Not Always Hot)
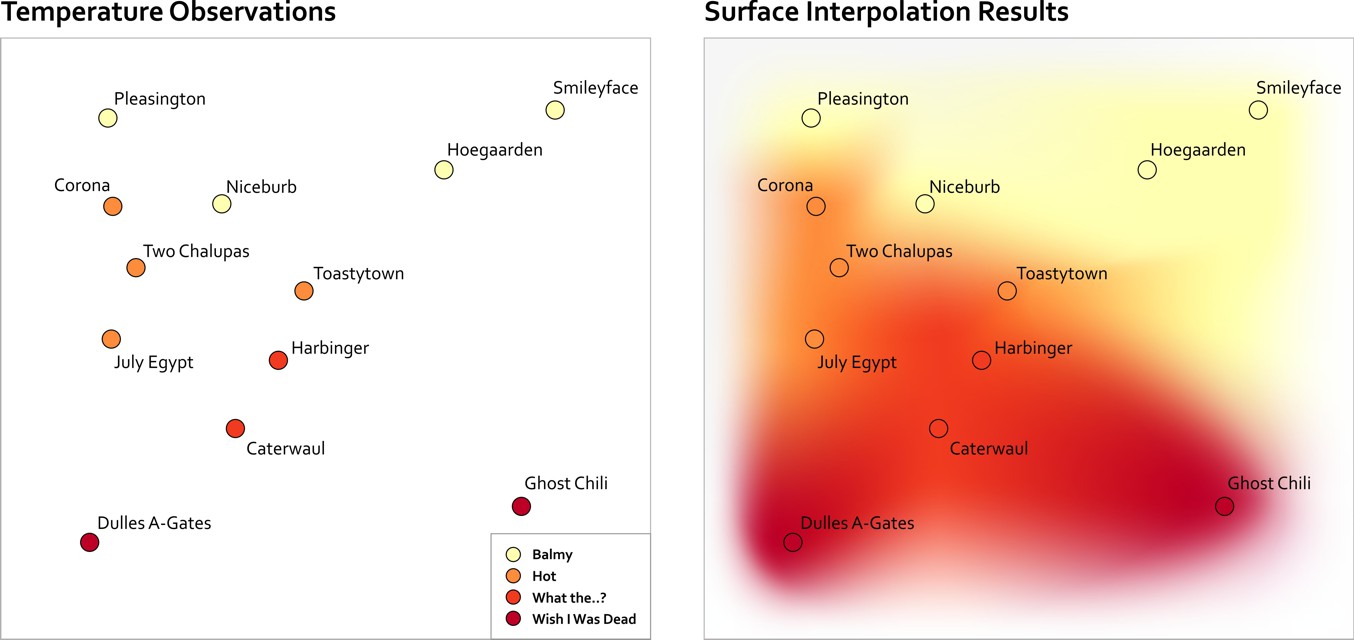
Another common spatial analysis scenario occurs when you’ve got lots of individual observations and you want to create a map that shows the overall trends that correspond to an area. Let’s say you have a bunch of temperature readings for a collection of cities and small towns. In the maps shown below, you can see what I can do just using colors assigned to each point observation. You can get a sense of the overall pattern this way, but temperature doesn’t just exist at discrete points, does it? It’s a continuous phenomenon, so it would be nicer to show this data in a way that communicates this aspect more clearly.
In the map on the right hand side you can see how this would look if you interpolate between those observations to estimate the overall pattern of temperatures in this region. There are many mathematical methods [2] for interpolating between values and creating surfaces (hence the label “surface interpolation” below). These types of maps are frequently called heat maps, after the “hot” color scheme normally used in their design. A more correct name would be "density surface," but cartographers seem to have lost that battle, as heat map is way more popular (it sounds cool, so why let the actual name for things get in the way?). I don’t know what you should do if you want to create a heat map to show the density of ice bars [3] in Scandinavia.
In the Geospatial Revolution video you'll watch later in this lesson, you will learn about John Snow’s famous map of a cholera outbreak in London. Dr. Snow’s work revealed that cholera cases were happening close to one particular water source. A set of spatial observations that differ from the expected variation around a point or region is called a cluster. In the example from John Snow, the cluster was detected based on his intuition. Today we have the advantage of mathematical methods that can detect clusters automatically. More importantly, these methods can help us identify spatial clusters that are unlikely or impossible to detect through our own intuition or visual inspection alone. While it’s outside the scope of this course to learn the inner-workings of cluster detection, I do want you to know that today the folks who work in epidemiology would never rely on their intuition alone to detect clusters. They’ve got fancy software [4] that uses fancy space-time math [5] to do that.
Lesson 4, Lecture 2
Analysis Pitfalls
Rain Causes Lung Cancer (No, It Doesn’t)
Now that you know a bit more about ways to do spatial analysis, I want you to understand some all-too-common ways in which these analyses can fall apart if you’re not careful.
Most of the analysis techniques mentioned earlier in this lesson will cause you (or the people who read your maps) to start making assumptions about the correlation between observations. To put it plainly, just because there appears to be co-occurrence between two things, it doesn’t mean that one of things is causing the other to happen.
To explore this pitfall further, let’s check out a wacky example that we wrestled with here at the GeoVISTA Center [6] back in the early 2000s. At the time we had a research project with cancer epidemiologists from the National Cancer Institute [7]. Dan Carr [8] from George Mason University (who was also working with the same folks at NCI at the same time) had discovered a really intriguing pattern while trying to explore geographic patterns of cancer mortality and its possible correlation to a bunch of social, economic, and environmental variables. Here’s what he found – lung cancer mortality correlates quite well with… mean annual precipitation. Yeah. Rain. Does that sound plausible to you?
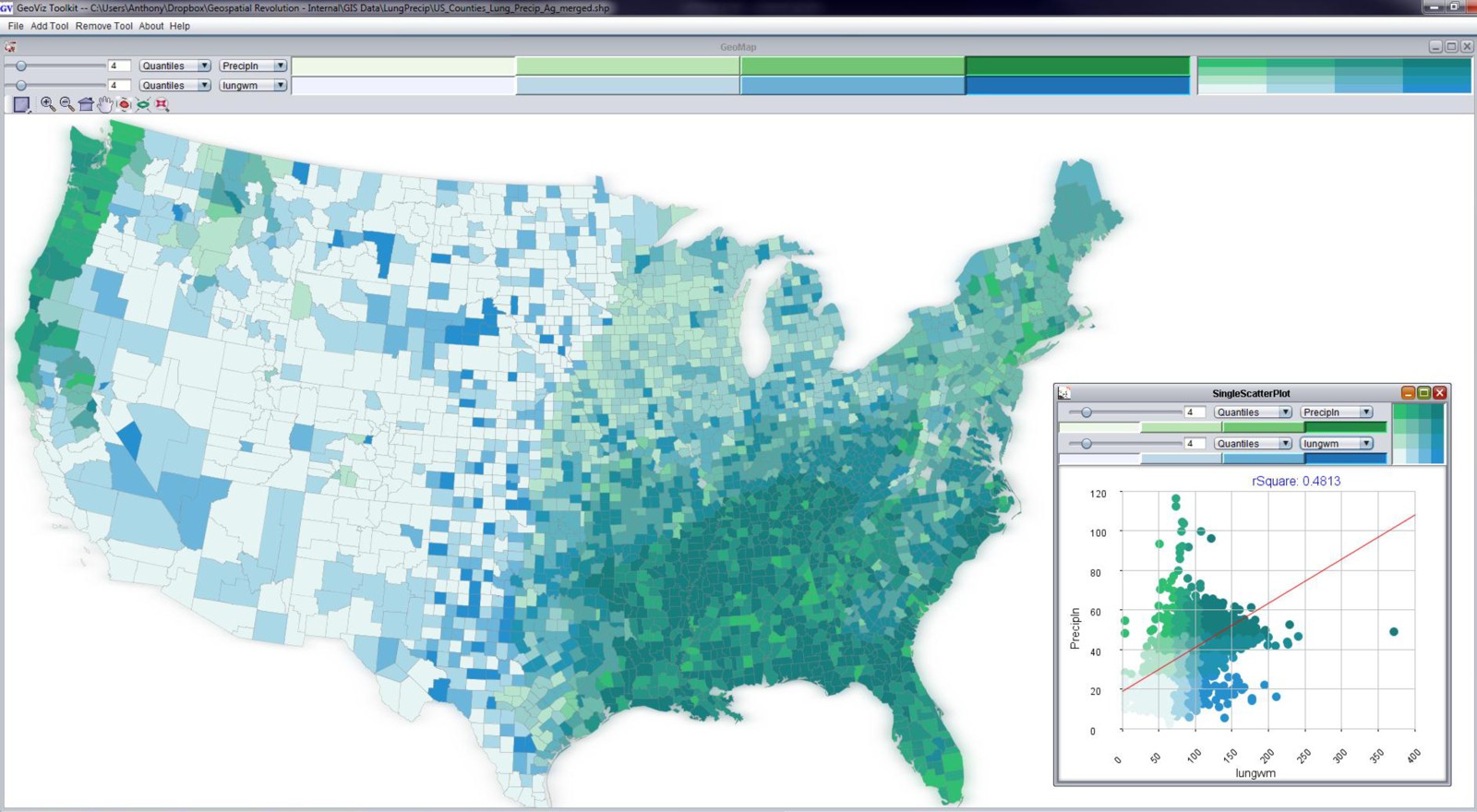
You can see the in map above (created using the GeoViz Toolkit [9]) that there are a lot of counties that show up as dark blue/green. This is a bivariate (two variable) choropleth map. The Y-axis here (with green category colors) is used to show the precipitation variable, and the X-axis (with blue category colors) shows the lung cancer mortality rates. When you see the dark blue/green color at the high end of both X and Y axes, you’re looking at counties that are high in both of those variables. Places that are only green or only blue are lower on the other respective variable. The scatterplot shown in the bottom right corner shows the data distribution of both variables. You probably can’t read the correlation measure, but it says that the R-squared value is .48 – this was a strong correlation measurement compared to most of the known relationships between lung cancer mortality and other variables (poverty and smoking show strong associations too, for example).
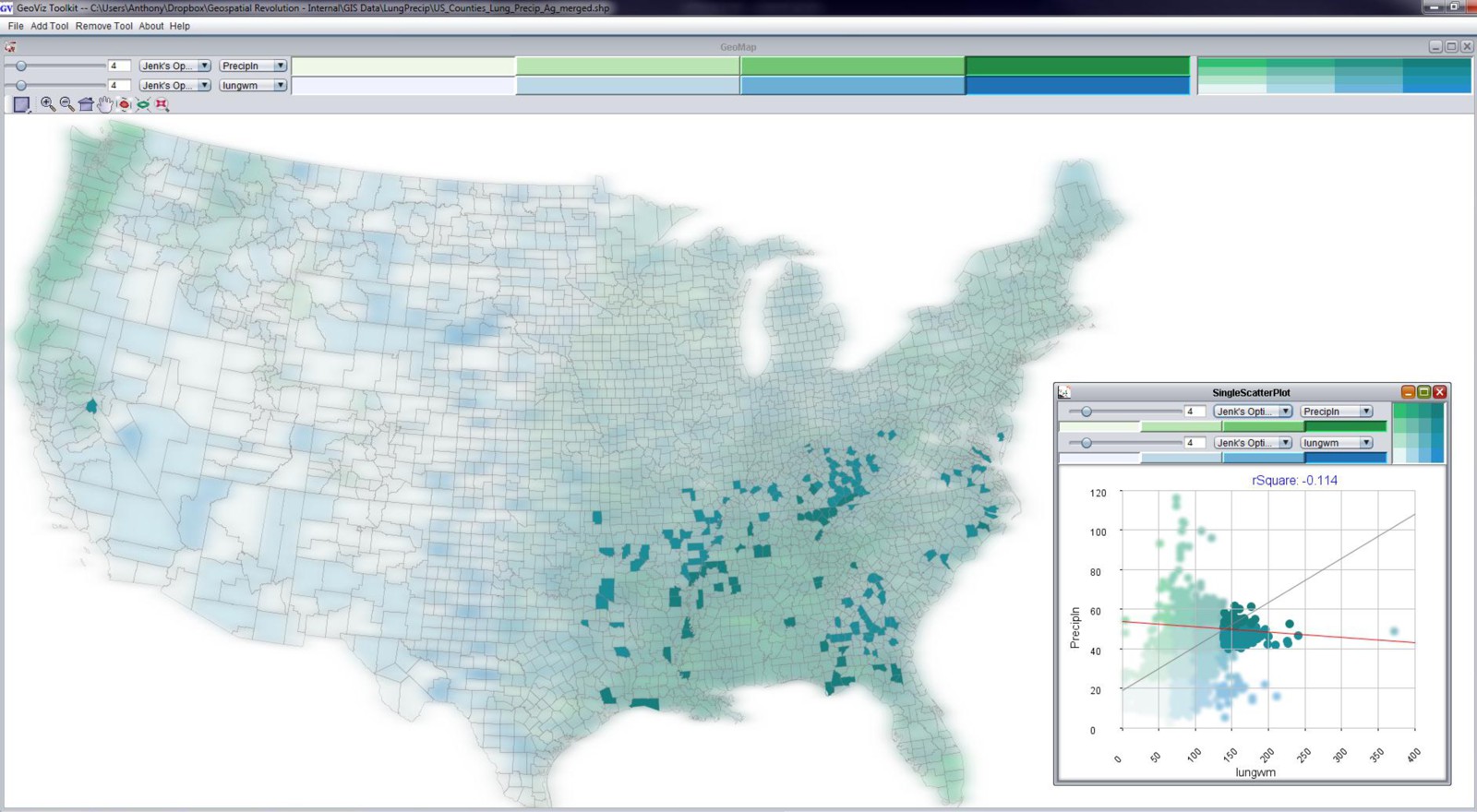
When I select just the counties that are both high in precipitation and high in lung cancer mortality, you get the map above. Most of the counties are located in the Southeast United States. We spent awhile working with Dan Carr and the epidemiologists at NCI to try and tease this apart further, to no avail. There’s nothing there to report – it’s just correlation, nothing causal. It’s not that rain has any real impact on lung cancer mortality. It just happens to rain more where there are people who meet a range of other risk factors. This is a perfect example to demonstrate how correlation is not the same as causation.
Playing Tricks with Scale
Another major pitfall here relates to the scale at which you conduct spatial analysis. Depending on the scale at which you look at a Geographic pattern, you can derive completely different results from the exact same underlying data. This is called the “Modifiable Areal Unit Problem” or MAUP in acronym form (and said aloud it sounds like the noise that comes out of your throat after eating too many nachos).
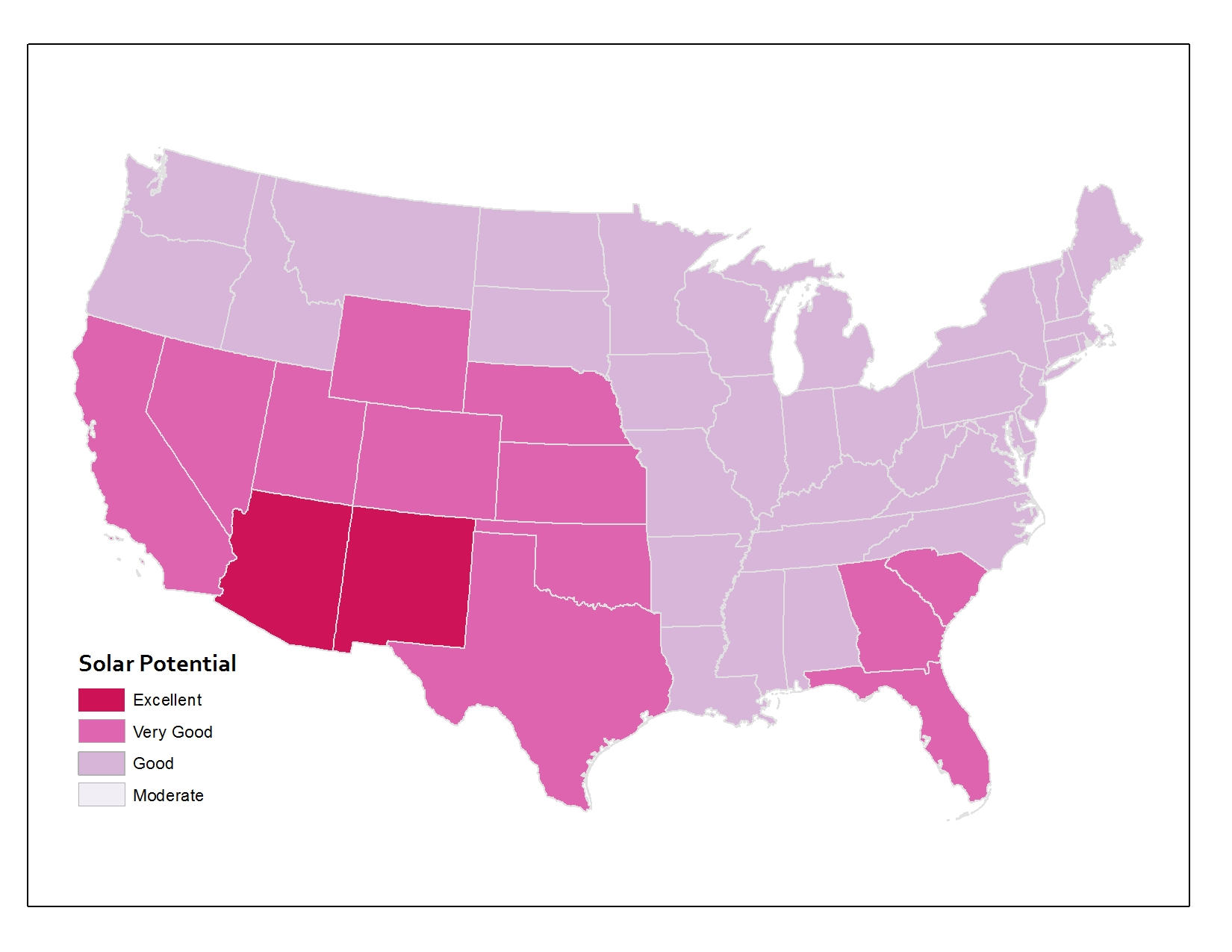
Let’s explore this issue now by looking at some data about Solar Potential in the lower 48 United States. Solar Potential refers to the suitability of a particular place to develop solar power. The data [10] I’m working with here is from the National Renewable Energy Laboratory (NREL [11]). The first map shows the average annual solar potential by States. You can see right away that some states look better than others.
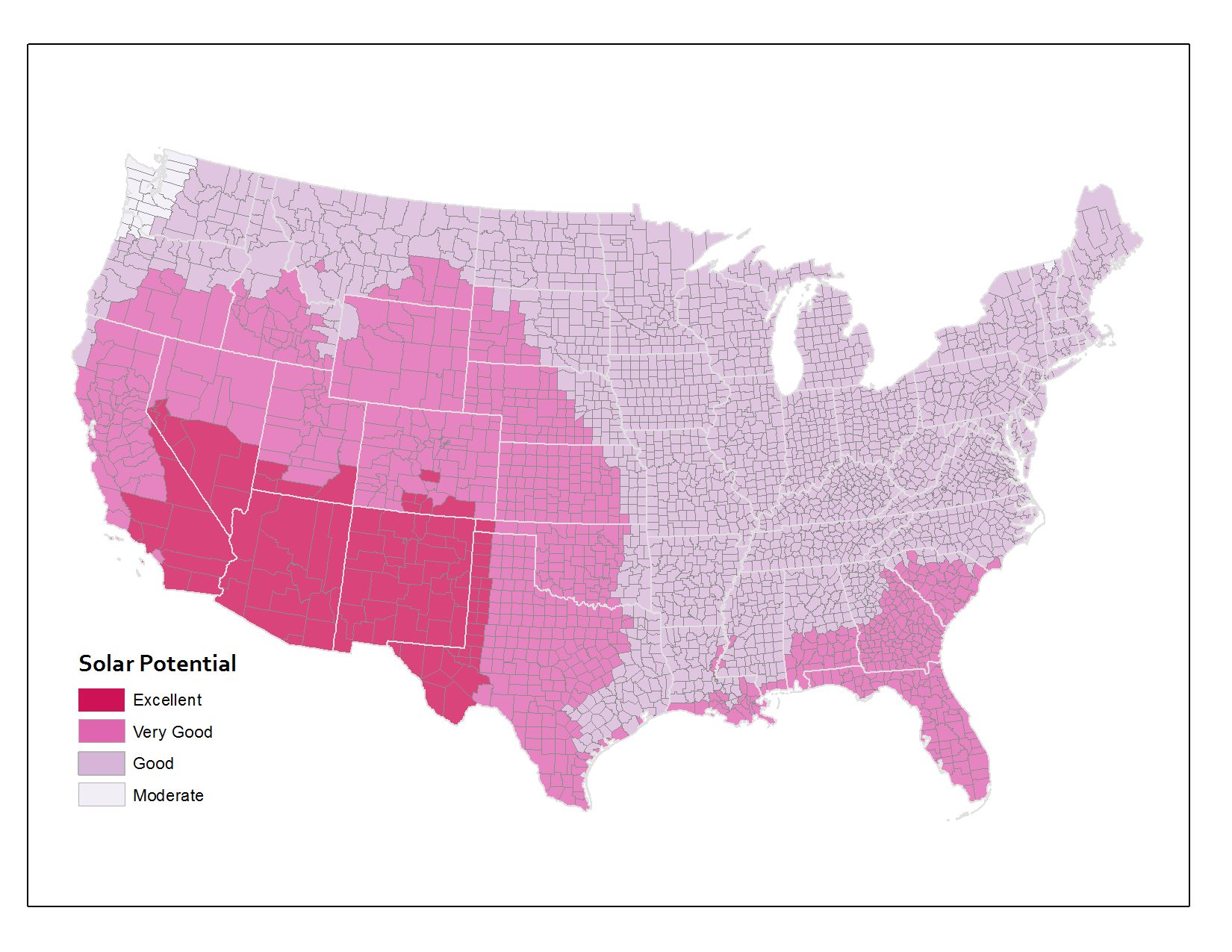
But what if I use the same underlying data and instead of aggregating to States, I come up with measures for counties instead? You can see the map below showing the same data if it’s represented at the county level. The picture is already a lot more nuanced than the state map, right? A lot of states that were shown in one color up above actually include members of several categories when you look at the data by county.
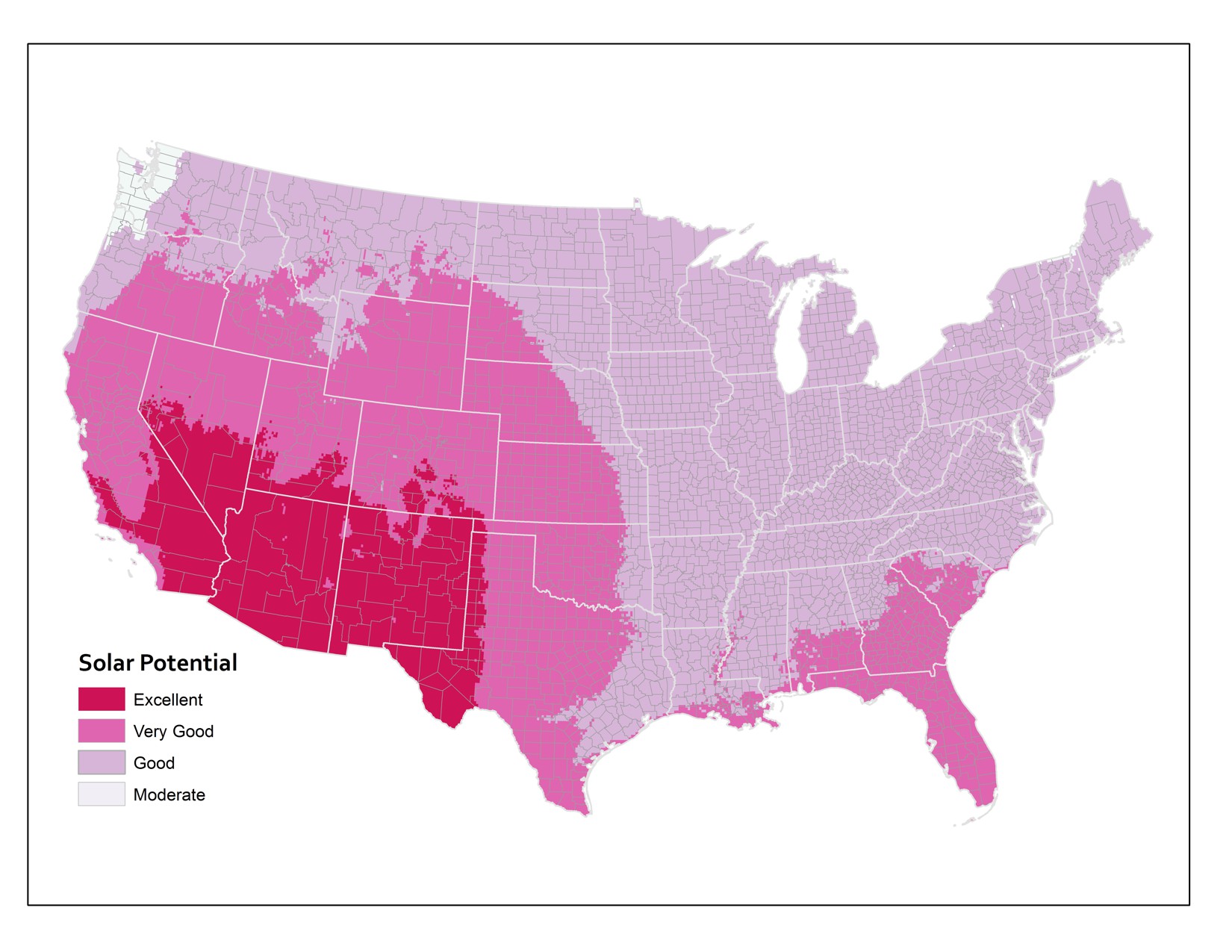
And the third map here shows the original underlying data that the other two maps were based on. The original data source calculates solar potential in 10 kilometer grid cells. So that’s why things look a bit rough at the edges. This is actually the most precise measurement level, however. I’ve overlaid the state and county boundaries so that you can see how the raw data compares to the units by which we typically try to aggregate things.
Normalization
Mapping Rates, Not Totals
A stunningly common analytical mistake by newbie mapmakers is to neglect normalization when you’re working with population-dependent data. Let me to say that in normal-people language instead: if you map something about people without calculating the rate based on the how many people live at that place, you’ll get a really stupid map. Same goes for if you’re mapping something about dogs (how many of them have breath that smells like dead fish? – there’s one at my house, for sure). You’d want to normalize your observations against the total number of dogs that could be mapped.
Check out what happens if you don’t normalize your data. This map shows the number of vacant houses by county in the lower 48 United States (you can find this data, along with tons of other stuff at the U.S. Census website [12]). What does it tell you? It looks like there are lots of vacant houses in and around major cities. And that’s it.
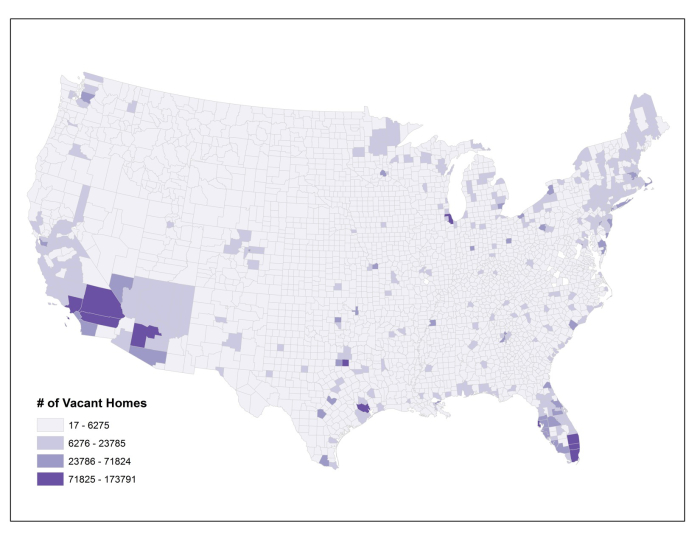
Here’s a version of this map that’s been normalized. I calculated the proportion of vacant homes to the overall population in each county (in thousands). That gives me a rate, rather than a raw total value. Now I can see which counties have high percentages of vacant homes, relative to all other places. It turns out that there’s an interesting pattern happening in northern Michigan, Wisconsin, and Minnesota where vacant homes are more common per person than in many other parts of the country. I did a little digging around and I think I know why – can you figure it out? If you think you have the answer, post it in the forums and debate the possible reasons with your classmates. There are different reasons why different counties across the country might have a lot of vacant homes, of course, but I think there are a few key reasons why these particular counties show this pattern.
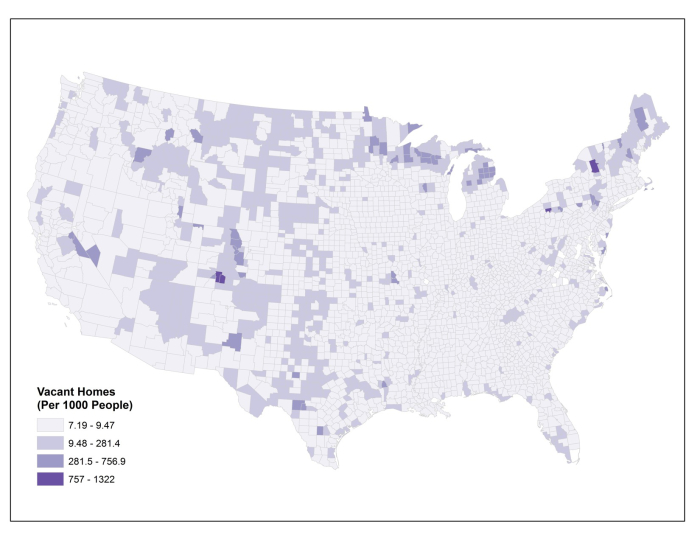
A normalized map is much more useful, right? If you don’t normalize data for choropleth maps like these, you’ll end up having a zillion versions of the first map above – where there are more people, more houses, more dogs, whatever – you’ll have more of the thing you’re interested in and it’ll always just highlight the major population centers. This phenomenon is called population dependence because the thing you want to know about (nasty dog breath), will vary depending entirely on the size of the overall population (number of dogs that are breathing).
Video Activity
For this lesson I'd like you to watch Chapter Three from Episode Four of the WPSU Geospatial Revolution [13] series. This video highlights how geospatial technologies and analytical methods are transforming how we conduct disease surveillance and implement health interventions to prevent major outbreaks.
Mapping Assignment
Real Time Data, Social Media Mapping, and Finding The Best Place For Things
This week, your reading and lectures focused on understanding geography through analysis. You learned about map overlays, buffer zones, heat maps, and other methods. You also learned that simply having a plethora of spatial analysis tools at your fingertips to apply to your maps does not mean you can let the tools do the work with your brain taking a much needed coffee break. On the contrary, with the power you have comes responsibility: You need to consider things like the scale that is appropriate for analyzing your data, mapping totals vs. mapping rates, and correlation vs. causation.
This week’s lab gives you the opportunity to practice these concepts in ArcGIS Online. You will be evaluating relationships among different variables. You will examine maps that show geolocated social media in all of its ephemeral glory. You will analyze data using tables and maps. And you’ll do some spatial analysis, including the creation of buffers and routes.
Analyzing Real Time Weather Data
Real-time data is increasingly available, and much of it also includes geographic data. Let’s analyze some weather-related real time data by opening Esri’s public information map on severe weather [14].
This map should look similar to the map below. Note that this map is an example of a live map embedded in a web page. If you are using a browser with language settings other than English, this may not work for you. In that case, please check out this similar example [15].
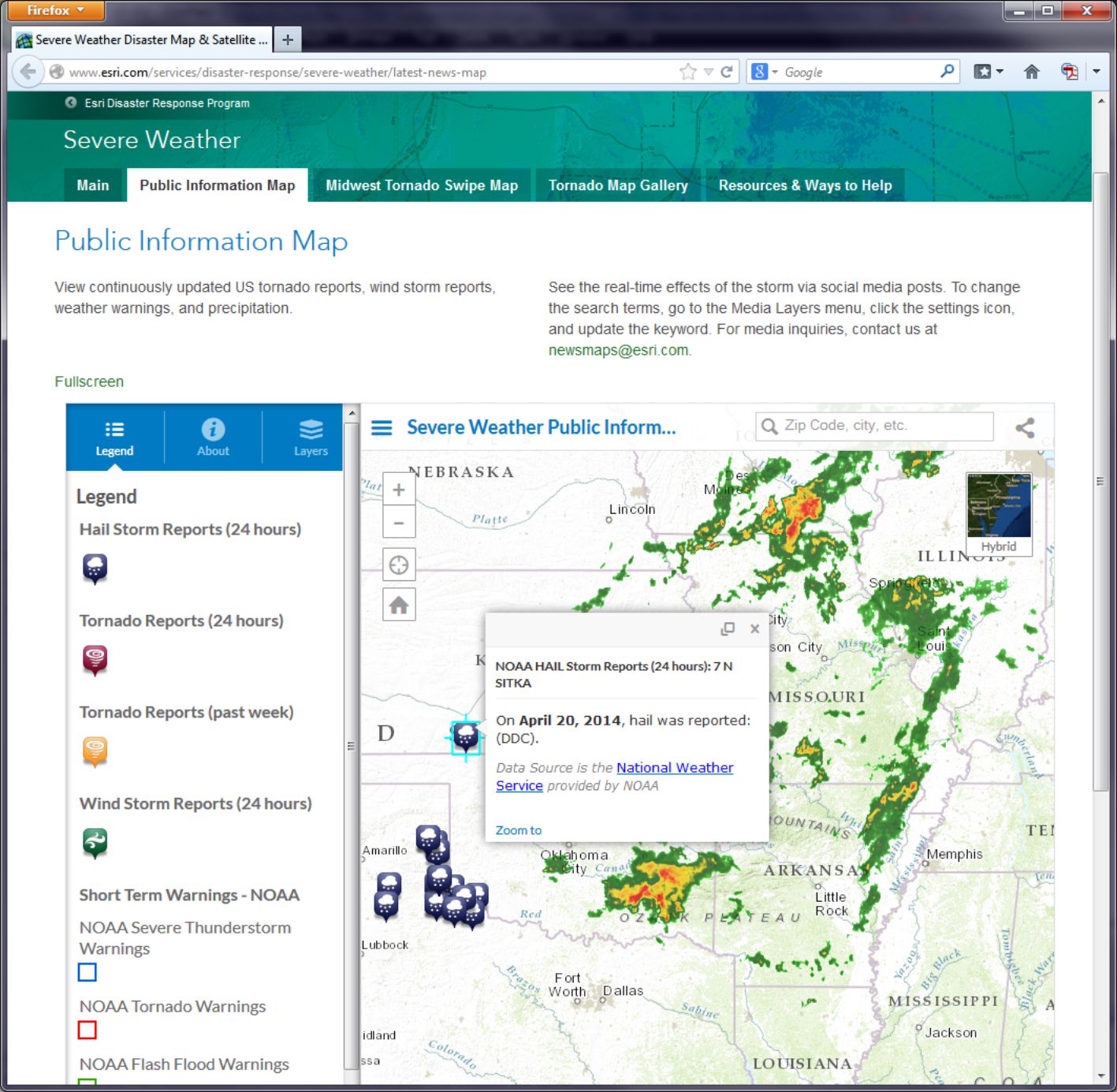
- How would you say that tornadoes, wind storms, hail storms, and precipitation are related in space and in time?
Now head over to Esri’s Flood public information map [16].
This information on flood warnings and observed floods comes in part from USGS stream gauges along rivers. These stream gauges upload data to a national network which is then fed in as a live web mapping service in ArcGIS Online. Click on the “i” information button and then the link to More Information to explore details about where the data are coming from.
- Which agency provides the flood data? How often is it updated?
- Can you find a relationship between where precipitation is falling and floods on the map?
Think about how the duration of precipitation and the time between when precipitation falls and when a flood might start to occur. Then think about how the size of the watershed that is drained by the rivers that flow by a particular gauging station influences the river height at that gauging station. Several factors influence the relationship between precipitation and floods as displayed on a map. You can examine the other Esri disaster response program maps on Esri's disaster response page [17].
- Can you find a spatial and temporal relationship between data layers on the hurricanes and cyclones, wildfires, or earthquakes pages?
In the next section you will examine geospatially-oriented social media [18] related to severe weather events. Who knew that thunderstorms would cause a Flickr apart from the lights going out in your house?
Mapping Social Media
Social media frequently contains geographic information, because social media posts are often sent from devices that can snag a location from a GNSS. Therefore we can make maps showing social media in many cases. Entire platforms like Ushahidi [19] and Tweak The Tweet [20] are built around the use of social media mapping. So let’s see what we can do with it ourselves.
Head over to the Esri severe weather public information page [14].
Click the Layers button in the panel on the left side of the map and scroll down until you see Media Layers. Notice that you have a choice of Instagram, Flickr, Twitter, and Webcams. On Flickr, click on the gear icon to look at the Flickr Search Settings. Notice that it is currently set to storm or tornado. Change it to hail or tornado and select Search.
- Can you find any correlation between the locations of hail and the locations of tornadoes?
Zoom to different scales and pan the map to explore multiple locations, and see if you can observe any patterns (or lack thereof). Next, change the Flickr settings search term to Oklahoma. You may expect that your results will only show Oklahoma, but what happens if someone refers to Oklahoma in a photograph they take in Pennsylvania? If the search term you use is in the metadata that the sender of the post, video, or photograph provided, it will appear on the map, even if the post did not originate from the place listed in the post.
- What are a few benefits and limitations associated with gathering and using data from social media?
Raw Data Analysis
Let's have a look now at the information behind the map, which is stored as a table.
The Human Development Index (HDI) is a composite statistic used by the United Nations to rank countries by level of "human development." It can be considered a synonym of the older terms “standard of living” or “quality of life,” and countries can be thought of as "very high human development," "high human development," "medium human development," and "low human development" in terms of the UN HDI. This index is used to make decisions on policy issues for economic, social, political, and cultural development worldwide.
You can read about the HDI here: Human Development Reports [21]
- What benefits (or limitations) do you see from these documents about the HDI?
- Where do you think HDI will be highest and lowest around the world?
Now navigate to ArcGIS Online [22]. Log in using the account you set up in Lesson 2.
Copy and paste this web link into your browser navigation bar: http://www.arcgis.com/home/webmap/viewer.html?webmap=da264828e12741948799e9d8ffac3a48 [23]. You can also just click the link here and it should open the map just fine. You want to make sure you're logged in, though, because later you'll want to save the changes you make to this map.
- Is your hypothesis about where HDI will be highest and lowest supported by what you see on the map?
Next, click the little arrow to the right of the HDI 2006 layer and select Show Table. Use the Sort Ascending or Descending Order function on the HDI2006 column to answer the following questions (note that some countries come up as -99, which is the value assigned when there is missing data):
- What country is the lowest in HDI? What is its HDI rank?
- What country has the #1 HDI Rank? What is its HDI value?
Now click Table Options at the top right of the table view and choose Filter. In the following dialog box, select Human Development Index 2006 (HDI2006) from the first dropdown list. Then select is less than from the second dropdown. And finally, enter .5 into the Value field. Click Apply Filter when you're ready.
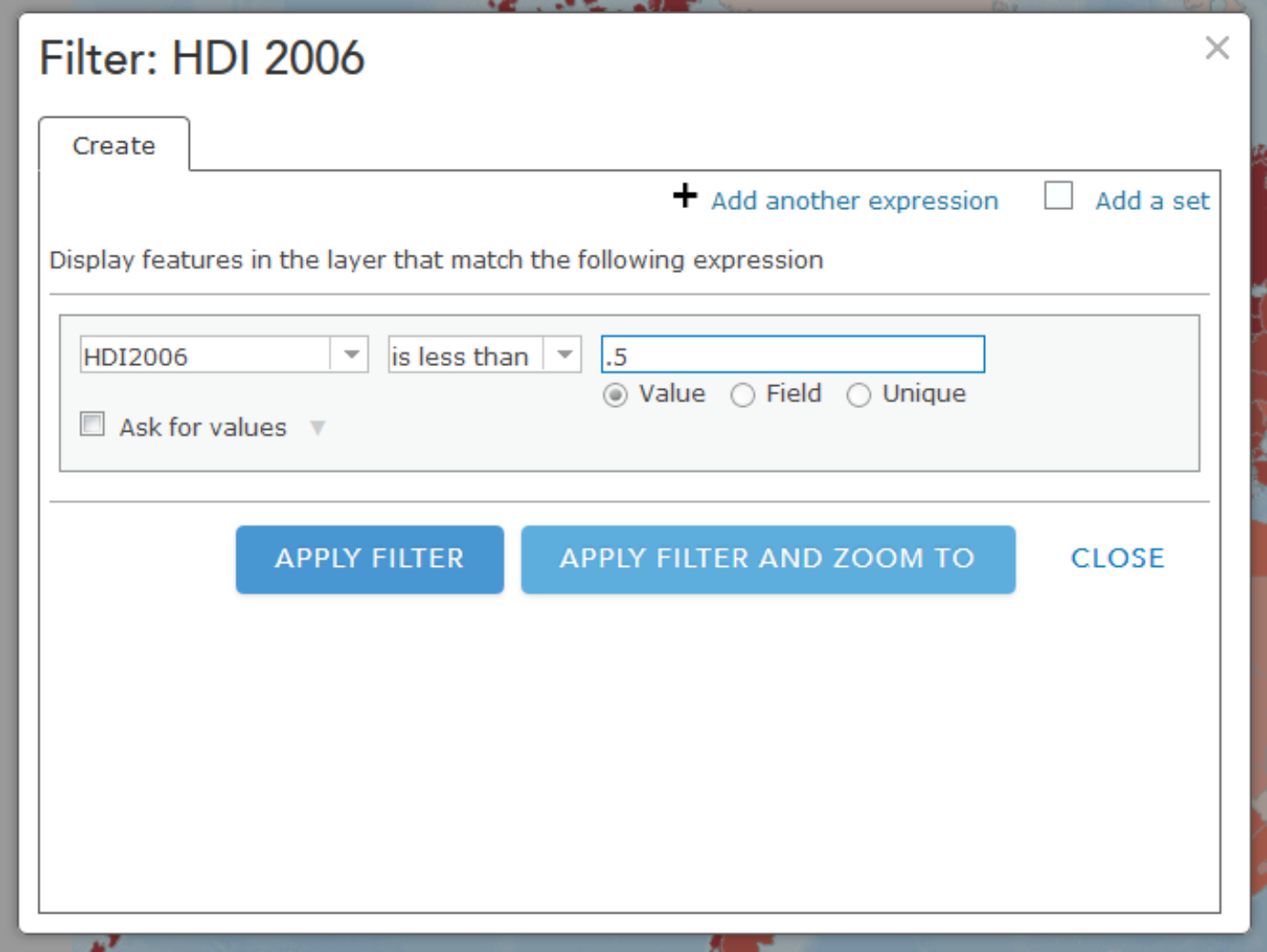
You should now see only the filtered countries on your map that have an HDI of less than .5. Now is a good time to try out other filtering operations that you think might be interesting. You might also want to save this map (every Map is sacred).
Spatial Analysis
Note: Some of the apps you'll try in this section of the assignment will take a little while to return results. Please be patient! Clicking lots of times really fast won't help.
This week you read about one type of spatial analysis called buffering. Click this link to try creating your own buffers: http://developers.arcgis.com/en/javascript/samples/util_buffergraphic/ [24]
Let’s say you are seeking to start a new boat repair service (Salt Lake Sloops or Saline Sails) near the Great Salt Lake, Utah, and you want to locate your service within 25 kilometers of the lake to maximize the number of potential customers. Under the Buffer Parameters heading, set the distance to 25 kilometers. Then use the Freehand Polygon tool to trace the outline of the Great Salt Lake in the north-northwest section of Utah.
- Would Salt Lake City be included in your list of cities to consider? What about Provo?
Another kind of buffer is a temporal buffer, which calculates the amount of time required to walk, bicycle, or drive to or from a certain location. Open this map to create some buffers to show drive times:
http://developers.arcgis.com/en/javascript/samples/gp_servicearea/ [25]
Click on a location in Lawrence, Kansas and wait for the drive time buffer to appear. Click on Interstate Highway 70 (a limited access highway) and note the differences. Click just north of the river and note the effect of the river on access to areas south of it. Observe that the drive time buffers depend not only on the street density, but they have intelligence beyond street location: they take into account one-way streets, stop signs and stop lights, traffic volume, speed limit, and terrain. Pan the map to a rural area outside Lawrence and click on the map in that location.
- What is the difference in the amount of terrain someone could reach in 1, 2, and 3 minutes from a rural area vs. from an urban area?
Now that you've seen how drive times might be helpful for understanding service areas, let's check out what happens when you use a similar method to explore attributes about people in a particular area. Open this map to explore population in Census Block groups [26] within 1 mile from whichever place you click.
Each of the purple dots represents a block that is included in the total count of the population within the 1 mile buffer. Notice that at the upper right of the display you can see the total population inside this buffer. You can use this sort of data to drive a more sophisticated service like this one:
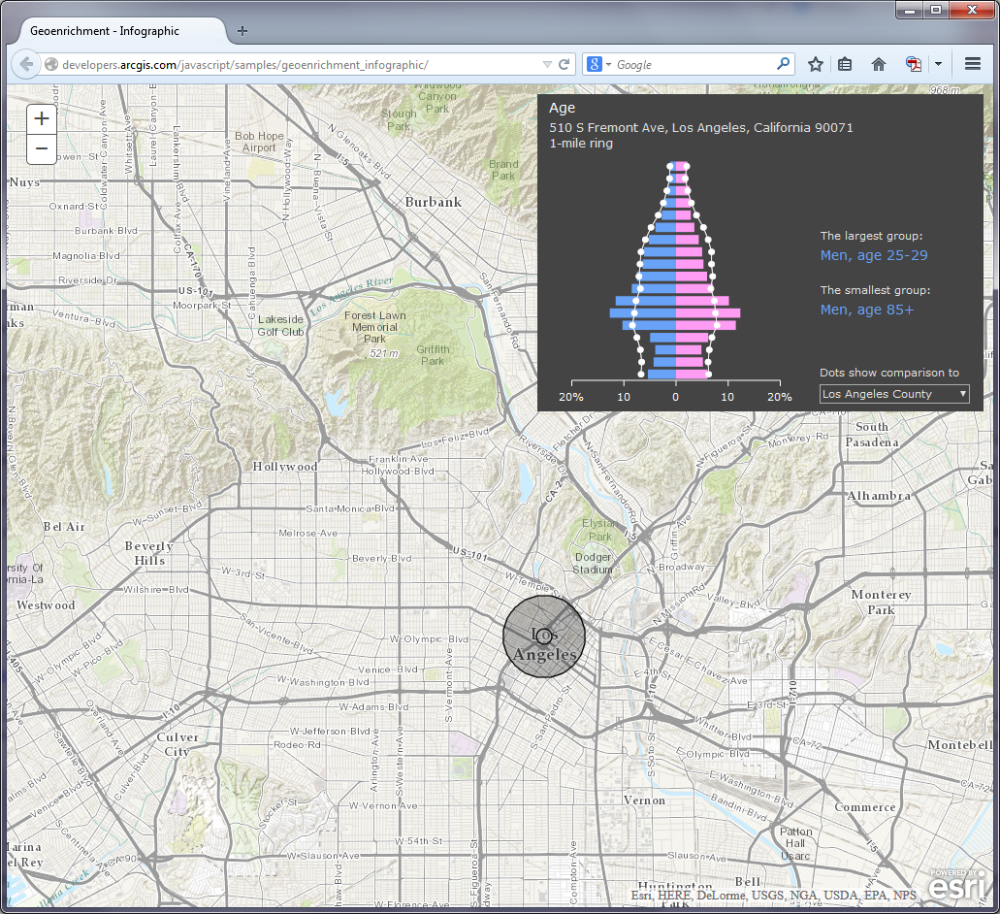
http://developers.arcgis.com/javascript/samples/geoenrichment_infographic/ [27]
In this example, when you click on the map a population pyramid is created for the buffer area. You can compare the population categories for each place vs. all of Los Angeles, California, or the entire United States. A good way to start exploring this example is to click first right on the center of downtown Los Angeles. Take note of the overall shape of the pyramid. Next, try clicking on Bel Air (to the northwest of Downtown LA, home of the Fresh Prince). What differences do you see? What other data would you want to have to explore these differences further?
Viewsheds and Zonal Statistics
Viewsheds are another type of buffer. Viewsheds indicate how much terrain is visible from specified locations. Viewsheds are important not only in planning scenic overlooks along trails and highways, but help in everyday decisions such as siting cell phone towers, determining how much terrain would be in shadow if a certain high-rise were to be constructed, helping plan safe roadway curves, and much more.
Use this map to create your own viewsheds [28].
This map service shades the terrain viewable within 5 miles of your chosen point. Let's say you are interested in taking photographs in San Francisco but you only have two hours to do so, since you’re on a layover at SFO on your way to Sydney. You want to be as efficient as possible, choosing locations that allow you a magnificent view. Click several locations on the map and observe the viewshed for each location. Your viewshed should be better if you click on one of San Francisco’s hills. For example:
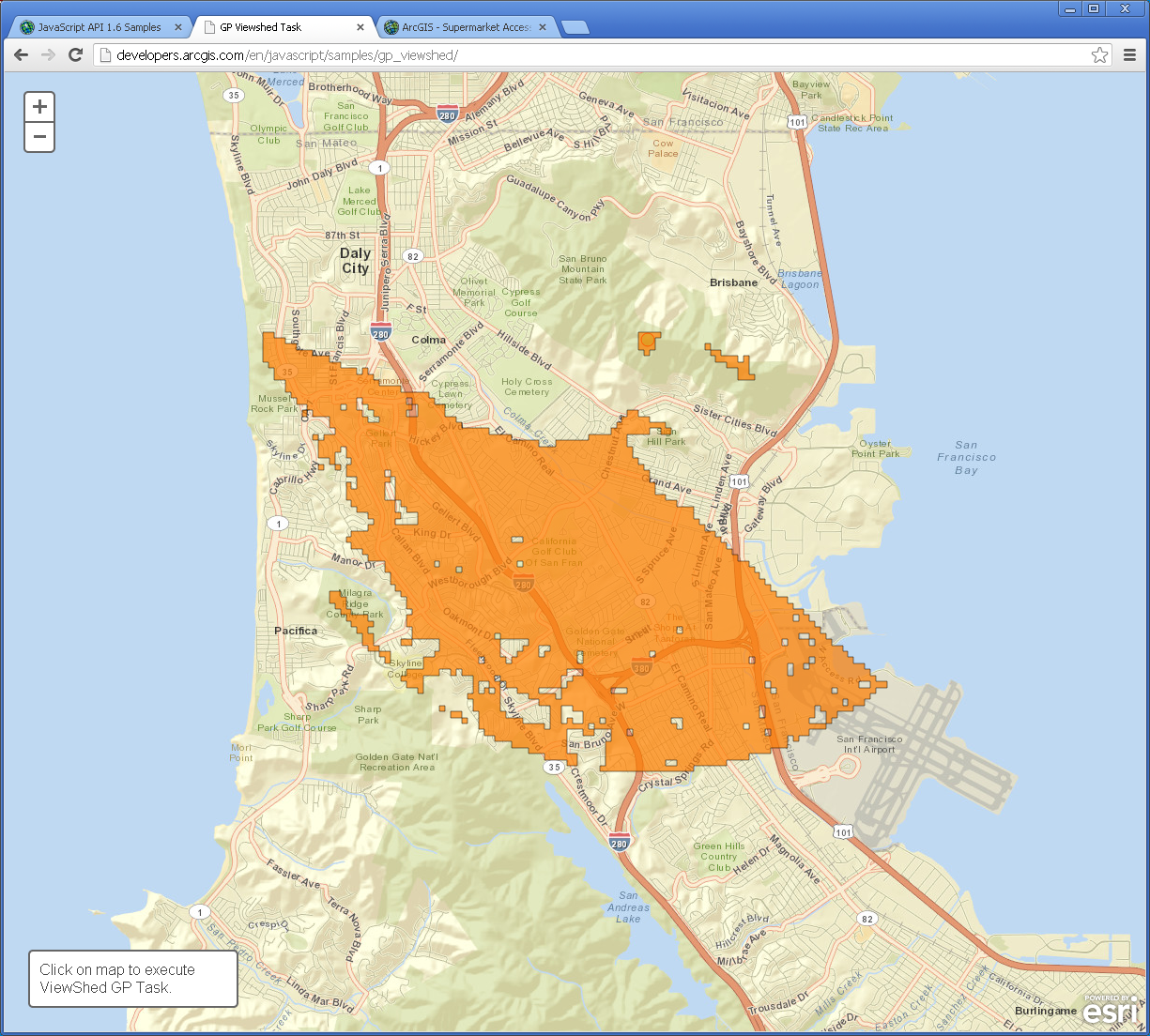
- Judging from the shape of this viewshed, would you be standing on a south-facing hillside or a north-facing hillside?
Click on the Golden Gate Bridge (leading northward from San Francisco on US 101).
- Why is the 5-mile viewshed so much greater in area at this location?
Another type of spatial analysis that computes and summarizes data from rasters is called zonal statistics. Try this little application to summarize population in specific areas [29].
Click on the words Summarize Population in the lower left section of the map and then draw a polygon that encompasses Atlanta, Georgia.
- What is the population in and around Atlanta?
- Why is your result different each time you draw the polygon?
- What aspect of the population data layer influences the results you receive from these area calculations?
Routing
Finally, we also have a whole set of functions to determine the best route and the closest facilities to specific locations. This is important for a wide range of applications, from emergency services bringing people in an ambulance to the nearest hospital to finding the nearest competitor for your planned new Taco & Donut Gastropub (Carnitas & Crullers).
Open the following map: http://developers.arcgis.com/en/javascript/samples/routetask_closest_facility/ [30] and click on the map.
What is the closest competing restaurant to your chosen point? Change the choice under the map to find the routes to show the two closest facilities instead of just one.
- Can you think of an application where knowing where two or more closest facilities would be really important?
Often, as in the case of the Kansas River that you earlier examined in Lawrence, Kansas, there are barriers. Barriers may be physical (rivers or mountains), or they may be human-caused, such as construction projects, one-way streets, or a blockage due to a car accident.
Examine this map on route barriers. [31] (uses Javascript)
Let's assume you are running a bicycle courier service in downtown San Diego. Your pick up point is at 1st Avenue and Market Street. Your destination is at 10th Avenue and Market Street. Add these 2 stops and have the map calculate your route, shown in blue. Now let’s say there is construction at 8th Avenue and Market. Use Add Barriers and add a barrier at 8th Avenue and Market (2 blocks West of 10th and Market).
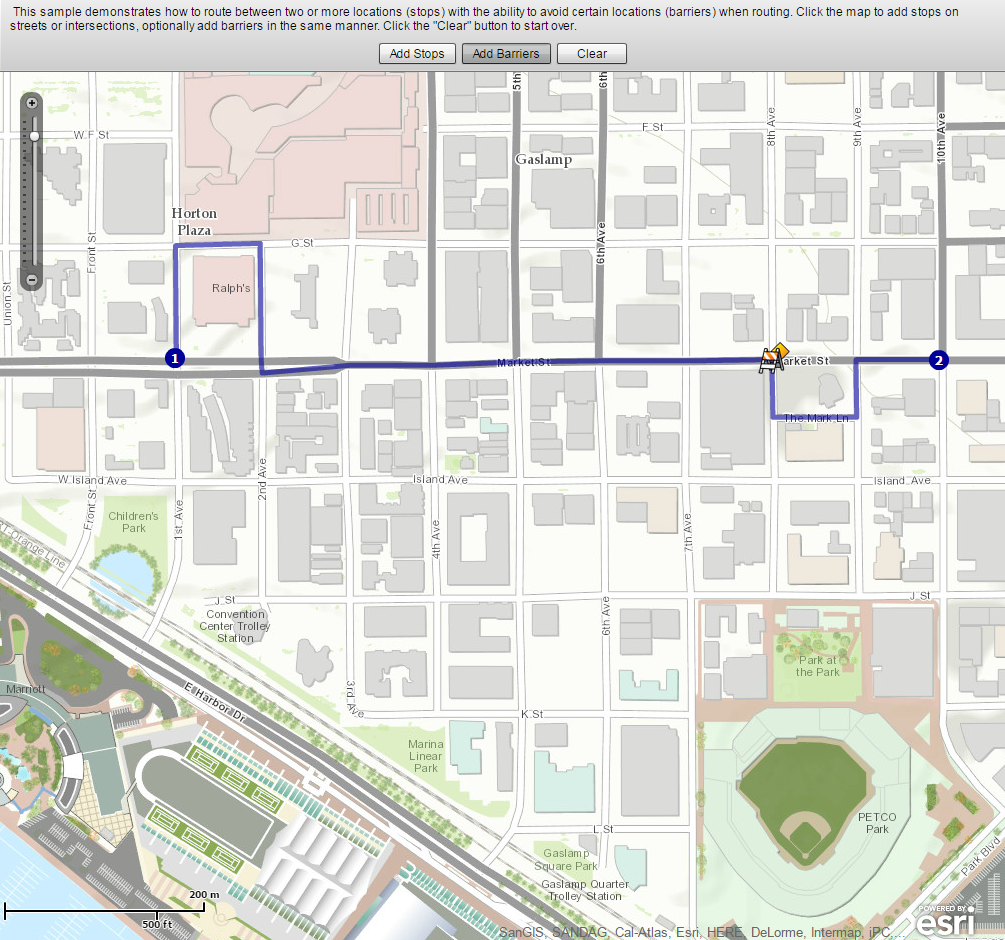
- What changed on your map after you added a barrier?
Supermarket Sweep
Open the following map that incorporates point, line, and polygon data and some of the spatial analysis techniques that you have been exploring above:
ARCGIS Map [32]
This map shows access to supermarkets. The supermarkets have been buffered for walking (1 mile) and driving (10 minutes), and aggregated poverty data is also shown. If you click on the Legend button you'll see that supermarkets and farmers' markets are also shown. Notice how the symbology changes as you zoom out from Detroit to the county level.
- What is the purpose of this map? Why is access to supermarkets a concern in Detroit?
- How has at least one of the spatial analysis techniques you have been exploring in this lab been used to create this map?
Wrap Up
Wow, you're a mapping machine now. In this lab you analyzed real time data and studied the relationships among different variables. You also worked a bit with mapping social media. You used a variety of spatial analysis techniques including buffers, viewsheds, drive time analyses, and routing algorithms. You pretended like you were repairing boats, running a restaurant, and working as a bike courier. It would be cool to have all of that on one resume.
Credit Where It's Due
This lab was developed by Joseph Kerski [33] and Anthony Robinson [34].
Discussion Prompts
Mapping Social Media: What's It Good For?
You've now had some experience playing around with mapping Flickr photos and other social media sources, so let's talk about what this means for the future. Let's say everyone registered for this MOOC tweets five times (once each week) and mentions locations in each message (plus they have profile locations, and a GPS-recorded place where the phone was located when the Tweet was posted). That would result in tweets all over the world by the tens of thousands.
- Look for some examples outside of the ones we've used in class that use maps to show social media. Share them if you like. Can you understand the stories they're trying to tell? Why or why not?
- Scale is an issue for multiple reasons when it comes to mapping social media. What are some ways scale plays a role in social media mapping?
- How would you propose to show tens of thousands of messages on a map so that you could actually do something with this sort of data?
- What real-world tasks do you think can be accomplished (at least in part) by using social media maps?
Summary and Final Tasks
In this lesson, you've seen how to modify the Google Maps user interface, open info windows when markers are clicked, implement a custom marker icon, and code the addition of line and polygon overlays. To this point, we've only dealt with a small number of points and have been able to hard-code their locations in our JavaScript code.
In the next lesson, you'll learn how to handle a larger number of markers in a more realistic way by storing their attributes in an XML file. You'll also learn how to add a sidebar that lists the names of your markers and how to use the API's address geocoder.