Lesson 3. Working with R
Motivate...

What role do tools play in your daily life? Perhaps you might respond, "I'm not really a handy person... I don't use tools very often." Well, I'm not just talking about the hammer or screwdriver kind of tools. If you search for a general definition of a tool, you might run across something like the following: "A broader definition of a tool is an entity used to interface between two or more domains that facilitates more effective action of one domain upon the other." (definition from Wikipedia). What does this mean, exactly? One simple interpretation is this, "A tool makes a particular task easier". Think about it. Everything that you use to make something easier is a tool. When you clean your teeth, you use a tool. When you communicate with someone, you most often use some sort of tool. When you want to collect and analyze information, you use tools. Indeed, you are surrounded by a multitude of tools that you use without even thinking about it.
If we are to make sense out of the mountain of weather data available to us, we are going to need some tools specifically designed for this task. There are certainly some excellent data analysis tools available. Perhaps you even make use of them now. As I mentioned in the orientation material, we are going to use the open-source statistical package "R" (You should already be somewhat familiar with how R works). Before we dive into using "R", first let me give you my philosophy on using statistical tools such as this...
- This is not a programming course. The purpose of this course is to get you analyzing data, not teach you to become an "R" programming expert. Indeed, you may explore all you wish, but you need do so only as you feel comfortable. "R" is a tool and we will use it as such. Think of "R" as just another electrical appliance. I'm sure that you know of someone who can't rest until they take that appliance apart and understand how it works. The rest of us just want to know how to use it. You are free to treat "R" in the same manner -- just use it, or take it apart and learn everything there is to know about it.
- That said, you must become comfortable using R. As I have said, R is especially designed for data analysis.The software contains some powerful tools that you will learn to use, not only in this course, but in the courses that follow. Some folks ask me why they can't just use Excel. Indeed, Excel can handle some of the tasks that we will be performing early on, but at some point relatively soon in this course, our needs will far exceed Excel's capabilities.
- In learning R, know that it is OK (even encouraged) to copy the commands that I provide. Since "R" is open source, users from all over the world have designed and shared some very useful extensions for analyzing almost anything you can imagine. I will show you how to find and make use of others' efforts to help solve your own problems.
- If you are an "R" super-user, feel free to use your own workflow. There are many different ways to do the same task in "R". Perhaps you know of a better way than I present in the lesson material. You are welcome to continue using that method (you might even consider sharing it with the class).
I hope this allays any remaining uneasiness you might have about learning programming. Remember that you can always turn to me or your fellow classmates if you lose your way.
"R" you ready? Read on!
Lesson Objectives
After completing this lesson, you should be able to:
- execute scripts, load data and perform simple manipulations in R;
- use R to create simple and sophisticated 2D plots;
- use R to plot histograms and box plots;
- create image and contour plots in R;
- load and use custom library plotting tools for specialized data sets;
- describe several methods for incorporating (or excluding) missing values from data;
- describe methods for transforming data which might be easily interpreted due to its values; and
- discuss approaches for debugging R script which may not be working correctly.
First Steps: Loading Data
Prioritize...
After completing this section, you will have executed your first script in R-Studio. NOTE: If you have not completed the lessons in "swirl" [5], I suggest you do that now.
Read...
In most of the tutorials that you have explored (especially the "swirl" examples), you entered every command in the console window. This approach is occasionally useful when we want to query an previously-loaded dataset, or when we want test a command or procedure. However, most of the time, we are going to place all of our commands in an R-script file (mainly because we don't want to have to retype every command each time we want to perform some sort of calculation). Secondly, saving everything in script files means that we can retrieve processes created for previous tasks -- to be either reused or modified to fit your needs.
A word of advice!
You will find that we will constantly be building on (or reusing) snippets of R-code. You do not want to be reinventing the wheel every time. Therefore, I suggest keeping an organized directory structure of R-script files (for example, by course and lesson perhaps) that have explanatory filenames (e.g., basic_scatterplot.R; not, my_code.R). Furthermore, I suggest that you have a few lines of comments at the beginning of each script that explains what the code does (and allows for easy searching). This will help tremendously if you need to find a particular piece of code sometime in the future -- and you will, trust me. You might also consider storing this directory in the cloud to both keep it safe and also allow access from various computers. There are several free cloud services that give you plenty of storage space.
Once you've set up a place to put your R-scripts, let's create your first one. Open up R-Studio and select "File > New File > R script". Next, select "File > Save". Save the script in the folder structure you just created and name this script "first_script.R". Notice that after you save it, the name appears in the tab [6]. Now, copy and paste the code below into your new script (remember to save it afterwards).
{kind=link}
# assign some variables
x <- c(1:25)
y <- x^2
z <- seq(1, 21, by=2)
rand_nums <- runif(100, min=-1, max=1)
my_colors <- c("red", "blue", "green")
I know, since you've completed the swirl tutorials, you are familiar with the commands above. If you can't quite remember, recall you can always type ?<command> in the console window to find out more about a particular command. Give it a try on the command runif() to learn more about it (Of course, you could also just Google: "R runif" as well. Try it!). To execute this bit of code, click on the "Source" button [7] in the upper-right corner of the script window. After sourcing the script, you should notice that in the upper-right panel you should see a list of values for x, y, z, rand_nums, and my_colors. You'll find the information in the environment panel helpful when checking to see if your code is working like you'd expect. Notice that the panel shows you what variables are currently being stored by R, how many elements they contain, what "type" of data (numbers, characters, integers, etc.) each variable contains, along with some values.
{kind=link}
Return to the script and focus your attention on variable "y". In the assignment statement, we defined "y" as the square of variable "x". In many programming languages, "x" would be considered an array. Therefore, to perform calculations on "x" you would have to loop through each value of the array sequentially. Remember however, that R performs what we refer to as Vector Arithmetic. When you add two variables (say, x + y), R interprets this as adding the vector "x" to the vector "y", term by term. R's approach to variable arithmetic saves us a tremendous amount of time because we don't need to loop over all the values for every computation we need to perform. Instead, we simply tell R what to do, and the program figures out how to do it. (Review Lesson 4 of the "swirl" tutorial for more information on R vector variables.)
Importing Data From a File
Now, you might have guessed that we could never enter the vast amounts of data we need into R using assignment statements like we just did above. So, let’s explore how to import data into R from a file. Start by saving this comma delimited file, UNV_maxmin_td_2014.csv [8], to your local machine by right-clicking the link and selecting “Save Link As…”. Save your file to the same folder that contains the script you created above.
Add the following line of code to your R-script file that you have open:
mydata <- read.csv("UNV_maxmin_td_2014.csv")
Now, source the file. You probably received an error telling you that R couldn’t find the file. This is because we only specified the filename the we want to open, not the entire file path. You can specify the entire path like this:
mydata <- read.csv("C:/Files/Meteo810/Lesson3/R_code/UNV_maxmin_td_2014.csv")
Your path will be different, of course, but you get the idea.
Using the full path name can be useful in some instances (you can even specify HTTP or FTP addresses). However, most of the time, I suspect that you will find typing all the path names tiring. Never fear! You can just tell R to use a default "working" directory whenever it looks for files. You can find out what the current working directory is by typing: getwd() in the console. To change the working directory, you use the command setwd(<directory>). You can use this command either in the console or right at the top of your script. For example, modify your script by adding a line containing setwd():
setwd("C:/Files/Meteo810/Lesson3/R_code/")
mydata <- read.csv("UNV_maxmin_td_2014.csv")
Notice above that we use the backslash (like an Internet address) even if we have the Windows OS (which uses the "\" to designate file paths). If you are uncomfortable figuring out the path to a particular folder, R-Studio offers an even easier way to set the working directory. You can set the working directory by selecting (Session->Set Working Directory->Choose Directory…) from the main menu of R-Studio. Once you point R-Studio to the proper directory, try re-sourcing the original code (with just the filename). If you don't get an error in the console window, you did it correctly.
Before moving on...
Take a moment to explore the options available for the read.csv() command. Type ?read.csv() into the R-Studio console or Google "R read.csv". Here's some documentation [9] describing read.csv() and its sister functions. Note the host of arguments that you can pass the function. You can skip rows, rename columns, and recast the datatypes, just to name a few.
Now that you have loaded the data file, examine the Environment tab in the upper-right panel [10]. You should see a new variable called “mydata” located under a the new heading "Data" instead of "Values". This variable is referred to as a dataframe. Dataframes are used for storing tables of values in lists of equal-sized vectors. In R-studio, you can expand the dataframe by clicking the little blue arrow directly in front of the name. This gives you information about each variable in the dataframe. For example, you’ll note that it contains three variables: date, max_dwpf, and min_dwpf. You can also view the data in table format by clicking on the grid icon located to the right of its name in the Environment tab. This gives you a spreadsheet view of the dataframe where you can examine, sort, and filter the data (but you cannot edit it).
Now that we've loaded some data, let's look at how we might interact with it. Read on.
Accessing and Manipulating Data
Prioritize...
In this section, you will learn how to import comma-delimited datafiles into R. You'll also learn some ways to begin exploring the data.
Read...
So, now that we have some data loaded, let's look at how we might learn some things about our data. To help me walk you through some basic R, I have set up a DataCamp session below. DataCamp will allow you to run R right from this webpage (pretty cool, don't you think?). Start by clicking the "Run" button to source the code. When you do so, DataCamp executes the R-code and switches to the Console panel. Now, let's look at the data...
First, you can view any variable simply by typing its name in the Console (try typing "y" at the Console prompt and hitting "Return"). You should see the value of the variable "y" displayed. You can look at a specific value(s) of "y" by adding square brackets containing an expression. Try the following commands: y[3], y[3:4], y[seq(1,9, by=2)]. We can also look at values of a variable that meet certain criteria by using the which() command. For example, try this command (don't type the command prompt ">"):
> rand_nums[which(rand_nums>0)]
You'll find this type of data access to be very powerful. The which() command produces a vector of indices that satisfy the condition (in this case, all the indices of rand_nums whose value is greater than zero. The output indices that satisfy the condition, which if used inside the "[...]" retrieve the actual values of rand_nums that are greater than zero. By the way, you can make the condition statement as complex as you like, allowing you to filter data in numerous ways. And remember, you can use these commands not only in the console, but also in a script, storing the values in new variables as well.
Solve It!
In the DataCamp window above, can you come up with a command to count the number of random numbers between 0.25 and 0.5? There are lots of ways to do it. Hint: You might want to look up the length() and sum() commands.
Here are some possible answers:
> length(rand_nums[which(rand_nums>0.25 & rand_nums<0.5)]) > length(which(rand_nums>0.25 & rand_nums<0.5)) # Why does this work? ...Look at the output passed to sum() > sum((rand_nums>0.25 & rand_nums<0.5))
Working with Dataframes
Dataframes can be accessed in ways that are similar to simple variables. In the DataCamp window below, I have loaded the .CSV file from the last section into a dataframe called mydata. Switch over to the Console tab and start with the command: str(mydata). This command displays the structure of the dataframe in much the same format as the environment tab in R-studio. You can see a listing of the variable within the dataframe, the variable types along with some sample data.
Remember that dataframes are basically tables of data (if you don't remember, you might want to revisit the Swirl Tutorial: Lesson 7). In some cases, we might want to look at a sampling of the dataframe across all of its columns. Below are some commands for you to try in the console window (remember to omit the ">").
# list the variable names (header) of mydata > names(mydata) # list the first 5 lines of mydata > head(mydata, n=5) # list the last 5 lines of mydata > tail(mydata, n=5)
We can also access data within a dataframe a few other ways. First, if we want just one variable (a single column), remember that we use the "$" character. For example, mydata$date. This command selects only the column named "date" (if you type that in the Console, R will print out the values in that column. Try it!). You can also use the bracket [...] notation that we learned above. The reference mydata[1] is the same as mydata$date because "date" is the first column in the dataframe. To access individual data values, we can use a combination of the $ and [...] notations. For example, the third date value can be found with mydata$date[3], or mydata[3,1]. (note that the 2-D index is in the format [row, column]).
The dataframe mydata contains the daily minimum and maximum dew point temperatures for each day in 2014 at the University Park Airport (State College, PA). In case you are unfamiliar with dew point, you can read this article in Wikipedia [11]. Meteorologists use dew point as a proxy for the amount of water vapor in the air because, unlike relative humidity, its value is not affected by air temperature. Let's look at some other commands we can use to query this dataframe. The first thing that you might want to do is look at some bulk characteristics of the data. For example, try out this command in the console tab of the DataCamp window.
> max(mydata$max_dwpf)
This command asks for the maximum value of the column (“max_dwpf”). Notice that the “$” is again used to select a variable from a dataframe. I get a value of 75.2 F. Note that we also get the same result with the commands: max(mydata[2]) and max(mydata[, 2]). This is because "max_dwpf" is the second column in the dataframe. I should comment that, for clarity's sake, using the actual name of the column is preferable to just its number. Using the column's name makes it immediately clear what we are calculating when looking at the code.
How about the date on which this maximum value occurred? Now try:
> mydata$date[which(mydata$max_dwpf==max(mydata$max_dwpf))]
Can you see what this command does? First, we find the position in the data where the dew point temperature equals the maximum value. The statement: which(mydata$max_dwpf==max(mydata$max_dwpf)) returns a value of 182 (the max occurs on the 182nd row). Now we can retrieve the specific date by placing the which() statement inside the mydata$date[…] selector. You could also use the following command:
> mydata$date[which.max(mydata$max_dwpf)]
Note, however, the function which.max() always returns the first instance of the maximum value. If the data had two maximum values, only the first command above will tell you, not the second. I point this out simply to emphasize that there are many ways to accomplish similar things in R. However, you have to make sure that the command does exactly what you think it does.
Let’s perform a more complex calculation. For example, let's count the number of days where the daily maximum dew point was between 40 F and 50 F:
> sum(mydata$max_dwpf <= 50 & mydata$max_dwpf >= 40)
or, the number of days where dew point temperature changed by more than 30 degrees during the day:
> sum((mydata$max_dwpf - mydata$min_dwpf) > 30)
I hope that you are beginning to see how powerful R can be. Let’s look at one final example. What if we wanted to know when such large changes in dew points occur (as organized by month)? Here’s the code to find out:
> table(strftime(mydata$date[(mydata$max_dwpf - mydata$min_dwpf) > 30], "%b"))
This command looks for large differences in the maximum and minimum daily dew point (greater than 30F), gets the dates associated with those differences, extracts and formats the months (learn more about strftime [12]) of the occurrences, and finally places the results in a frequency table. Remember that you can always look up each one of these commands in R-studio (or on the web for that matter) to find out what it does. You can find lots of information and examples by Googling... "R strftime", for example.
Here’s the output…
Apr Dec Feb Jan Mar 3 1 1 5 5
Pretty cool, huh? Can you think of a meteorological reason why the dew point temperature (the moisture content of the air) would change drastically during the day?
We'll look at many other ways to explore large data sets in future lessons. Now, however, let's resume our brief survey of R with a look at other ways of managing data. Read on.
Managing Data
Prioritize...
In this section, you will learn how to manage variables in R by changing data classes, formatting times, and adding and deleting columns/rows from dataframes.
Read...
We've looked at how to query variables and dataframes to retrieve values but we haven't discussed ways that variables and dataframes can be modified. Let's return to the DataCamp window where we load the dew point data file into the mydata dataframe (click "Run" to start the session).
Let's look at the structure of the dataframe using the following command (entered in the R Console window):
> str(mydata)
This command gives you the same information as the Environment tab in R-studio. Note that the $max_dwpf and $min_dwpf have a data class of "numeric". (You can also verify this fact with the command class(mydata$max_dwpf)). The "$date" variable however has a strange class "Factor". What is a "factor"? You might want to read about them in this documentation page [13]. Basically, a factor variable is a list of indices that point to a lookup table (called the "levels" table in R). You can think of a factor variable as a finite list of categories rather than actual numbers (called a "categorical variable" in statistics). The problem is that factors are not sequential variables and thus don't always play nice with other R functions (like plots, for example). In many cases, we are going to want to change these factor-type variable to something more manageable. So, how can we transform one class of variable into another?
The process is rather easy, but does come with some caveats. R has a set of functions having the form: as.numeric(...), as.integer(...), as.character(...), etc., that can transform one class of variable into another (where possible). For example, try the command:
# Convert max_dwpf to characters and display the first 5 values > head(as.character(mydata$max_dwpf))
Notice that all the values for $max_dwpf are now surrounded by quotes. This means that they are no longer numbers, but strings of characters instead (We can no longer perform any mathematics on them. For example, try: max(as.character(mydata$max_dwpf)). Conversions from numbers to characters are pretty straightforward (everything converts, no problem). The opposite however, is not always the case. Let's consider the following scenario (enter just the commands in the console window):
# Create a variable of character data
# This is what you might get after reading a data file
# with mixed numbers and non-numbers.
> temperature <- c("25", "-2", "10.5", "M", "16*")
# Try doing some math... Nope, can't do it
> temperature/10
# Now convert the temperature to numbers
> temperature <- as.numeric(temperature)
# Look at the values... Notice that some values
# cannot be converted and are assigned 'NA'
> temperature
# Try doing some math now...
> temperature/10
Notice that you must be careful when changing data from one type/class to another, particularly when you have mixed types assigned to one variable. Factors can be particularly troublesome because the values stored in a "factors" variable are numbers pointing to a look-up table, not actual values. To see what I mean, run the DataCamp console below. This console loads a data file called daily_obs_may2016.csv [14] (I linked to the file in case you want to download and play with it in R-Studio).
First, after running the console, use str(daily_obs) to look at the loaded dataframe. Note the $PRCP variable which was loaded as a factor. By using the levels(daily_obs$PRCP) we can see all the possible values of the variable (and why the variable is listed as a factor... the "T" stands for "trace of precip" and is represents values less than 0.01 inches). So, how do we convert this variable into something we can use (find the maximum value, for example)? First, let me say that you can't just convert using as.numeric(daily_obs$PRCP). Try it... what do you get? You do, in fact, get numbers, but those numbers represent the position of the values in the look-up table. Now try: as.character(daily_obs$PRCP). This gets you closer, doesn't it? Now the output is a list of the proper values pulled from the look-up table, but they are still character values, not numbers. Let's add the as.numeric(...) conversion to what we have and take a look at the output. If you want to see how some other data scientists solved the "Trace" problem, you can check out their paper, published in the Journal of Service Climatology (2013) [15],
> as.numeric(as.character(daily_obs$PRCP))
Now we've got what we want, but we've lost something in the process (the "T" observations have been transformed into "NA"s). NA is a bit misleading because the observation is not missing. In fact, a "Trace" is perfectly valid observation. So what to do? Well that's up to you. If it suites your purpose, you might leave those values as NA (if you are tabulating a "Total Precip", for example). Or, you might assign the T's a numerical value before converting (0.00 or 0.001 perhaps). Or, you may wish to create a "flag" column in the dataframe which stores a letter designating the type of observation (Number, Trace, or Missing) for each value. As the data scientist, you must decide how you are going to treat data that is not so nicely behaved. Just be cautious! My mantra is to always perform operations that preserve the original data and that only alter that data in a manner consistent with the type of result I need to compute.
Now that we've dealt with the factors, let's talk about dates. If you noticed, the dataframe mydata contained dates in the form of factors, while daily_obs dates were read in as integers. Both of these formats are not acceptable -- dates should be dates! For dates that are already in character format (and in some sort of recognizable date format), you can use the as.Date(...) function. For example, you might want to recast the mydata$date variable like this (remember it starts as a factor):
> mydata$date <- as.Date(as.character(mydata$date))
The function as.Date(...) is quick and dirty, but not all that powerful. In the daily_obs case, the dates data are listed as integers (namely because they don't have any non-digit characters). This format is troublesome for as.Date(...) because R thinks that these numbers represent a time (in seconds) from some point of t=0 (called the origin). So, to convert these times (and in a general sense, ALL dates/times), we are going to use the even more powerful function strptime(...) [16]. Here's the command to try:
> daily_obs$DATE <- strptime(daily_obs$DATE, "%Y%m%d", tz="EST")
Notice that strptime(...) can take almost any input form (number, character, even factor), it can handle dates and times in a format of your choosing, and can even embed timezone information. It creates a data class called POSIXlt which is a one-stop-shop for storing date/time information. You have already encounter its sister function, strftime(...), which is used to format output of POSIXlt objects in much the same way. Take my advice and format all of your time/dates using strptime(...).
Manipulating Dataframes
You've probably figured out that dataframes are nice, compact structures for storing data. Ideally, we are going to want to keep all similar data together rather than having to keep track of several independent variables. Adding columns to an existing dataframe is easy (Run the DataCamp session below before continuing).
Let's say that we wanted to convert the dew point temperature in mydata to degrees Celsius instead of Fahrenheit. We could issue the following command (don't run it):
# Don't run me!.... > mydata$max_dwpf<-(mydata$max_dwpf-32)*5/9
However, this will overwrite the original data. Instead, let's create a new column in mydata called max_dwpC.
# This is better... it creates a new column # without overwriting the original data. > mydata$max_dwpC<-(mydata$max_dwpf-32)*5/9
You can remove columns from a dataframe as well by simply assigning the NULL values to an existing column like such:
> mydata$max_dwpC<-NULL
Note that NULL is not the same as NA. Assigning a variable to the NULL state will remove it from R's memory space. The value NA is treated as an actual value even though it's usually used to signify an undefined or missing value.
What about adding and deleting rows? You guessed it... that's pretty easy too. To add rows, we simply use the command rbind(...) to bind together rows from one dataframe with rows from another. Look at the following series of commands:
# start with the original 'mydata' (not the one with added columns)
# create a new dataframe with two rows of data
> mydata2 <- data.frame(date=c("2015-01-01","2015-01-02"),
max_dwpf=c(9.1, 12.6), min_dwpf=c(2.7, 1.6))
# bind the new rows to the original dataframe
> mydata <- rbind(mydata, mydata2)
# look at the result (the last 10 lines)
> tail(mydata, n=10)
Note that the two dataframes must be the same size (same number of columns). Therefore, if you added a Celsius column to mydata, you must also add that variable to mydata2. Otherwise, you will get an error.
Deleting rows, on the other hand, is a bit different. Instead of directly deleting rows, we need to tell R what rows we want to keep, and then reassign that selection to the original dataframe. For example, let's say that we want to delete the rows added in the commands above.
# Select only the first 365 rows and delete the rest > mydata <- mydata[1:365,]
This method of parsing a data set is quite powerful when combined with the selection functions we've previously discussed. For example, the command:
> mydata <- mydata[which(mydata$max_dwpf > 20), ]
deletes all rows in the dataframe where the max dew point is not greater than 20F. We might also want to use the function is.na(...) to delete rows that contain missing or corrupt data. We'll discuss what to do with data sets that contain missing values at the end of this lesson (it's more involved than you might think).
For now, let's move on to how we might display our data. Read on.
Plotting Basics
Prioritize...
After finishing this section, you should be able to create a simple plot using various points and lines. Emphasis should be placed on learning how to create proper titles and axis labels.
Read...
Now that you know your way around data and dataframes, let's spend some time talking about how to present that data in meaningful ways. In this course, we won't get into any heavy statistical analyses; instead we'll focus on retrieving and presenting data in a way that can answer basic questions. Certainly, the first step in presenting data is simply a visualization in the form of a plot.
Let's start with an example using the data from the daily_obs data set:
Click the run button to see the plot produced by the script I provided. Note that the plot window is a bit cramped... you can hit the pop-up button [17] to produce a bigger floating window.
I encourage you to switch over to R-Studio at this point and run the same script. Create a new script file in R-Studio and paste in the code from the DataCamp window. Make sure you swap out the read.csv statements for the data file you saved locally (daily_obs_may2016.csv [14]). You'll notice that the lower right panel of R-Studio switches to the Plots tab and automatically displays the same plot. There’s not much to this basic plot. In fact, it's not very helpful, is it? Before we tackle some more complicated data sources and plot types, review some of the rules of good data communication.
In the last lesson, we learned the importance of crafting a message and using data to communicate or support that message. Indeed, it's true that a picture is worth a thousand words, but only if that picture is in focus and is properly composed. Remember that the process begins with choosing the correct display of the data. In addition, your graphs or charts should include the following elements...
- Every graph should have a title which clarifies what is being displayed.
- Axes should be labeled (with both a title and units where appropriate).
- For graphs with multiple sets of symbols or lines, use both color and symbol/line type to distinguish each set (provide a legend as well).
- An appropriate range for each axis such that data are clearly visible and are in no way misleading (check out this article on misleading graphs) [18].
Let’s examine how each of these key elements can be added to a graph we just produced.
In your R-Studio script, replace the last two lines with the following code and run (source) it:
# Find the range for the independent and dependent variables
xrange<-range(daily_obs$DATE)
yrange<-range(daily_obs$TMAX,daily_obs$TMIN, na.rm=TRUE)
# Create the plot... but this time with no data
plot (xrange,yrange,type="n",
main="Maximum and Minimum Observed Temperature",
sub="(May 2016, University Park, PA)",
xlab="Date",
ylab="Temperature (F)"
)
Check out the plot produced by the code above [19]. Let’s look closer at the lines we added. First, there are the variables xrange and yrange that contain two numbers each that are the maximum and minimum values of any variables passed to the range(...) function. Now, if I wanted to plot a single variable (say the maximum temperature), I could just pass this variable to the plot function (the axes are set by the x and y variables you want to plot. But if I want to plot both max and min temperatures and I want the y-axis to accommodate both sets of values, I first must pass the variables to the range(...) function which calculates the total range for both variable. Then I pass that value to the plot(...) function. Another trick that I often find helpful is to create a blank plot first (that's what the type=”n” does in the plot command) and then add the data in a second step. Breaking a process into discrete steps gives you more control, especially in situations where you are plotting more than one set of results. Ultimately, how you go about producing plots is up to you. Please take a moment to peruse this article [20]which reviews all of the various scatter-plot types available.
I also take the opportunity to add the plot title (“main”), subtitle (“sub”), the x-axis label (“xlab”) and the y-axis label (“ylab”) at this time. These commands can also be added separately (outside the plot command) and have a long list of formatting options.
Now, let’s add some data to our graph. Add the following line to the end of your script and run it:
# Add a scatter plot of TMAX vs time with red, empty circles points(daily_obs$DATE,daily_obs$TMAX,pch=1,col="red")
Here we are plotting points (TMAX versus date). The “pch” property specifies the type of point (the value "1" is an non-filled circle) and col=”red” dictates the color. Now add:
# Add a line plot of TMAX vs time with a red, solid line lines(daily_obs$DATE,daily_obs$TMAX,lwd=2,lty=1,col="red")
Here we are drawing a solid (lty=1) red line of width (lwd) of 2 for the same data (graph [21]). If you don’t like the fact that the line over plots the points you can change the line to:
lines(daily_obs$DATE,daily_obs$TMAX,lwd=2,lty=1,col="red",type="c")
Or you can change the points to be solid. Try changing the “points” command to:
points(daily_obs$DATE,daily_obs$TMAX,pch=19,col="red")
Now, add another series of points, lines, or both to your graph for the daily_obs$TMIN series (use: pch=17, lty=3, col= "blue"). Here is a great reference if you want to explore the different types of points and lines available [22].
Finally, let’s add a legend to our graph.
# Draw a legend
legend ("topleft", inset=0.03,
c("Max T","Min T"),
col=c("red","blue"),
pch=c(19,17),
lty=c(1,3),
lwd=2 )
These are just a few of the options you can use to customize a legend. The “topleft” and “inset” properties position the legend, then follow the labels, colors, plot symbols, line types, and line thicknesses. You can use this code block as a template, or you can play around to find one that you like. Remember, if you want help on a particular command, you can always type: help(<command>) or ?<command> in the console window. For example, type: help(legend) in the console window to see information on how to create a legend. In R-Studio, the help dialog tab opens with information on your requested topic. Here's my final graph [23] as exported from R-Studio. Make sure that you can duplicate a graph like this in R-Studio before moving on to the next section.
You may be thinking, "Wow, that's a lot of work to make a simply scatter/line plot... Why not just push a few buttons in Excel?" You're right to some degree... making simple plots may in fact be easier in a package such as Excel. However, don't rush to judgment just yet. R's power and flexibility will become evident as we progress; soon our data needs will far exceed Excel's capabilities. In the next section, we'll look at more possibilities for displaying data.
Read on.
Graphs Galore
Prioritize...
In this section, you will learn how to create more complex plots, including graphs for comparisons and graphs using special elements.
Read...
Graphs Making Comparisons
Previously, we saw how R could be used to graph simple relationships. Now, let’s examine how we might present more complex ideas. For these exercises, we'll be moving to R-Studio exclusively. You'll need to save the T_compare2017.csv [24] data file to your R working directory. This file contains the daily maximum temperatures for three locations in central Pennsylvania [25] (State College - SCE, Lewistown - LEW, and Philipsburg - PLB). We want to see how closely the observations from these three relatively close stations agree. Open a new R-script file and load the data using the following code:
# you can find this code in: max_temp_compare.R
# This code plots the comparison between two station's
# temperature observations
# read in the dew point data file
T_compare2017 <- read.csv("T_compare2017.csv", header=TRUE, sep=",")
# tell R about how the date column is structured
T_compare2017$Date<-strptime(T_compare2017$Date, "%m/%d/%Y")
Now, let's plot a comparison of daily maximum temperature for State College vs. Lewistown using the following commands:
# get the full range of all the data
data_range<-range(T_compare2017$SCE_T,T_compare2017$LEW_T,T_compare2017$PLB_T)
# force a square plot
par(pty="s")
# set up the plot
plot(T_compare2017$SCE_T,T_compare2017$LEW_T, type="n",
xlim=data_range,
ylim=data_range,
main="Comparison of 2017 Daily Maximum Temperatures\n(State College vs. Lewistown)",
xlab="State College Temperature (F)",
ylab="Lewistown Temperature (F)")
# plot the points
points(T_compare2017$SCE_T, T_compare2017$LEW_T, pch=16)
# plot a comparison line with intercept=0 and a slope of 1
abline(0,1)
# Note you can also use the line below to replace the
# second line in the main title. It give you slightly
# better control... notice I decreased the font size.
# Uncomment the line below.
#title(main = ("(State College vs. Lewistown)"), line = 0.5, cex.main = 0.9)
Here is the graph that this code produces [26]. Before we talk about what the graph actually shows, let's look at a few new commands and parameters introduced in this code snippet. First, notice that I calculate the total range of all the temperature data. The range(...) function returns the absolute maximum and minimum values from a series of variables that you provide. That range is then used in the xlim and ylim plot parameters to set the axis limits on the plot. For comparison plots, equal axis values make for easier interpretation. I also fix the plot to be square using par(pty="s"). Next, notice that I have split the title into two lines using a "new line" character (\n). You might want to use this technique when you have a long title (alternatively, you can use the title(...) function to add subtitles). Finally, notice that I plotted a reference line using the abline function [27]. This function plots a line with a specific slope and intercept.
Now, on to examining the plot itself... what do you notice? Certainly there is alignment between the two observations; however, notice that Lewistown is consistently warmer than State College (by an average of 4 degrees). The reason? Well, I would say that some of the discrepancy would be due to State College's increased elevation (~600 ft higher), but we would need to look at other factors such as site selection to really understand the different. The real question is, could we use Lewistown temperature data as a proxy for State College if we needed to? What about Philipsburg? Change the plot script to compare State College and Philipsburg temperature data to judge for yourself.
Graphs Using Polygon Regions
Before we get into creating some more sophisticated graphs, I though I would show you how to make the following graph climatology graph...
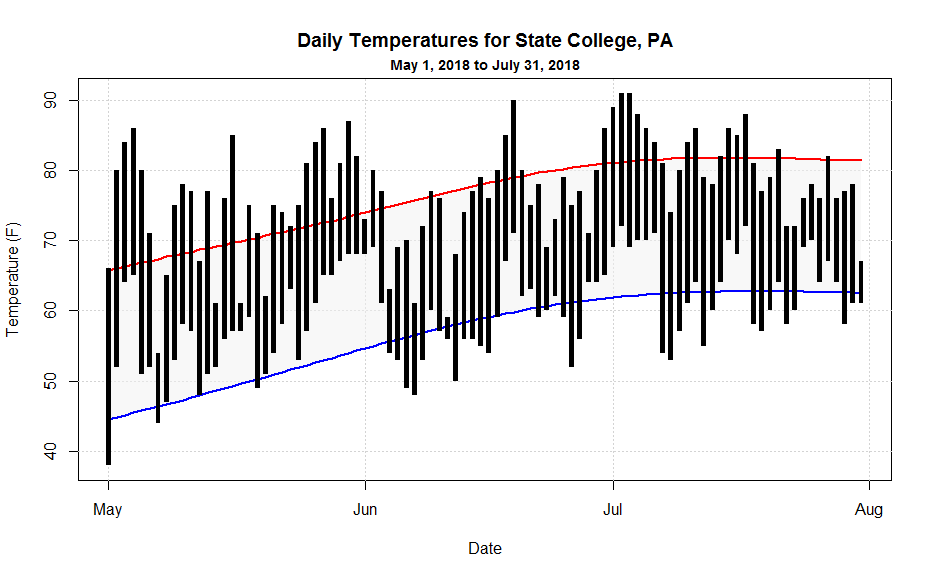
In this graph, I'm doing several interesting plots that you might make use of when looking at your data. Grab the may_july_2018.csv [28] data file and then let's walk through the code:
# you can find this code in: climatology_graph.R
# This script plots a standard climatology graph showing
# max/min temperature observations along with normals
# read in the data file
may_july_2018 <- read.csv("may_july_2018.csv", header=TRUE, sep=",")
# tell R about how the date column is structured
may_july_2018$Date<-strptime(may_july_2018$Date, "%Y-%m-%d")
# I need to make the graph fit all of the data, so I will set up
# the plot using the "range" command
X_range<-range(may_july_2018$Date)
Y_range<-range(may_july_2018$MaxTemperature,may_july_2018$MaxTemperatureNormal,
may_july_2018$MinTemperature, may_july_2018$MinTemperatureNormal)
# standard plot set-up
plot(X_range,Y_range, type="n",
main="Daily Temperatures for State College, PA",
xlab="Date",
ylab="Temperature (F)" )
# adding a subtitle
title(main = ("May 1, 2018 to July 31, 2018"), line = 0.5, cex.main = 0.9)
In this first chunk of code, I first grab and condition the data. Next, I'm going to set up the plot, but instead of using a one specific variable to base the plot on, I calculate the total range of all y-axis variables then make the plot based on that range (I have to do the same with the x-axis variable to keep the inputs the same size). If you don't do this, then likely part of your data will not be shown. Finally, I show you how I made the subtitle (as we just discussed). You're also welcome to use the "\n" method as well.
Now, let's work on the plot...
# plotting some gridlines, notice how I plotted the date axis
abline(h=seq(40,90,10),col = "lightgray", lty = "dotted")
abline(v=seq(may_july_2018$Date[1], by="month", length.out = 4),col = "lightgray", lty = "dotted")
# draws the shaded region between the normal min and max temperatures
polygon(c(may_july_2018$Date,rev(may_july_2018$Date)),
c(may_july_2018$MaxTemperatureNormal,rev(may_july_2018$MinTemperatureNormal)),
col=rgb(0.85,0.85,0.85, 0.5), border=NA)
# plots the normal min and max temperature lines
lines(may_july_2018$Date,may_july_2018$MaxTemperatureNormal, lwd=2, col="red")
lines(may_july_2018$Date,may_july_2018$MinTemperatureNormal, lwd=2, col="blue")
First, we add some grid lines using the abline command. Note that when drawing horizontal or vertical lines, you can just use "h" and "v" respectively. Also, note how I use the seq(...) command to draw a series of lines (even for the "date" axis!). Next, I draw the the shaded polygon region that bounds the normals. I pass the function an ordered sequence of x and y coordinates. Note that I first do the dates in ascending order and then (for the return trip) in descending order by rev(...) the variable. I follow suit with the normals data so that they match the dates. Finally, I draw two colored lines for the normals.
Now I'm ready to draw the black rectangles that represent the observed temperature range for each day. The tricky thing here is that the width of the rectangles must be a function of time (seconds actually) because my x-axis is time. Because I wanted to be able to easily adjust the width of the bars, I first defined a variable that gave me seconds as a function of hours. This is a standard coding practice... anywhere you have a value, used in many places, that you might want to change, define it as a variable instead. That way, you can make one change to the variable and the value will be updated everywhere. It will make your life so much easier. Here's the final section of code:
# plots the rectangle bars for observed min and max temperatures
# notice that I define a bar width in seconds because the x-axis is
# a date.
bar_width=3600*7
rect(may_july_2018$Date-bar_width, may_july_2018$MinTemperature,
may_july_2018$Date+bar_width, may_july_2018$MaxTemperature,
col="black", border = NA)
Once you've played with this code and understand how it works, you're ready to move on to histograms and box-and-whisker plots.
Note:
Did you get a square plot when you tried climatology_graph.R? If you did, then the R-Studio graphics device is remembering the square comparison plot that you created earlier (remember the par(pty="s") command on line 16 of max_temp_compare.R?). Graphics settings are remembered as long as the graphics device is open. So, you can do a few things to clear out the square plot setting. First, you can "Clear All Plots" in R-Studio using the little broom icon in the plots toolbar. This resets the graphics device in R-Studio (but it also erases all of your plots). Or, you can add the line par(pty="m")right above the plot command (line 18). This switches the graphics device from making square plots to maximal area (default) plots. If you are curious, you can read more about R's many Graphical Parameters [29].
Histograms and Box Plots
Prioritize...
In this section, you will learn the "histogram(...)" and "boxplot(...)" commands to produce quick looks at the distribution of a data set.
Read...
Remember, in the last lesson, we discussed ways to visualize the distribution of large data sets without too much computational hassle. Namely, we looked at histograms and box plots. Let's look at some code.
Histograms
First, let's load the dew point data set (UNV_maxmin_td_2014.csv [8]) that we have used before. I realize that this data set may already be loaded in your R memory space, but unless the file is very large, I always have my script reload and re-parse the data. This prevents the data that may have been changed (in a previous exercise) from being used in my current calculations. I've learned the hard way to always start with "fresh" data. (I also suggest opening a new R-script file rather than just appending on to an existing one.):
# you can find this code in: histogram.R
# This code plots a histogram of daily differences in
# dew point temperatures.
# read in the dew point data file
mydata <- read.csv("UNV_maxmin_td_2014.csv", header=TRUE, sep=",")
# tell R about how the date column is structured
mydata$date<-strptime(mydata$date, "%Y-%m-%d")
Now add the following lines of code to plot the histogram of daily dew point difference.
hist_output<-hist(mydata$max_dwpf-mydata$min_dwpf, main="Distribution of Daily Difference Dew Point in 2014", xlab="Daily Dew Point Difference (F)", ylab="Number of Observations", las=1, breaks=10, col="green", xlim=c(0,60) )
Here’s the graph that you should see…
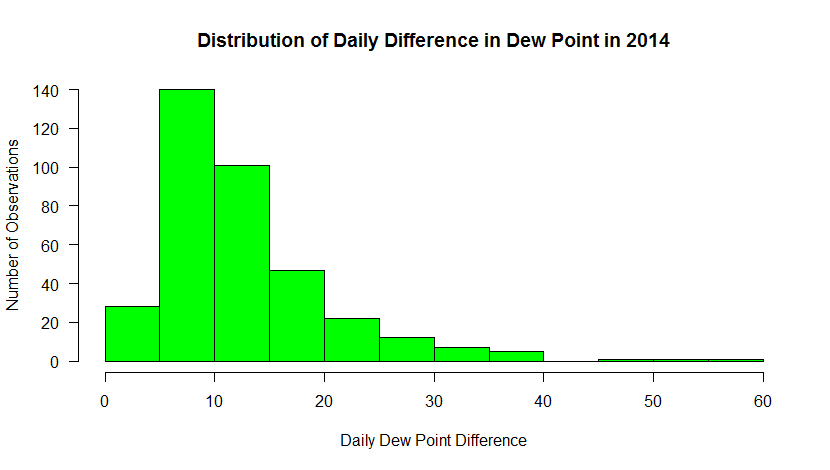
This histogram shows the frequency of occurrence for dew point observations that fall within select “bins”. You can control the number of bins with the “breaks” command. Breaks can be a number or a sequence of numbers. If you just specify a number, R makes a judgment on how to divide the data. If you use a sequence, you can precisely control how the data are distributed.
For example, substitute: breaks=20, in the histogram command. Now you can see counts for every 5 degrees [30]. Does this new graph communicate some different information than a standard time series graph? Later, you will learn more about distributions and how they can help you make inferences about the probability that a certain event will occur.
Note: I also added a new parameter, “las”. This sets the orientation of the tick labels. Play around with the values to see what happens (valid values are: 0, 1, 2, 3).
There's one more thing I wanted to point out. The hist(...) function not only creates a plot. Like many functions of R, the hist(...) returns a data structure that contains all of the precise values for the bins. I captured this information in the variable hist_output (remember, you can examine its contents by simply typing the name in the console or using R-studio's Environment tab. With this data, you can use the values to perform computations on the data, or add this information to the plot itself (like labeling values, etc). Adding a line such as...
text (hist_output$mids, hist_output$counts+5, labels=hist_output$counts, cex=1.2, col="black")
allows you to add custom text to your graph (here's my example [31]). You can read more about the text command [32] and play around with the settings if you wish.
Finally, allow me to show you one more bit of code that combines what we have learned so far. Substitute the following code for the single histogram plot command
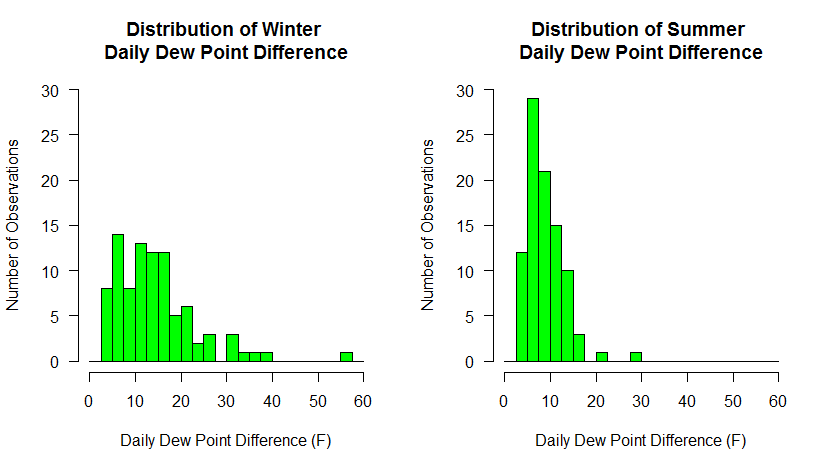
# make two plots... 1 row x 2 columns par(mfrow=c(1,2)) # calculate a column of dew point differences # BTW, I could have done this for the last set of histograms mydata$dwpt_diff<-mydata$max_dwpf-mydata$min_dwpf # plot only the differences in DEC, JAN, and FEB hist(mydata$dwpt_diff[mydata$date > "2014-11-30" | (mydata$date >= "2014-01-01" & mydata$date < "2014-03-01" )], main="Distribution of Winter \nDaily Dew Point Difference", xlab="Daily Dew Point Difference (F)", ylab="Number of Observations", las=1, breaks=seq(0,60,2.5), col="green", xlim=c(0,60), ylim = c(0,30) ) # plot only the differences in JUN, JUL, and AUG hist(mydata$dwpt_diff[(mydata$date >= "2014-06-01" & mydata$date < "2014-09-01" )], main="Distribution of Summer \nDaily Dew Point Difference", xlab="Daily Dew Point Difference (F)", ylab="Number of Observations", las=1, breaks=seq(0,60,2.5), col="green", xlim=c(0,60), ylim = c(0,30) )
Here we've done a couple of things. First, we've divided the plotting region into two panels (1 row by 2 columns). That means that each hist(...) call will go to a different panel, rather than one replacing another. Next, we have created a column in our data frame to hold the dew point differences. We could have done this at the very beginning of the histogram discussion but we do it now so that it makes the winter/summer selection easier. Finally, we make two hist(...) calls, using the technique we learned to partition the data. Make sure you understand how subsetting like this is accomplished... it is so powerful. To ensure that both graphs had the same breakpoints and axis scales, I specified the breaks explicitly with a sequence of numbers and I also added an explicit axis limits using xlim and ylim. Make sure you experiment with each of these new commands to see how they work.
Below are the graphs produced. What trends do you observe in the data? Do these graphs tell you something different about the data than the first set of graphs did?
Box Plots
Remember that box plots are also a nice way to look at distributions of data, especially discriminated by a third variable. In this example, we will look at the distribution of dew point temperature in State College by month for the year 2014. To begin, start a new R-script file, enter the following code and source it:
# you can find this code in: boxplot.R
# This code plots a box-and-whisker plot of daily differences in
# dew point temperatures.
# read in the dew point data file
mydata <- read.csv("UNV_maxmin_td_2014.csv", header=TRUE, sep=",")
# tell R about how the date column is structured
mydata$date<-strptime(mydata$date, "%Y-%m-%d")
# create a column of numerical months
mydata$month<-as.integer(format(mydata$date, "%m"))
# reset the plot area just in case you have just
# come from the two histogram exercise
par(mfrow=c(1,1))
boxplot(max_dwpf~month, mydata,
xlab="Month",
ylab="Daily Maximum (F)",
main="Daily Maximum Dew Point Observations for 2014",
las=1,
xaxt="n",
pars=list(medcol="red", whisklty="solid", whiskcol="blue", staplecol="blue")
)
# create custom axis labels
axis(1, at=c(1:12), labels=rep(month.abb, 1))
Your graph should look like the one below. If we look at the code, you will notice it resembles the histogram code with the exception of a few lines. First, there is the line that creates a new column in the data frame called "month". We parse the date column and extract a numerical representation of the month. We need this information because a box-and-whiskers plot needs to know how to partition the data. In this case, we want the max_dwpf variable to be binned by month and we indicate that by the expression: max_dwpf~month in the boxplot function call (the tilda symbol "~" is often used in R as a representation of the word "by"). A second addition is the line that contains the function: axis(...). This adds a custom axis to the bottom of the graph. Notice in the plot call, I have the command xaxt="n". This means to turn off the default x-axis so that I can add one of my own (try it without the custom axis to see what you get). You can learn more about the many ways to customize plots and axis values by simply Googling "R custom axis".
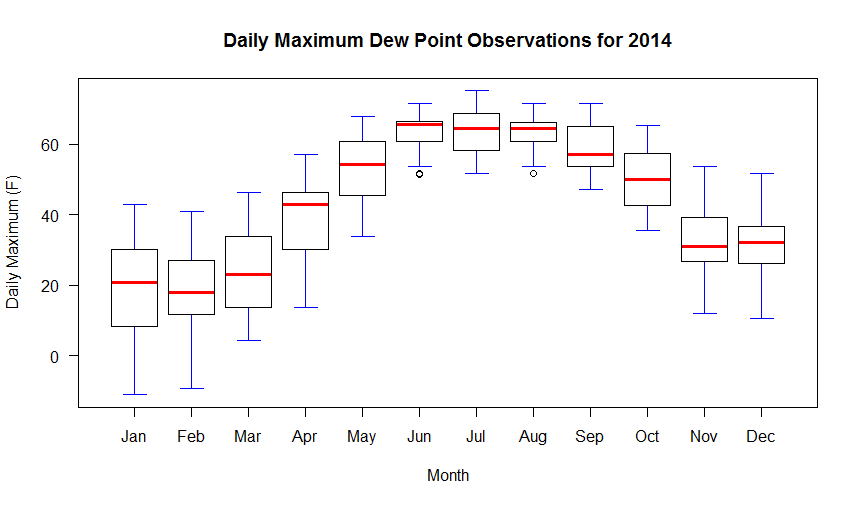
Remember that in a box-and-whiskers plot, the median is represented by a line running through the center of the box (in the code above I have set the median line to red). The second and third quartiles are defined by the top and bottom of the box. Fifty percent of the observations, therefore, lie within the box (the width of the box is called the interquartile range). The first and fourth quartiles are represented by the whiskers on either side of the box. An outlier is a point that lies more than one and a half times the length of the box from either end of the box. In R, outliers are shown as small circles plotted beyond the end of the whiskers.
Finally, know that you can also add lines and points to box graphs, just like you did to other kinds of plots. For example, if we wanted to plot the mean of the observations along with the boxes, you might add the following code:
# Calculate and plot the mean max dew point for each month points(aggregate(max_dwpf~month, mydata, mean), pch=18, cex=2)
The aggregate(...) function is a very powerful way to calculate simple statistics on columns of data. The result is a data structure that in our case provides the x and y coordinates for plotting our mean values for each month. Run the script again to see the means plotted as diamonds on top of the box plots [33].
Image & Contour Plots
Prioritize...
After completing this section, you will be able to plot data sets that contain two independent variables. Plots covered in this section are contour plots, filled contour plots, and image plots.
Read...
Up to this point, we have been working with data that only contains one independent variable (for example, temperature versus time). However, meteorological data is inherently spatial and often requires two or more independent variables. The simplest type of 2-D plot you might use to visualize this type of data is an image plot. Image plots essentially display pixelated values of a single dependent variable as a function of two independent variables (latitude and longitude, for example).
Open a new script file and copy the script below. You will need to load this gridded dataset of surface temperature [34] that I have prepared for you. Save the file (right-click -> Save As...) to your R-script directory (and don't forget to set R-Studio's working directory to match). Note this is an .RData file. These files are essentially R-objects (variables) saved from a previous session of R. Because they are already defined as an R-object, you don't need to "read" them in. Instead you simply "load" them. It's a nice way of storing a permanent copy of some R-data that you've been working on and want to keep between sessions. If you want to read more, check out this article about various ways to save R data [35].
# you can find this code in: image_plot.R
# This code creates an image plot of surface temperature
# load a pre-made R dataframe called model.grid
load("sample_grid.RData")
# define a palette of colors
colormap<-rev(rainbow(100))
# Set the display to be a square
par(pty="s")
# create an image plot
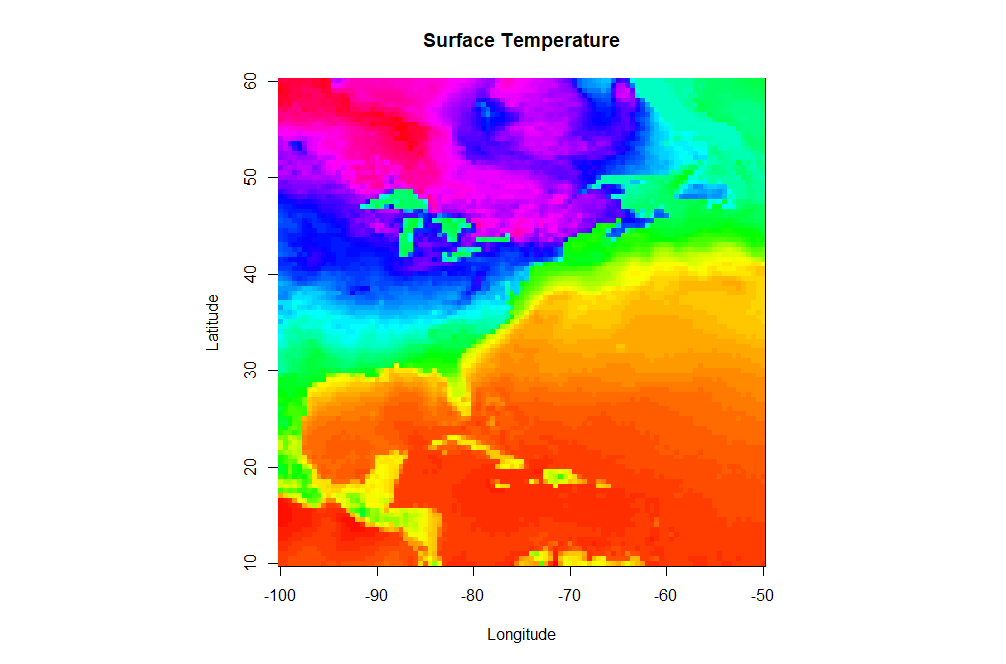
image(model.grid$x, model.grid$y, model.grid$z, col = colormap,
xlab = "Longitude", ylab = "Latitude",
main = "Surface Temperature")
There are a few new commands in the script above that I want to highlight. In addition to the aforementioned load command, note that I defined a specific color palette for my plot. I first define a vector of 100 colors selected from the default palette "rainbow" (I also reverse the order). Then I set the col parameter equal to my vector of colors in the image(...) command (col=colormap). R can give you almost any color scheme you might want. If you want to read more about color, I suggest starting with this color cheatsheet [36]. You might try removing the col=colormap to see the default color map for image(...).
Finally let's look at the image(...) command. First, remember that you can ?image or Google "R image" to find out all of the possible optional parameters that this plotting function takes. As a bare minimum, you must specify a vector of X-values, vector of Y-values, and a matrix (2-D) of Z values that map onto the X and Y space. I have provided you these basic vectors as part of the dataframe model.grid that was saved in the RData file (Can you see it in your environment space?). However, you will likely find that the data you want rarely comes in such a format (for example, some data might be a triplet-pair: {x, y, z}). Therefore, know that you might have to do some data manipulation to get things in the right format... this function is picky! Also note that image(...) does not give you a legend strip along with the plot. If you want the legend, you can substitute the command: image.plot(...) instead. This function however is not built-in to the base functions of R. To use image.plot(...) you are going to need to install the package "fields" (we'll discuss packages on the next page).
Contour Plots
Perhaps a pixel-by-pixel plot will not tell us what we want to know about a particular 2-D data field. In such cases we might want to look at a contour plot of the data. Contour plots strive to group regions of similar value. Contour lines can pinpoint specific values better and the contouring process tends to smooth the data. In case you’re not familiar with interpreting contour plots, you can take this little detour...
Let's now look at how we might contour our pre-loaded data set. Modify your image.plot script or start a new one.
# you can find this code in: contour_plot.R
# This code creates an contour plot of surface temperature
# load a pre-made R dataframe called model.grid
load("sample_grid.RData")
# Set the display to be a square
par(pty="s")
# create a contour plot
contour(model.grid$x, model.grid$y, model.grid$z,
xlab = "Longitude", ylab = "Latitude",
main = "Surface Temperature")
Here's the contour plot this script produces [37]. Note that the contour function and image function take input data in the same structure and the function call is quite similar. Let's look at what else we can do with this command. Try specifying the contour intervals using the levels parameter:
# create a contour plot
contour(model.grid$x, model.grid$y, model.grid$z,
levels=seq(-30,80, by=5),
xlab = "Longitude", ylab = "Latitude",
main = "Surface Temperature")
What about stacking two contour plots For example, let's add a second contour plot that consists only of the freezing (32F) contour as a thick blue line. Directly below the first contour function call, add (don't replace) this command to your script:
# create another contour plot
contour(model.grid$x, model.grid$y, model.grid$z,
levels=c(32),
xlab = "Longitude", ylab = "Latitude",
main = "Surface Temperature",
lty=1, lwd=2, col="blue",
add=TRUE)
Note the addition of the add=TRUE parameter. This simply adds the second contour plot on top of the first one.
Solve It!
Using the data set from this page, create the following image [38] showing an image plot with an overlaid contour.
Here is a possible solution:
# This code creates an image plot with contours of surface temperature
# load the data
load("sample_grid.RData")
# specify our color palette
colormap<-rev(rainbow(100))
# Set the display to be a square
par(pty="s")
# draw the image plot
image(model.grid$x, model.grid$y, model.grid$z,
col = colormap,
xlab = "Longitude", ylab = "Latitude",
main = "Surface Temperature")
# now draw the contours on top (note the "add=TRUE")
contour(model.grid$x, model.grid$y, model.grid$z,
add=TRUE)
Remember that you need not memorize all of these commands (recall my philosophy statement). Just make sure that you save examples of each type of graph for future reference. We’ll make use of such plots in greater detail in future lessons and you'll probably develop a few key "go-to" plots that you can tweak, depending on what is needed. Now let's examine R's ability to display data using custom plots created by others.
Read on.
Custom Plots
Prioritize...
After completing this section, you will know how to download and install custom packages that give the user access to specialized functionality. We demonstrate this functionality by exploring a package that plots wind roses.
Read...
We have looked at many different types of plots so far in this lesson. But what if we want a plot that is not included in the standard libraries? A wind rose [39] for example.
Think of a wind rose as a circular histogram of wind directions and speeds. These graphics are used by those interested in wind climatology. So, how might we get R to generate a wind rose? Certainly, given R’s powerful programming language, we could figure out the commands necessary to generate the plot that we want. However, there’s a better way. We can look for someone who has already done the work for us. Because R is open-source, people from all over the world are actively writing and contributing new functions that everyone can use. These new functions are grouped together into packages found on the R-project website [40].
With a little searching, I discovered a package named “openair” [41] which (among other things) plots wind roses. If you look at the user’s manual, you’ll discover all sorts of functions that deal with the analysis and display of air pollution data. At this time, I’m only interested in accessing the wind rose function.
First, I need to download and install the package. Here, R-studio is of great help. In the lower-right panel, click on the “Packages” tab. This displays all of the currently downloaded packages. Click on the “install” button, and in the dialog box that appears, type the package’s name: “openair” in the space available (leave everything else as default). You can also have the script check for and install the package by adding code such as lines 7-8 below.
Open a new R-script file and enter the following code (but don't source the file yet):
# you can find this code in: wind_rose.R
# This code plots the a wind rose using the package "openair"
# check to see if openair has been installed
# if not, install it
if (!require("openair")) {
install.packages("openair") }
# connect to the openair package
library(openair)
# Read in the RAW 5-minute ASOS file...
wind_data <- read.fwf("64010KPHL201401.dat",
widths=c(-28, 17, -21, 3,2),
header=FALSE,
col.names = c("date","wd","ws"))
# Convert the fields to the proper data types
# Packages often require strict adherence to data rules
wind_data$date <- as.POSIXct((strptime(wind_data$date, format = "%m/%d/%y %H:%M:%S")))
wind_data$wd<-as.numeric(as.character(wind_data$wd))
wind_data$ws<-as.numeric(as.character(wind_data$ws))
# plot the wind rose
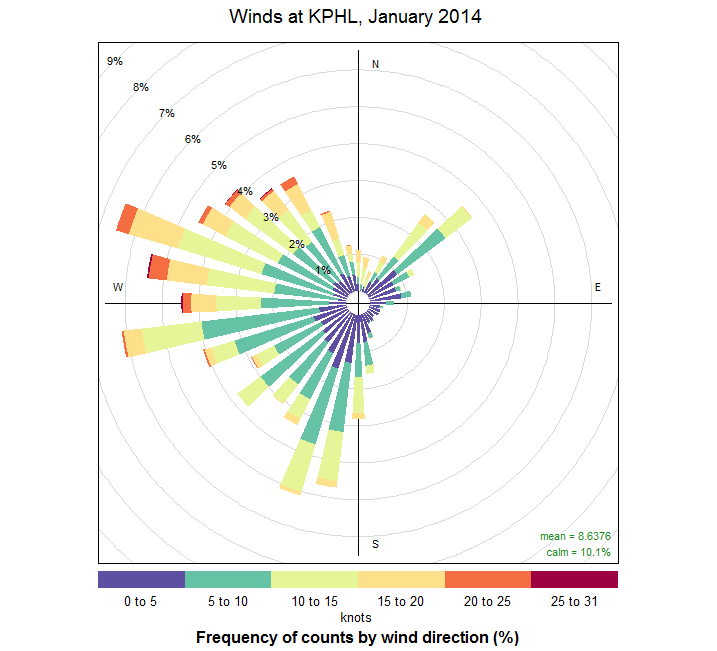
windRose(wind_data, angle=10,
paddle=F, breaks=c(0,5,10,15,20,25), seg=0.65,
offset=5, main = "Winds at KPHL, January 2014",
key=list(footer="knots", height=1)
)
Let's break it down.... First, we must tell R that we are including functions that are not part of its core set of commands. The line, library(openair) tells R to recognize all of the functions included in the package openair. If you don’t include this line, you will get an error when you try to use the windRose command which is only defined as part of the openair library. Next, we read the raw ASOS file of 5-minute averaged data for the Philadelphia International Airport [42]during January 2014 (to download the file, right-click -> Save As... on the link). If you want to grab your own data, you can get it from the ASOS NCDC page [43] (click on the 5-minute data link). Take a look at the file... it's a mess of numbers. After reviewing the "td6401b.txt" documentation found in the data directory, I decided to read the file into R using read.fwf() which reads in fixed-width files. Pay particular attention to the widths fields. I start out by ignoring the first 28 characters, then I read in the next 17, ignore 21 more, then read in 3 characters and 2 characters. I name the columns that I kept as "date", "wd", and "ws" (the "wd" and "ws" are required column names for the windrose command). Next, I needed to convert the columns into their proper data type (there's that nebulous type called a "factor" again).
Finally, let's look at the windRose command. How did I know how to use it? Remember that you can always type “?command” in the console window to see how a command is used. Or better yet, click on the packages tab (that you just used to install the openair package), find the “openair” package in the list, and click on it. Now you are given a listing of all the functions contained in the package. Scroll to the bottom and select the windRose function. Now you can see the usage and all the possible parameters that can be included.
You're welcome to play around with various settings to see how they affect the plot. I did, however, want to point out a fact about the input data. It's very important to make sure that your data match what the functions are expecting. In the case of windRose, the function requires a data frame that has columns with names "ws" (for speed) and "wd" (for direction). In the interest of full disclosure, I note that the documentation says that you can specify by name which columns are speed and direction, but I have found if you deviate from the "ws" and "wd" names, the function can behave unpredictably.
Finally, if you haven't already, source the file and generate the plot (seen below). We can see a few interesting trends. First, the winds during this time appear to come from two general quadrants: southwest, and northwest. The winds from the southwest tend to be lighter -- less than 10 knots. Northwest winds have higher observed wind speeds. We can see these trends if we examine the histograms of wind speed [44] for NW versus SW directions. Since this is January, I suspect the strong NW winds follow in the wake of strong cold fronts.
Throughout this course, we will be using packages built by others. You will discover that doing so is extremely convenient in retrieving and navigating large data sets. Some institutions like NOAA or NCDC even offer their own packages specially designed to interface with their own data. This saves us a great deal of time and effort. If you find you want to do something unique (or even find a better set of plotting tools) look first for a package to do the job.
Missing Values
Prioritize...
By the end of this section, you should be able to apply different methods for replacing missing values and list the pros and cons for each method.
Read...
Remember that in R, missing data, or data that is "not available" is designated by the constant "NA". You can think of NA as a place holder that has no value. Now, let's assume we have a data set where known bad/questionable/missing values have been replaced with NA's (using a line of code like: my_obs$temp[which(my_obs$temp=="-99999")]<-NA). The next question becomes, how do we deal with these non-existent values? There are three main actions we can take: remove rows of data with NA's completely, fill them in (with a proxy value), or leave them alone. What you choose will depend on your analysis and how sensitive that analysis is to having missing data.
Removal
Generally, if we are interested in some bulk characteristic of the data (and depending on the amount of data we have), simply removing missing values may be the best option. There are two ways to remove missing values. The first is listwise deletion. Listwise deletion removes all rows containing a missing value from the data set. For example, if I have a time series of temperature with 100 values, and the values at space 2 and 24 are missing, I would delete those values reducing my time series to 98 values. In R, you can use the function na.omit(...) which will perform a listwise deletion. But what if you are examining more than one variable. Let’s say you want to look at a temperature and relative humidity time series at a station -- again, there are 100 values for each. As with the first example, we have 2 days with missing data, but now in the relative humidity time series, 3 values are missing at spaces 2, 18, and 44. With listwise deletion, all cases with missing values are deleted. So, for the example above, we would delete the 2nd, 18th, 24th, and 44th values, resulting in a matched time series that is only 96 values long. In this case, you can think of listwise deletion as a "complete-case analysis", only obtaining cases where all variables have real data. Let's consider some code to demonstrate the use of na.omit(...)
#generate some random data and place it in a data frame
# the function "rnorm" creates random normal data with the
# given mean and standard deviation
my_obs<-data.frame("day"=1:100,
"temp"=rnorm(100,mean=50,sd=15),
"rh"=rnorm(100,mean=70,sd=15))
# Create some missing entries
my_obs$temp[which(my_obs$temp<25)]<-NA
my_obs$rh[which(my_obs$rh>100)]<-NA
# Print out number of observations and number of NAs for each variable
print(paste("Num obs:",length(my_obs$day),", Missing T:",sum(is.na(my_obs$temp)),", Missing RH:",sum(is.na(my_obs$rh))))
# Throw out rows with missing data
my_obs<-na.omit(my_obs)
# Print out number of new number of observations and verify no NAs left
print(paste("Num obs:",length(my_obs$day),", Missing T:",sum(is.na(my_obs$temp)),", Missing RH:",sum(is.na(my_obs$rh))))
A second type of omission is called pairwise deletion, which can be described as an ‘available-case analysis’. A pairwise deletion attempts to minimize the loss created by listwise deletion. In pairwise deletion, only the missing values that occur in both data sets are removed. So, in the example above, only 1 case (space 2) would be eliminated. This means that the statistics will be calculated with some missing values included. If you have a substantially long data set with few missing values, or your analysis requires complete samples (containing no missing values), I suggest going with listwise deletion. However, if you can’t take the loss of small sample size, pairwise elimination may be an option.
Imputation
Imputation is a general term used to describe the process of replacing missing data with generated (artificial) values. You should only use imputation if missing values will adversely affect your analysis or visualization of the data.There are many methods of imputation and the choosing the best method will depend on the data itself as well as the analysis you wish to perform. We will only discuss a few simple methods here, while more advanced approaches will be discussed in future courses.
One of the more common and easy methods of imputation is interpolation. Interpolation creates a new value that "fits" within the surrounding context of other observations and works particularly well for temporal or spatial data sets. Interpolation comes in many flavors. Linear interpolation approximates the missing value by first constructing a trend ‘line’ that spans two know observations. Then, a value is selected from that trend line at a point contingent on the distance the missing value is from the two locations. Linear interpolation assumes that a observations vary quasi-linearly between sets of points. This is a decent approximation if the resolution of the observations is higher than the significant natural variability. For example, interpolating a missing hourly temperature will be more accurate than interpolating a daily temperature. Because hourly temperature can, in most cases, be seen as varying linearly while average daily temperature show considerably more variability from day-to-day.
R has several built-in functions for linear interpolation. Check out the use of the approx(...) function [45] which creates a liner approximation for a given data set containing missing values.
# Create some fake temperature data
time<-c(1:48)
temp<-(-30)*sin(time/24*pi+pi/10)+70
# Pick 10 random times and replace those temperatures with NAs
missing_times<-sample(2:47, 10, replace=F)
temp[missing_times]<-NA
# plot the time series using square symbols
plot(time, temp, pch=0, cex=2,
main="Using approx() to Fill in Missing Values",
xlab="Observations",
ylab="Temperature (F)")
# interpolate the missing data
# data that's not missing will just be the same
complete_temp<-approx(time, temp, xout=time)
# plot the interpolated data using stars
points(complete_temp$x, complete_temp$y, pch=8)
# How good is it? This computes the root mean squared
# error caused by the interpolation and writes it on the plot.
text(35,50, paste0("RMSE: ",
mean(sqrt((complete_temp$y[missing_times]-
((-30)*sin(missing_times/24*pi+pi/10)+70))^2))))
Here is the graph created by the R-script above [46]. The squares represent the original "observed" data with some random missing values. The stars show the interpolated time series. Note that the root mean squared error is less than 0.5 degree.
Another method is to use a more complex function to model the gap created by the missing data. In R, we can use the function spline(...) [47] to use cubic splines (3rd-order polynomials) instead of lines to find the missing values. Modify the code above by replacing the line containing the approx(...) function with: complete_temp<-spline(time, temp, xout=time, method = "fmm"). Here's the graph of the spline interpolation [48] for our simulated data. Notice how small the RMS error is! Mind you, real data won't behave quite so nicely, but you can see how higher order approximations are better than linear ones.
In the case of spatial data, you can also fill the missing value by considering surrounding points. There are many different methods of varying complexity. If you are looking for some simple bi-linear or bi-cubic interpolation routines, check out the package "akima" [49].
Leave the Missing Values In
The last option, of course, is to leave the missing values in the data set. This is perhaps the most informative choice for the users of the data and may itself provide additional information pertinent to your analysis. For example, let's say you wanted to compute the mean daily temperature at a location for December, January and February. However, on February 2 an ice storm caused a two-week data loss (the sensor was damaged) at your site. Should you simply calculate a mean with the data you have? Or, is two weeks (out of 12 total) too much missing data? We'll tackle such questions in future courses, but suffice to say, you should give serious consideration to at least providing a notation that a significant amount of data was missing from your calculation of the mean.
Leaving missing data in the data set need not sabotage your analysis, however. In R, many functions have parameters which allow you to ignore the NA values. You can look for parameters such as na.rm or na.omit when looking at the help page for a particular function. Setting this value to TRUE will cause the function to ignore the NA values from any calculations that the function performs. Consider the help page for the function mean(...) [50]. Modify the code above (remove the listwise deletion) to see the difference na.rm=TRUE makes when computing a mean with NA values.
You will also see in future courses that the number of samples is a key parameter in the calculation of various statistics. If you leave in the missing numbers, the number of samples stay the same but no added information is gained. Deleting the missing values reduces the number of samples which can change the results. The size of the effect varies depending on the specific statistic. You can perform sensitivity analyses to determine this size (compute the statistic with missing values in and with missing values removed).
Transforming Data
Prioritize...
After this section, you should be able to perform various transformations on a dataset and determine which type of transformation would work best.
Read...
Sometimes unruly data is not caused by missing values, but rather is difficult to visualize due to range or clustering issues. In such cases, we may want to apply a data transformation to better visualize or communicate your message. A data transformation is the application of a mathematical function on each data value. In essence, while data transformations may change the value of the data, they do so in a known (and reversible) manner.
To illustrate when a data transformation might be needed, consider the histogram below that shows the distribution of hourly non-zero rainfall observations during the year 2010 for Alexandria, LA. You'll note right away that this graph is not at all informative. This is because most hourly observations are located in the first bin (<0.5 inches) while at the same time, there are some observations that exceed an inch. Increasing the bin number [51] doesn't help us that much because once again, 1) most of the observations are contained in the lowest bin and 2) that bin is so large that smaller count values are difficult to read. This type of distribution is referred to as having a right skew because most values are small (a left-skewed distribution would have mostly large values).
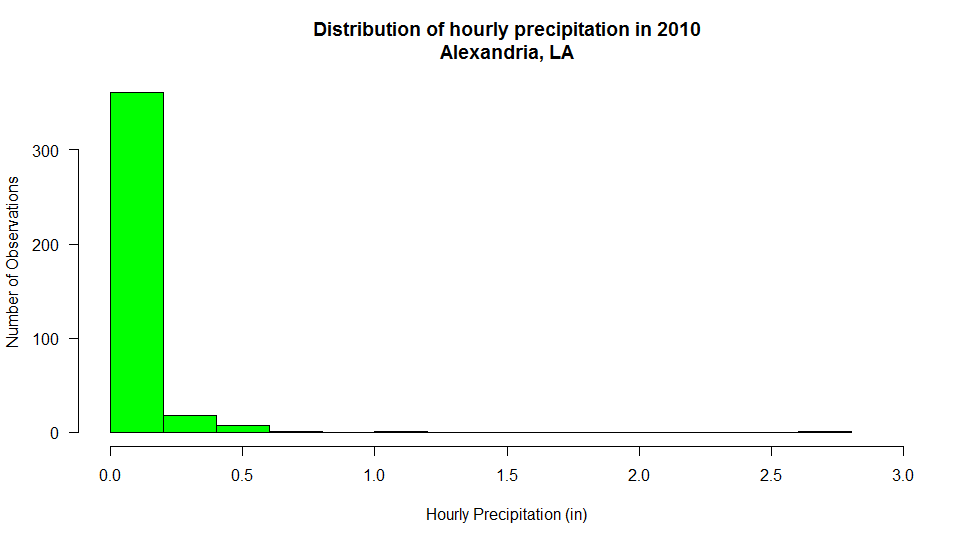
But what if we wanted to understand the distribution of observations better? How might we transform the data to give us more insight? In order to combat the large discrepancy in scale of the histogram bins, let's look at what happens if we apply a base-10 logarithmic transform to the observations. In case you are not familiar with logarithms, all you basically need to know is that a logarithm transforms a number into the exponent of its base. For example, the base-10 logarithm of 100 is 2 because 100=102. Likewise, log10(10)=1 and log10(1)=0. Logarithms of numbers smaller than 1 are negative, so log10(0.1) is -1 because 10-1=0.1. This means that I can represent a large range such as 0.1 to 100 on an axis that only spans -1 to 2. To plot the log-base-10 histogram, you just need to make your histogram call: hist(log10(mydata$precip), ....). Here's the log10 histogram of the precipitation observations [52]. (Note: I should also point out that a logarithmic transformation cannot be applied to negative or zero data values).
Working with transforms can be a bit tricky to interpret, for you and your audience. Make sure that you clearly label any transform that you have performed and be prepared to explain what you have done (and why). Notice in the log10 histogram, I have changed the x-axis label to reflect that I have taken the log10 of the data before binning. Still, it may be hard to recognize that "-2" on the x-axis is actually 0.01 inches. One approach is to change your x-axis labels back to the untransformed values. In R, you can turn off the automatic x-axis using the plot parameter xaxt='n', then add your own axis command such as: axis(side=1, at=seq(-2,0.5, 0.5), labels=c(0.001, 0.031, 0.1, .31, 1, 3)). The result is a histogram that is much easier to read [53] even though the labels are not equally spaced.
Finally, note that the first bin has a very large number of counts and the bins to the right have very small count values -- so much so, that it's hard to determine their actual values. Perhaps we could apply a log10 scale to these values as well. The answer is "yes" of course, but we need to approach things a bit differently. Examine the code and output below...
# Let's assume that column "precip" is in a dataframe "mydata"
# I have assigned NA to all missing, trace, and 0 values.
# Perform the histogram calculation but do not plot the results
# Save the results in a dataframe called "hist_plot"
hist_plot<-hist(log10(mydata$precip),breaks=20,plot=FALSE)
# Now make the plot. Notice the log="y" that sets the y axis to a log scale
plot(hist_plot$breaks[1:25],hist_plot$counts, log="y", type='h',
lwd=25, lend=3,col="green",
main="Distribution of hourly precipitation in 2010\nAlexandria, LA",
xlab="Hourly Precipitation (in)",
ylab="Number of Observations" )
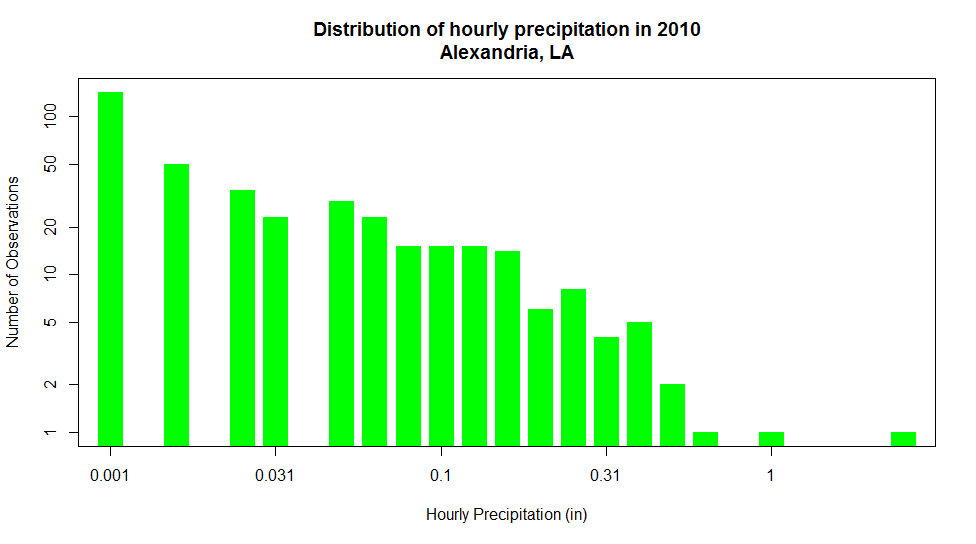
Notice now, that not only can we see all of the detail in bins of the histogram, we can clearly distinguish the values of each bar (from the largest to the smallest). I should note that we might lose the perspective on the shape of the distribution of observations, we gain detailed insight into the various amounts of precipitation and their frequency of occurrence over during the year.
While log transforms are by far the most common, there are several other methods to chose from depending on the characteristics of your data. Check out the table below for a summary of various other data transforms.
| Method | Math Operation | Good for: | Bad for: |
|---|---|---|---|
| Log | ln(x) log10(x) |
Right skewed data log10(x) is especially good at handling higher order powers of 10 (e.g., 1000, 100000) |
Zero values Negative values |
| Square root | √x | Right skewed data | Negative values |
| Square | x2 | Left skewed data | Negative values |
| Cube root | x1/3 | Right skewed data Negative values |
Not as effective at normalizing as log transform |
| Reciprocal | 1/x | Making small values bigger and big values smaller | Zero values Negative values |
NOTE: Before we leave this topic, there are two points that I think are very important... 1) Data transformation is only useful when displaying data. Do not transform your data if you are going to be applying any sort of statistical analysis on them. Applying a data transform before you process it may have unpredictable and erroneous results. 2) When you show transformed data, make sure that you are very clearly indicating the type of transform that has been applied. You should do this both in a graphic's title (e.g., "Log10(Pressure) versus Temperature") and in axis labels (e.g., "1/Temperature (1/oC)").
Debugging Code
Prioritize...
After reading this section, you should be able to follow the debugging process, google problems effectively, and find solutions for the some of the more common errors you may encounter in R.
Read...
Learning to code is like learning a new language. It’s hard, you’ll stumble, you’ll make mistakes, but learning to correct those mistakes is one of the most important parts of the process. If you mispronounce a word, you don’t just move on, you keep trying until you get the pronunciation right. Similarly, in coding, you can’t just move on in the code if there’s an error. You must keep trying until you fix the code and it runs smoothly. The good thing about coding is that once you figure out the debugging process for one language, you can apply it to almost all languages. The content here is meant to guide you and help you along in the debugging process. My goal is for you to become self-reliant when it comes to coding errors. Asking questions and seeking help is still a part of the process! I’m just not the first step.
Debug 101
There is no set process for debugging. The route I take to debug will be different from the route that you take; it comes down to personal preference. As you write more and more code, your debugging method will be refined. But if you are just starting to code, it can be quite challenging to know where to even begin. Therefore, I will present my debugging process. You don’t need to follow it step-by-step; it’s merely here to show you what I do when I get a coding error.
- I start by opening RStudio and clearing out everything. It’s important to start with a clean slate. To do this, I run the command rm(list=ls()). This clears out the environment.
- Before debugging, I actually highly recommend you perform this step and rerun your code to see if the error still occurs. Sometimes, we override variables when testing out code, so this is a good first check to ensure we really have an error or not.
- Next, I open the script and load in the data needed.
- Then, I run the script line by line until the error occurs.
- Sometimes, I luck out and know the error message, but most times that’s not the case. I start by stating the goal of the line. What is the purpose of the function? What sort of outcome do I expect (very important if you have no error but are getting unexpected values)? Stating the objective will help you focus on the problem at hand.
- Once I know the goal, I figure out what I need to reach that goal. Maybe the function selected was not the right function to use (typical when we have unexpected results instead of error messages).
- If the function selection is correct, I then move on to the inputs. What goes into the function (do a help on the function)? Am I providing all the parameters? Maybe I’m missing an input?
- Once I know I’m providing all the right input, I check to see if the input is correct. That is, I’ll print out the values in each input or plot them or use the summary command. The goal is to make sure the input is realistic.
- If the input is NOT realistic, then I go to where I create that input and check the code there. Usually, I’ll have one little mistake; like missing an index or I didn’t convert to numeric values. Generally speaking, this is the type of error I see the most.
- If the input looks realistic, then my next step is usually to google the error message. You can read more about how to google coding problems in the next section.
- At this point, I either have fixed the problem or I’m stumped. If I’m stumped, it’s probably time to reach out for help; either to peers, mentor, instructor, or online (Stack Overflow [54] is a great website to post coding questions).
- Now I should have a solution. The next step is to fix the code and then clear out my environment again. I rerun each line of code and see if the error is fixed. If I have a new error, then I go through the process again. Otherwise, my code is fixed and I can move on.
Again, the steps presented here are not meant to be the holy grail of debugging, but instead are meant to help guide you through the process. What works for you will be different from what works for me or your peers. Refining this process will only make you a better coder.
Google It!
Googling is an important step in the debugging process. But googling efficiently is a challenge. If done correctly, you’ll land on the perfect result instantly. Done poorly, and well, you’ll be sifting through hundreds of pages before coming to the right answer.
As you debug more and more code, and thus google more and more errors, you’ll become more efficient (e.g., you’ll know what gets you to the answer quicker and what doesn’t). For me, I have more luck then expected by simply copying the error output and pasting it directly in the google search bar and adding ‘in R’ to the search. If this doesn’t work, my next search is usually the function name + ‘error in R’. I’ll have to look through a couple stack overflow pages, but this usually does the trick.
Searching to find a function can be a bit more tricky. Finding the right phrase to describe the function you need is important. I usually start by googling a broad idea with the phrase ‘in R’ attached. Then after looking through a few pages I start to see a more common phrase and I’ll google that instead, again with ‘in R’ attached. I’ll usually find some functions at this point that let me do what I wanted. I then search for examples of these functions to see how I should set up my code.
There are some great links in the resources that discuss best practices for googling. Similar to your debugging process, your googling process will be unique and probably change over time.
Quiz Yourself...
Before we work through some examples, let me introduce you to the DataCamp setup. Although you've seen DataCamp examples before, we will be using it here in a 'quiz mode'. You'll run the code, but an error will pop up. Your task is to fix the code so the error message goes away. You can change and rerun the code as much as you want. If you are having trouble or need a little extra guidance, click the 'Hint' button. Let's give it a try. Run the code below without changing anything.
You should have gotten the following error: "Your code contains a syntax error". If you look in the console, you'll see the error is specifically at line 2 (where you assign "a") and the specific error is a parsing error. Do you know why the error is occurring? Try fixing the code and rerunning. Did you get the right answer now? If not, try clicking on the 'Hint' button. Now fix the code again, and see if you get the right answer. If you are still stuck, you can always click the 'Solution' button to see what 'a' should be assigned to.
Now that you've seen how DataCamp can help you practice your debugging skills, take a look at the coding examples below. Each has a unique error. Your task is to find the error and fix the code. You can try as many times as you want. All examples will use 36 years of monthly temperature data from NYC. There are two variables: Date and Temperature. The variable Date is a date object while the variable Temperature contains the temperature data in degrees Celsius.
For the first example, estimate the 36-year mean for the month of August. There is one error in the code:
For the second example, I've estimated the 36-year mean for each season (DJF, MAM, JJA, and SON). The results are saved to the variable seasonMean. I want to replace the DJF estimate with an NA. Again, there is one error in the code:
For the third example, plot a time series of monthly temperature for NYC from 2000-2010. There is one error in the code:
Explore Further...
I highly suggest you check out the resources listed below. Seeing how other people debug is of great use. There are some great tutorials, specific to R, and some more broader views on how to debug in general. I encourage you to take some time now and read through the material.
Advanced R (Debugging) by Hadley Wickham [56]
Exceptions Debugging (Advanced R by Hadley Wickham) [57]
Debugging in R [58]
R Debugging Tutorial [59] (video)
Lesson 3 Activity
Assignment Objective...
You will use the skills you have learned in R to dive into some large, weather data sets. The goal of this assignment is to create the required graphics to answer the various posed questions. Note: We'll also include some of the concepts about communicating your message from Lesson 2.
Let's get started.
Download the data...
Here is the file containing the weather data that you will need [62]. It is a comma-delimited file containing temperature and precipitation data at O'Hare International Airport from 1 January 1976 to 31 December 2016 (40 years). Assume for the moment that the data is accurate and that no changes to the site have occurred that would affect the record. We'll learn in the next lesson how to make such determinations, but let's not complicate things at this point. WARNING! Editing this file in Excel will change the date formats (just be aware of that).
Deliverables...
Please use R to create graphics that answer the following questions regarding the data. You can build on the pieces of code that I provided in the lesson, but know that I have intentionally left a few challenges in your way that you are going to have to overcome (as does working with any new data set). You are welcome to convey the answers to the questions in any manner you wish, however, you are expected to have a clear resultant message for each problem you are asked to examine. (Correct graphics, correctly formatted, are a critical requirement.)
Each question should contain the following components:
Question and Answer Summary – Start each section of your report with the question you are trying to answer and your key message (no more than a paragraph) of what the data tell you. All of the questions here are simply asking you to present what the data say, without any deeper meteorological analysis or editorial. This, of course, is not what would happen in the real world, but visualizing the data is a key first step in any analysis procedure. If you are a statistics whiz, please refrain from providing calculation more complex than an "average" or "sum".
Graphic(s) – You may provide no more than two graphics for each question. Your client is busy and doesn't want to be bored to death with a stream of endless graphs. Please make sure that each graph is appropriate for your message and contains all of the things that good graphs should have (titles, labels, legends, etc.). You are not limited to only the look and feel of the graphs that I have presented in this lesson. Indeed, you may (and are encouraged to) experiment with different looks and ways of presenting the information as well. However, don't worry if such exploration is beyond your coding abilities. Most often, a simple approach is best to convey the proper message.
Reasoning – Provide the reasoning as to why you chose to present the data in a certain way. Why did you use a line graph instead of a bar graph? Why did you choose a histogram instead of a scatter plot? This section is key. It is meant to show me how you thought about your approach. You would never get into this much detail with a client, but you might have to argue such reasoning to members of your team.
R-Code – Finally, provide the code that produced the graphic(s) in each question. As I have stated earlier, I am not grading your code, per se. However, I would like to be able to provide feedback on your approach. Please make sure that your code is nicely formatted and has enough comments so that I can understand what you did.
Questions...
- Over the course of the year, what is the "normal" climate (normal max temperature, normal min temperature, and precipitation) like in Chicago? As a point of suggestion, check out this page from the NWS [63] illustrating how precipitation with respect to normal is plotted. I'm not saying that you have to do it this way (if you feel there's a better way), but I wanted you to see some examples.
- The normal mean temperature for a particular day is usually based on the past 30 years of the record. But how "normal" is normal? Focus on the normal mean temperature at different months of the year. How "good" (in a qualitative sense) is the "normal" temperature at describing what you might observe? For what month(s) is the normal temperature a good measure of what to expect? What month(s) is the worst?
- The meteorological winter (Dec, Jan, Feb) of 2014-2015 seemed awfully cold... was it?
- The Chicago Heatwave of 1995 is fairly notable in its severity (Wikipedia article [64]) and in its "estimated" death toll. My grandparents lived just outside Chicago and I know that summers there can be hot! But, just how remarkable was this string of temperatures from 12 July to 16 July 1995 compared to other hot summer periods (not necessarily those exact days, but rather a "hot" string of days)?
- They call Chicago the "Windy City". Is this true? Is it windier in Chicago than in, say, Kansas City, Kansas (yes, no, sometimes)? Note that the original data set doesn't have wind. No problem. Here are 10-year records for O'Hare International [65] and Kansas City International [66]. These files are straight out of the ISD Database [67] so you might need to do some tweaking of
read.csv(...)to get them read in. Please use this library along with "openair" to discuss this question. For this question alone, I am suspending my 2-graphic limit (you may need a few here, but don't go crazy)!
The Fine Print...
- Please submit your report in either MSWord or PDF format.
- Saving images: R-Studio makes saving graphs a piece of cake. Notice that at the top of the plot window there is an "Export" pull-down where "Save as Image" is an option. When you choose "Save as image" you are given a dialog box where you can set the type (PNG is best), location, and filename of your image. I would set aside a folder for this assignment where you can save your images and then paste them into your word-processing document.
- Unlike your last assignment, please just paste all of your images in-line. I envision one page for each question with all of the required parts with the exception of the R-code perhaps.
- Proofreading is a must. It shows professionalism and care for your work. This includes not only basic spelling and grammar, but readability as well. If you struggle with proofreading, have someone give your draft a once-over and provide suggestions.
- Grading: I want to foster an environment where you can focus more on what you are learning that what "grade" you are getting. However, that said, I have to give some sort of grade and feedback for each assignment. Please see my assignment grading rubric in the Orientation section for general guidelines on assignment grades.
Submit Your Assignment
Please follow the instructions listed on the submission page in Canvas.Lesson 3 Activity Hints and Tricks
Hints and Tricks...
I know that this activity might be a bit rough for folks who are new to coding. So, I thought that I would use this page to provide some tips and tricks to help you get started. I have listed them according to each question that you are trying to answer. As more questions come in, I hope to add to this page.
General Thoughts
- Be careful if you open/edit/save your data file in Excel. Excel changes the format of the date column. You can still read it, but you will need to use a different format. You can use the following command to properly format dates in R (you can google "R as.Date" for more information.
# Format a column in dataframe "mydata" to be dates # You have to tell R the format of the dates in the file mydata$Date<-strptime(mydata$Date, format="%Y-%m-%d") #but if you edited the file in Excel, you might need: mydata$Date<-strptime(mydata$Date, format="%m/%d/%y")
- Make sure that you don't try to do too much in each line of code. If you keep each step separate, you can better figure out what's happening when things go awry.
Question 1: Normal Climate
- It's best to extract a year's worth of Normals you are going to need to plot. For example:
# Get a year's worth of dates dates1976<-mydata$Date[(mydata$Date >= "1976-01-01" & mydata$Date < "1977-01-01" )] # Get a year's worth of Max Temperature Normals maxtemps1976<-mydata$MaxTemperatureNormal[(mydata$Date >= "1976-01-01" & mydata$Date < "1977-01-01" )] #etc
Then, make your plots using these new variables. - For Normal precipitation, you might want to create a cumulative precipitation graph (which shows average accumulation over an entire year). You can use the function
cumsum(...)to perform this task.
Question 2: How Normal is Normal
- You can easily compute the deviation of the mean daily temperature from normal for a given month by using the following...
JanmeanTempdiffs<-mydata$AvgTemperature[(strftime(mydata$Date,"%m"))=="01"]-mydata$AvgTemperatureNormal[(strftime(mydata$Date,"%m"))=="01"]
Question 3: Cold Winter?
- Building on what you did in Question 2, there are lots of ways to go about this. What if we created a variable of daily temperature differences for every January day (like we did above) and then averaged them by year. Start with a variable of differences and the dates on which they occur...
JanmeanTempdiffs<-mydata$AvgTemperature[(strftime(mydata$Date,"%m"))=="01"]-mydata$AvgTemperatureNormal[(strftime(mydata$Date,"%m"))=="01"] Jan_dates<-mydata$Date[which(strftime(mydata$Date,"%m")=="01")]
Now, to average these by year, we need to use theaggregate(...)function. This function takes one column of data and performs a function on it using grouping (specified in the "by" column). In the case below, I create a list of years by which to do the averaging.# use the aggregate function to get a mean January # departure by year. meanTempdiffs<-aggregate(JanmeanTempdiffs, by=list(strftime(Jan_dates,"%Y")), mean, na.rm=TRUE) colnames(meanTempdiffs) <- c("Year", "MeanDiff")Finally, we can sort the result by coldest January.coldest_Jans<-monthyTempdiff[order(monthyTempdiff$MeanDiff),]
- I'm not saying this is the best way to do this. What defines a "cold winter"? There may be several answers.
Question 4: Heat Wave
- Much like the Cold Winter question, there are some interesting ways however of visualizing this. Histogram? An image plot perhaps?
Question 5: Windy City
- For reading in the files, you might need to add the parameter
skip=2toread.csv(...). This will skip the first two header rows of the file (you can rename the columns you want to keep). I also suggest using the parameter,colClasses = "character", so that you can do the data conversions yourself (better this way). - The function windRose is picky... You will need your dates/time combined into a single data.frame column called "date". You will also need to make sure that the wind columns are properly labeled, converted to numeric, and have any missing data (999) converted to NA's. Here's the algorithm...
# read the data # keep the date, time, direction, and speed columns # create a single date column. Here's an example # I labeled my unformatted date/time accordingly wind_data$date<-as.POSIXct(strptime(paste(wind_data$date_uf,wind_data$time_uf), format = "%Y%m%d %H%M", tz="UTC")) # convert wd and ws columns to numeric and set 999 to NA # plot the wind rose