10. Triangulation
Closed traverses yield adequate accuracy for property boundary surveys, provided that an established control point is nearby. Surveyors conduct control surveys to extend and densify horizontal control networks. Before survey-grade satellite positioning was available, the most common technique for conducting control surveys was triangulation.
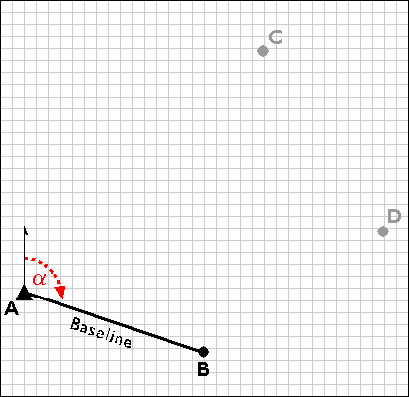
Using a total station equipped with an electronic distance measurement device, the control survey team commences by measuring the azimuth alpha, and the baseline distance AB. These two measurements enable the survey team to calculate position B as in an open traverse. Before geodetic-grade GPS became available, the accuracy of the calculated position B may have been evaluated by astronomical observation.
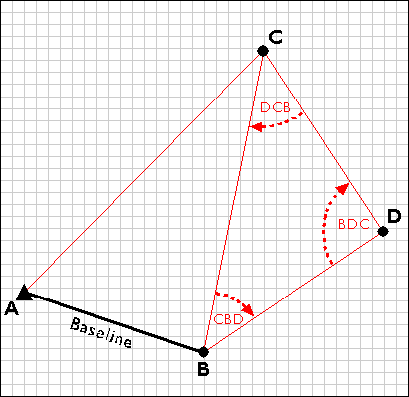
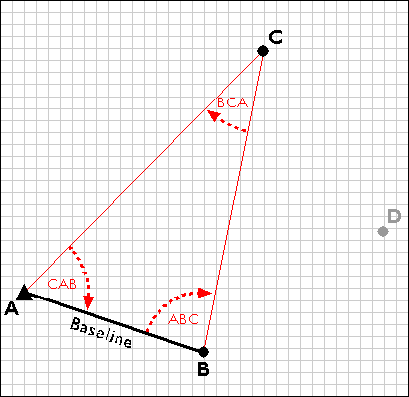
The surveyors next measure the interior angles CAB, ABC, and BCA at point A, B, and C. Knowing the interior angles and the baseline length, the trigonometric "law of sines" can then be used to calculate the lengths of any other side. Knowing these dimensions, surveyors can fix the position of point C.
Having measured three interior angles and the length of one side of triangle ABC, the control survey team can calculate the length of side BC. This calculated length then serves as a baseline for triangle BDC. Triangulation is thus used to extend control networks, point by point and triangle by triangle.