SELECT Query Syntax
Hopefully, you've found the MS-Access query builder to be helpful in learning the basics of retrieving data from a database. As you move forward, it will become important for you to learn some of the syntax details (i.e., how to write the statements you saw in SQL View without the aid of a graphical query builder). That will be the focus of this part of the lesson.
A. The SELECT clause
All SELECT queries begin with a SELECT clause whose purpose is to specify which columns should be retrieved. The desired columns are separated by commas. Our first query in this lesson had a SELECT clause that looked like the following:
SELECT STATS.PLAYER_ID, STATS.HR, STATS.RBI
Note that each column name is preceded by the name of its parent table, followed by a dot. This is critical when building a query involving joins and one of the desired columns is found in multiple tables. Including the parent table eliminates any confusion the SQL interpreter would have in deciding which column should be retrieved. However, you should keep in mind that the table name can be omitted when the desired column is unambiguous. For example, because our simple query above is only retrieving data from one table, the SELECT clause could be reduced to:
SELECT PLAYER_ID, HR, RBI
Selecting all columns
The easiest way to retrieve data from a table is to substitute the asterisk character (*) for the list of columns:
SELECT *
This will retrieve data from all of the columns. While it's tempting to use this syntax because it's so much easier to type, you should be careful to do so only when you truly want all of the data held in the table or when the table is rather small. Retrieving all the data from a table can cause significant degradation in the performance of an SQL-based application, particularly when the data is being transmitted over the Internet. Grab only what you need!
Case sensitivity in SQL
Generally speaking, SQL is a case-insensitive language. You'll find that the following SELECT clause will retrieve the same data as the earlier ones:
SELECT player_id, hr, rbi
Why did I say "generally speaking?" There are some RDBMS that are case sensitive depending on the operating system they are installed on. Also, some RDBMS have administrative settings that make it possible to turn case sensitivity on. For these reasons, I suggest treating table and column names as if they are case sensitive.
On the subject of case, one of the conventions followed by many SQL developers is to capitalize all of the reserved words (i.e., the words that have special meaning in SQL) in their queries. Thus, you'll often see the words SELECT, FROM, WHERE, etc., capitalized. You're certainly not obligated to follow this convention, but doing so can make your queries more readable, particularly when table and column names are in lower or mixed case.
Finally, recall that we renamed our output columns (assigned aliases) in some of the earlier query builder exercises by putting the desired alias and a colon in front of the input field name or expression. Doing this in the query builder results in the addition of the AS keyword to the query's SELECT clause, as in the following example:
SELECT PLAYER_ID, HR AS HomeRuns, RBI
B. The FROM clause
The other required clause in a SELECT statement is the FROM clause. This specifies the table(s) containing the columns specified in the SELECT clause. In the first queries we wrote, we pulled data from a single table, like so:
SELECT STATS.PLAYER_ID, STATS.HR, STATS.RBI FROM STATS
Or, omitting the parent table from the column specification:
SELECT PLAYER_ID, HR, RBI FROM STATS
The FROM clause becomes a bit more complicated when combining data from multiple tables. The Access query builder creates an explicit inner join by default. Here is the code for one of our earlier queries:
SELECT PLAYERS.FIRST_NAME, PLAYERS.LAST_NAME, STATS.YEAR, STATS.RBI FROM PLAYERS INNER JOIN STATS ON PLAYERS.PLAYER_ID = STATS.PLAYER_ID
An inner join like this one causes a row-by-row comparison to be conducted between the two tables looking for rows that meet the criterion laid out in the ON predicate (in this case, that the PLAYER_ID value in the PLAYERS table is the same as the PLAYER_ID value in the STATS table). When a match is found, a new result set is produced containing all of the columns listed in the SELECT clause. If one of the tables has a row with a join field value that is not found in the other table, that row would not be included in the result.
We also created a couple of outer joins to display data from records that would otherwise not appear in an inner join. In the first example, we chose to include all data from the left table and only the matching records from the right table. That yielded the following code:
SELECT [PLAYERS]![FIRST_NAME] & ' ' & [PLAYERS]![LAST_NAME] AS PLAYER, STATS.YEAR, STATS.RBI
FROM STATS LEFT JOIN PLAYERS ON STATS.PLAYER_ID = PLAYERS.PLAYER_ID
Note that the only difference between this FROM clause and the last is that the INNER keyword was changed to the word LEFT. As you might be able to guess, our second outer join query created code that looks like this:
SELECT [PLAYERS]![FIRST_NAME] & ' ' & [PLAYERS]![LAST_NAME] AS PLAYER, STATS.YEAR, STATS.RBI
FROM STATS RIGHT JOIN PLAYERS ON STATS.PLAYER_ID = PLAYERS.PLAYER_ID
Here the word LEFT is replaced with the word RIGHT. In practice, RIGHT JOINs are more rare than LEFT JOINs since it's possible to produce the same results by swapping the positions of the two tables and using a LEFT JOIN. For example:
SELECT [PLAYERS]![FIRST_NAME] & ' ' & [PLAYERS]![LAST_NAME] AS PLAYER, STATS.YEAR, STATS.RBI
FROM PLAYERS LEFT JOIN STATS ON STATS.PLAYER_ID = PLAYERS.PLAYER_ID
Recall that the cross join query we created was characterized by the fact that it had no line connecting key fields in the two tables. As you might guess, this translates to a FROM clause that has no ON predicate:
SELECT STATS.PLAYER_ID, TEAMS.ABBREV
FROM STATS, TEAMS;
In addition to lacking an ON predicate, the clause also has no form of the word JOIN. The two tables are simply separated by commas.
Finally, we created a query involving two inner joins. Here is how that query was translated to SQL:
SELECT PLAYERS.FIRST_NAME, PLAYERS.LAST_NAME, STATS.YEAR, STATS.HR, TEAMS.CITY, TEAMS.NICKNAME
FROM (PLAYERS INNER JOIN STATS ON PLAYERS.PLAYER_ID = STATS.PLAYER_ID) INNER JOIN TEAMS ON STATS.TEAM = TEAMS.ABBREV;
The first join is enclosed in parentheses to control the order in which the joins are carried out. Like in algebra, operations in parentheses are carried out first. The result of the first join then participates in the second join.
C. The WHERE clause
As we saw earlier, it is possible to limit a query's result to records meeting certain criteria. These criteria are spelled out in the query's WHERE clause. This clause includes an expression that evaluates to either True or False for each row. The "True" rows are included in the output; the "False" rows are not. Returning to our earlier examples, we used a WHERE clause to identify seasons of 100+ RBIs:
SELECT STATS.PLAYER_ID, STATS.YEAR, STATS.RBI
FROM STATS
WHERE STATS.RBI > 99
As with the specification of columns in the SELECT clause, columns in the WHERE clause need not be prefaced by their parent table if there is no confusion as to where the columns are coming from.
This statement exemplifies the basic column-operator-value pattern found in most WHERE clauses. The most commonly used operators are:
| Operator | Description |
|---|---|
| = | equals |
| <> | not equals |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| BETWEEN | within a value range |
| LIKE | matching a search pattern |
| IN | matching an item in a list |
The usage of most of these operators is straightforward. But let's talk for a moment about the LIKE and IN operators. LIKE is used in combination with the wildcard character (the * character in Access and most other RDBMS, but the % character in some others) to find rows that contain a text string pattern. For example, the clause WHERE FIRST_NAME LIKE 'B*' would return Babe Ruth and Barry Bonds. WHERE FIRST_NAME LIKE '*ar*' would return Barry Bonds and Harmon Killebrew. WHERE FIRST_NAME LIKE '*ank' would return Hank Aaron and Frank Robinson.
Note:
Text strings like those in the WHERE clauses above must be enclosed in quotes. Single quotes are recommended, though double quotes will also work in most databases. This is in contrast to numeric values, which should not be quoted. The key point to consider is the data type of the column in question. For example, zip code values may look numeric, but if they are stored in a text field (as they should be because some begin with zeroes), they must be enclosed in quotes.
The IN operator is used to identify values that match an item in a list. For example, you might find seasons compiled by members of the Giants franchise (which started in New York and moved to San Francisco) using a WHERE clause like this:
WHERE TEAM IN ('NYG', 'SFG')
Finally, remember that WHERE clauses can be compound. That is, you can evaluate multiple criteria using the AND and OR operators. The AND operator requires that both the expression on the left and the expression on the right evaluate to True, whereas the OR operator requires that at least one of the expressions evaluates to True. Here are a couple of simple illustrations:
WHERE TEAM = 'SFG' AND YEAR > 2000
WHERE TEAM = 'NYG' OR TEAM = 'SFG'
Sometimes WHERE clauses require parentheses to ensure that the filtering logic is carried out properly. One of the queries you were asked to write earlier sought to identify 100+ RBI seasons compiled before 1960 or after 1989. The SQL generated by the query builder looks like this:
SELECT STATS.PLAYER_ID, STATS.YEAR, STATS.RBI
FROM STATS
WHERE (((STATS.YEAR)>1989) AND ((STATS.RBI)>99)) OR (((STATS.YEAR)<1960) AND ((STATS.RBI)>99));
It turns out that this statement is more complicated than necessary for a couple of reasons. The first has to do with the way I instructed you to build the query:
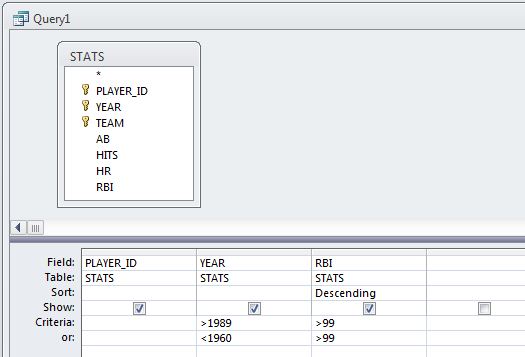
This resulted in the RBI>99 criterion inefficiently being added to the query twice. A more efficient approach would be to merge the two-year criteria into a single row in the design grid, as follows:
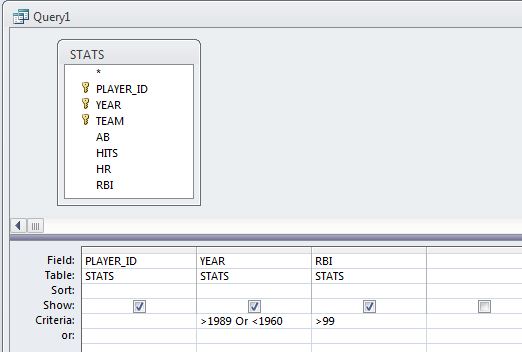
This yields a more efficient version of the statement:
SELECT STATS.PLAYER_ID, STATS.YEAR, STATS.RBI
FROM STATS
WHERE (((STATS.YEAR)>1989 Or (STATS.YEAR)<1960) AND ((STATS.RBI)>99));
It is difficult to see, but this version puts a set of parentheses around the two year criteria so that the condition of being before 1960 or after 1989 is evaluated separately from the RBI condition.
One reason the logic is difficult to follow is because the query builder adds parentheses around each column specification. Eliminating those parentheses and the table prefixes produces a more readable query:
SELECT PLAYER_ID, YEAR, RBI
FROM STATS
WHERE (YEAR>1989 Or YEAR<1960) AND RBI>99;
D. The GROUP BY clause
The GROUP BY clause was generated by the query builder when we calculated each player's career RBI total:
SELECT LAST_NAME, FIRST_NAME, Sum(RBI) AS SumOfRBI
FROM STATS
GROUP BY LAST_NAME, FIRST_NAME;
The idea behind this type of query is that you want the RDBMS to find all of the unique values (or value combinations) in the field (or fields) listed in the GROUP BY clause and include each in the result set. When creating this type of query, each field in the GROUP BY clause must also be listed in the SELECT clause. In addition to the GROUP BY fields, it is also common to use one of the SQL aggregation functions in the SELECT clause to produce an output column. The function we used to calculate the career RBI total was Sum(). Other useful aggregation functions include Max(), Min(), Avg(), Last(), First() and Count(). Because the Count() function is only concerned with counting the number of rows associated with each grouping, it doesn't really matter which field you plug into the parentheses. Frequently, SQL developers will use the asterisk rather than some arbitrary field. This modification to the query will return the number of years in each player's career, in addition to the RBI total:
SELECT LAST_NAME, FIRST_NAME, Sum(RBI) AS SumOfRBI, Count(*) AS Seasons
FROM STATS
GROUP BY LAST_NAME, FIRST_NAME;
Note: In actuality, this query would over count the seasons played for players who switched teams mid-season (e.g., Mark McGwire was traded in the middle of 1997 and has a separate record in the STATS table for each team). We'll account for this problem using a sub-query later in the lesson.
E. The ORDER BY clause
The purpose of the ORDER BY clause is to specify how the output of the query should be sorted. Any number of fields can be included in this clause, so long as they are separated by commas. Each field can be followed by the keywords ASC or DESC to indicate ascending or descending order. If this keyword is omitted, the sorting is done in an ascending manner. The query below sorts the seasons in the STATS table from the best RBI total to the worst:
SELECT PLAYER_ID, YEAR, RBI
FROM STATS
ORDER BY RBI DESC;
That concludes our review of the various clauses found in SELECT queries. You're likely to memorize much of this syntax if you're called upon to write much SQL from scratch. However, don't be afraid to use the Access query builder or other GUIs as an aid in producing SQL statements. I frequently take that approach when writing database-related PHP scripts. Even though the data is actually stored in a MySQL database, I make links to the MySQL tables in Access and use the query builder to develop the queries I need. That workflow (which we'll explore in more depth later in the course) is slightly complicated by the fact that the flavor of SQL produced by Access differs slightly from industry standards. We'll discuss a couple of the important differences in the next section.