Lesson 2: Relational Database Concepts and Theory
Overview
Overview
Now that you've gotten a taste of the power provided by relational databases to answer questions, let's shift our attention to the dirty work: designing, implementing, populating and maintaining a database.
Objectives
At the successful completion of this lesson, students should be able to:
- design a relational database and depict that design through an entity-relationship diagram;
- create new tables in MS-Access;
- develop and execute insert, update and delete queries in MS-Access;
- describe what is meant by 1st, 2nd and 3rd normal forms in database design;
- explain the concept of referential integrity.
Questions?
If you have any questions now or at any point during this week, please feel free to post them to the Lesson 2 Discussion Forum.
Checklist
Checklist
Lesson 2 is one week in length, see the Canvas Calendar for specific due dates. To finish this lesson, you must complete the activities listed below:
- Work through Lesson 2.
- Complete Project 2 and upload its deliverables to the Project 2 Dropbox.
- Complete the Lesson 2 Quiz.
Relational DBMSs Within The Bigger Picture
Relational DBMSs Within The Bigger Picture
Before digging deeper into the workings of relational database management systems (RDBMSs), it's a good idea to take a step back and look briefly at the history of the relational model and how it fits into the bigger picture of DBMSs in general. The relational model of data storage was originally proposed by an IBM employee named Edgar Codd in the early 1970s. Prior to that time, computerized data storage techniques followed a "navigational" model that was not well suited to searching. The ground-breaking aspect of Codd's model was the allocation of data to separate tables, all linked to one another by keys - values that uniquely identify particular records. The process of breaking data into multiple tables is referred to as normalization.
If you do much reading on the relational model, you're bound to come across the terms relation, attribute, and tuple. While purists would probably disagree, for our purposes you can consider relation to be synonymous with table, attribute with the terms column and field, and tuple with the terms row and record.
SQL, which we started learning about in Lesson 1, was developed in response to Codd's relational model. Today, relational databases built around SQL dominate the data storage landscape. However, it is important to recognize that the relational model is not the only ballgame in town. Object-oriented databases [1] arose in the 1980s in parallel with object-oriented programming languages. Some of the principles of object-oriented databases (such as classes and inheritance) have made their way into most of today's major RDBMSs, so it is more accurate to describe them as object-relational hybrids.
More recently, a class of DBMSs that deviate significantly from the relational model has developed. These NoSQL databases [2] seek to improve performance when dealing with large volumes of data (often in web-based applications). Essentially, these systems sacrifice some of the less critical functions found in an RDBMS in exchange for gains in scalability and performance.
Database Design Concepts
Database Design Concepts
A. Database design concepts
When building a relational database from scratch, it is important that you put a good deal of thought into the process. A poorly designed database can cause a number of headaches for its users, including:
- loss of data integrity over time
- inability to support needed queries
- slow performance
Entire courses can be spent on database design concepts, but we don't have that kind of time, so let's just focus on some basic design rules that should serve you well. A well-designed table is one that:
- seeks to minimize redundant data
- represents a single subject
- has a primary key (a field or set of fields whose values will uniquely identify each record in the table)
- does not contain multi-part fields (e.g., "302 Walker Bldg, University Park, PA 16802")
- does not contain multi-valued fields (e.g., an Author field shouldn't hold values of the form "Jones, Martin, Williams")
- does not contain unnecessary duplicate fields (e.g., avoid using Author1, Author2, Author3)
- does not contain fields that rely on other fields (e.g., don't create a Wage field in a table that has PayRate and HrsWorked fields)
B. Normalization
The process of designing a database according to the rules described above is formally referred to as normalization. All database designers carry out normalization, whether they use that term to describe the process or not. Hardcore database designers not only use the term normalization, they're also able to express the extent to which a database has been normalized:
- First normal form (1NF) describes a database whose tables represent distinct entities, have no duplicative columns (e.g., no Author1, Author2, Author3), and have a column or columns that uniquely identify each row (i.e., a primary key). Databases meeting these requirements are said to be in first normal form.
- Second normal form (2NF) describes a database that is in 1NF and also avoids having non-key columns that are dependent on a subset of the primary key. It's understandable if that seems confusing, have a look at this simple example [3] [www.1keydata.com/database-normalization/second-normal-form-2nf.php]
In the example, CustomerID and StoreID form a composite key - that is, the combination of the values from those columns uniquely identifies the rows in the table. In other words, only one row in the table will have a CustomerID of 1 together with a StoreID of 1, only one row will have a CustomerID of 1 together with a StoreID of 3, etc. The PurchaseLocation column depends on the StoreID column, which is only part of the primary key. As shown, the solution to putting the table in 2NF is to move the StoreID-PurchaseLocation relationship into a separate table. This should make intuitive sense as it spells out the PurchaseLocation values just once rather than spelling them out repeatedly. - Third normal form (3NF) describes a database that is in 2NF and also avoids having columns that derive their values from columns other than the primary key. The wage field example mentioned above is a clear violation of the 3NF rule.
In most cases, normalizing a database so that it is in 3NF is sufficient. However, it is worth pointing out that there are other normal forms including Boyce-Codman normal form (BCNF, or 3.5NF), fourth normal form (4NF) and fifth normal form (5NF). Rather than spend time going through examples of these other forms, I encourage you to simply keep in mind the basic characteristics of a well-designed table listed above. If you follow those guidelines carefully, in particular, constantly being on the lookout for redundant data, you should be able to reap the benefits of normalization.
Generally speaking, a higher level of normalization results in a higher number of tables. And as the number of tables increases, the costs of bringing together data through joins increases as well, both in terms of the expertise required in writing the queries and in the performance of the database. In other words, the normalization process can sometimes yield a design that is too difficult to implement or that performs too slowly. Thus, it is important to bear in mind that database design is often a balancing of concerns related to data integrity and storage efficiency (why we normalize) versus concerns related to its usability (getting data into and out of the database).
Earlier, we talked about city/state combinations being redundant with zip code. That is a great example of a situation in which de-normalizing the data might make sense. I have no hard data on this, but I would venture to say that the vast majority of relational databases that store these three attributes keep them all together in the same table. Yes, there is a benefit to storing the city and state names once in the zip code table (less chance of a misspelling, less disk space used). However, my guess is that the added complexity of joining the city/state together with the rest of the address elements outweighs that benefit to most database designers.
C. Example scenario
Let's work through an example design scenario to demonstrate how these rules might be applied to produce an efficient database. Ice cream entrepreneurs Jen and Barry have opened their business and now need a database to track orders. When taking an order, they record the customer's name, the details of the order such as the flavors and quantities of ice cream needed, the date the order is needed, and the delivery address. Their database needs to help them answer two important questions:
- Which orders are due to be shipped within the next two days?
- Which flavors must be produced in greater quantities?
A first crack at storing the order information might look like this:
| Customer | Order | DeliveryDate | DeliveryAdd |
|---|---|---|---|
| Eric Cartman | 1 vanilla, 2 chocolate | 12/1/11 | 101 Main St |
| Bart Simpson | 10 chocolate, 10 vanilla, 5 strawberry | 12/3/11 | 202 School Ln |
| Stewie Griffin | 1 rocky road | 12/3/11 | 303 Chestnut St |
| Bart Simpson | 3 mint chocolate chip, 2 strawberry | 12/5/11 | 202 School Ln |
| Hank Hill | 2 coffee, 3 vanilla | 12/8/11 | 404 Canary Dr |
| Stewie Griffin | 5 rocky road | 12/10/11 | 303 Chestnut St |
The problem with this design becomes clear when you imagine trying to write a query that calculates the number of gallons of vanilla that have been ordered. The quantities are mixed with the names of the flavors, and any one flavor could be listed anywhere within the order field (i.e., it won't be consistently listed first or second).
A design like the following would be slightly better:
| Customer | Flavor1 | Qty1 | Flavor2 | Qty2 | Flavor3 | Qty3 | DeliveryDate | DeliveryAdd |
|---|---|---|---|---|---|---|---|---|
| Eric Cartman | vanilla | 1 | chocolate | 2 | 12/1/11 | 101 Main St |
||
| Bart Simpson | chocolate | 10 | vanilla | 10 | strawberry | 5 | 12/3/11 | 202 School Ln |
| Stewie Griffin | rocky road | 1 | 12/3/11 | 303 Chestnut St |
||||
| Bart Simpson | mint chocolate chip | 3 | strawberry | 2 | 12/5/11 | 202 School Ln |
||
| Hank Hill | coffee | 2 | vanilla | 3 | 12/8/11 | 404 Canary Dr |
||
| Stewie Griffin | rocky road | 5 | 12/10/11 | 303 Chestnut St |
This is an improvement because it enables querying on flavors and summing quantities. However, to calculate the gallons of vanilla ordered you would need to sum the values from three fields. Also, the design would break down if a customer ordered more than three flavors.
Slightly better still is this design:
| Customer | Flavor | Qty | DeliveryDate | DeliveryAdd |
|---|---|---|---|---|
| Eric Cartman | vanilla | 1 | 12/1/11 | 101 Main St |
| Eric Cartman | chocolate | 2 | 12/1/11 | 101 Main St |
| Bart Simpson | chocolate | 10 | 12/3/11 | 202 School Ln |
| Bart Simpson | vanilla | 10 | 12/3/11 | 202 School Ln |
| Bart Simpson | strawberry | 5 | 12/3/11 | 202 School Ln |
| Stewie Griffin | rocky road | 1 | 12/3/11 | 303 Chestnut St |
| Hank Hill | coffee | 2 | 12/8/11 | 404 Canary Dr |
| Hank Hill | vanilla | 3 | 12/8/11 | 404 Canary Dr |
| Stewie Griffin | rocky road | 5 | 12/10/11 | 303 Chestnut St |
This design makes calculating the gallons of vanilla ordered much easier. Unfortunately, it also produces a lot of redundant data and spreads a complete order from a single customer across multiple rows.
Better than all of these approaches would be to separate the data into four entities (Customers, Flavors, Orders and Order Items):
| CustID | NameLast | NameFirst | DeliveryAdd |
|---|---|---|---|
| 1 | Cartman | Eric | 101 Main St |
| 2 | Simpson | Bart | 202 School Ln |
| 3 | Griffin | Stewie | 303 Chestnut St |
| 4 | Hill | Hank | 404 Canary Dr |
| FlavorID | Name |
|---|---|
| 1 | vanilla |
| 2 | chocolate |
| 3 | strawberry |
| 4 | rocky road |
| 5 | mint chocolate chip |
| 6 | coffee |
| OrderID | CustID | DeliveryDate |
|---|---|---|
| 1 | 1 | 12/1/11 |
| 2 | 2 | 12/3/11 |
| 3 | 3 | 12/3/11 |
| 4 | 2 | 12/5/11 |
| 5 | 4 | 12/8/11 |
| 6 | 3 | 12/10/11 |
| OrderItemID | OrderID | FlavorID | Qty |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 2 | 1 | 2 | 2 |
| 3 | 2 | 2 | 10 |
| 4 | 2 | 1 | 10 |
| 5 | 2 | 3 | 5 |
| 6 | 3 | 4 | 1 |
| 7 | 4 | 5 | 3 |
| 8 | 4 | 3 | 2 |
| 9 | 5 | 6 | 2 |
| 10 | 5 | 1 | 3 |
| 11 | 6 | 4 | 5 |
If one were to implement a design like this in MS-Access, the query needed to display orders that must be delivered in the next 2 days would look like this in the GUI:
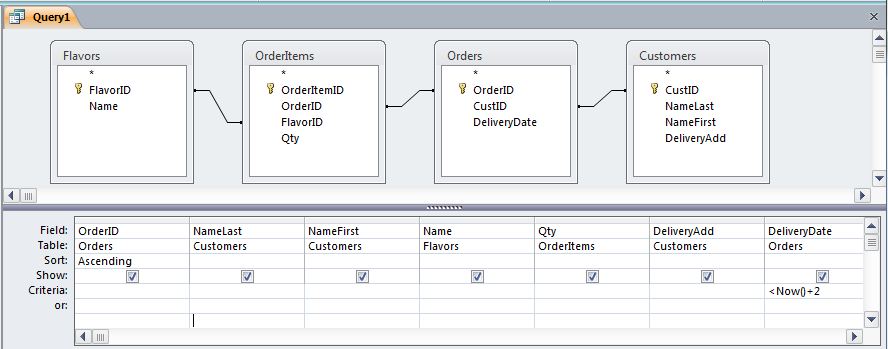
It would produce the following SQL:
If you aren't experienced with relational databases, then such a table join may seem intimidating. You probably won't need to do anything quite so complex in this course. The purpose of this example is two-fold:
- To illustrate that multi-table designs are often preferable to a "one-big-spreadsheet" approach.
- To emphasize the importance of SQL in pulling together data spread across multiple tables to perform valuable database queries.
D. Data modeling
Whether it's just a quick sketch on a napkin or a months-long process involving many stakeholders, the life cycle of any effective database begins with data modeling. Data modeling itself begins with a requirements analysis, which can be more or less formal, depending on the scale of the project. One of the common products of the data modeling process is an entity-relationship (ER) diagram. This sort of diagram depicts the categories of data that must be stored (the entities) along with the associations (or relationships) between them. The Wikipedia entry on ER diagrams is quite good, so I'm going to point you there to learn more:
Entity-relationship model article at Wikipedia [4] [http://en.wikipedia.org/wiki/Entity-relationship_model]
An ER diagram is essentially a blueprint for a database structure. Some RDBMSs provide diagramming tools (e.g., Oracle Designer, MySQL Workbench) and often include the capability of automatically creating the table structure conceptualized in the diagram.
In a GIS context, Esri makes it possible to create new geodatabases based on diagrams authored using CASE (Computer-Aided Software Engineering) tools. This blog post, Using Case tools in Arc GIS 10 [5], [http://blogs.esri.com/esri/arcgis/2010/08/05/using-case-tools-in-arcgis -10/] provides details if you are interested in learning more.
E. Design practice
To help drive these concepts home, here is a scenario for you to consider. You work for a group with an idea for a fun website: to provide a place for music lovers to share their reviews of albums on the 1001 Albums You Must Hear Before You Die list [6]. (All of these albums had been streamable from Radio Romania 3Net [7], but sadly it appears that's no longer the case.)
Spend 15-30 minutes designing a database (on paper, no need to implement it in Access) for this scenario. Your database should be capable of efficiently storing all of the following data:
- Artist
- Album Genre
- Record Label
- Album Comments
- Album
- Track Name
- Reviewer ID
- Track Rating
- Year
- Track Length
- Album Rating
- Track Comments
When you're satisfied with your design, move to the next page and compare yours to mine.
Implementing a Database Design
Implementing a Database Design
There is no one correct design for the music scenario posed on the last page. The figure below depicts one design. Note the FK notation beside some of the fields. FK stands for foreign key and indicates a field whose values uniquely identify rows in another table. There is no way to designate a field as a foreign key in MS-Access. For our purposes, you should just remember that building foreign keys into your database is what will enable you to create the table joins needed to answer the questions you envision your database answering.
Note also the 1 and * labels at the ends of the relationship lines, which indicate the number of times any particular value will appear in the connected field. As shown in the diagram, values in the Albums table's Album_ID field will appear just once; the same values in the associated field in the Tracks table may appear many times (conveyed by the * character). For example, an album with 10 tracks will have its Album_ID value appear in the Albums table just once. That Album_ID value would appear in the Tracks table 10 times. This uniqueness of values in fields is referred to as cardinality.
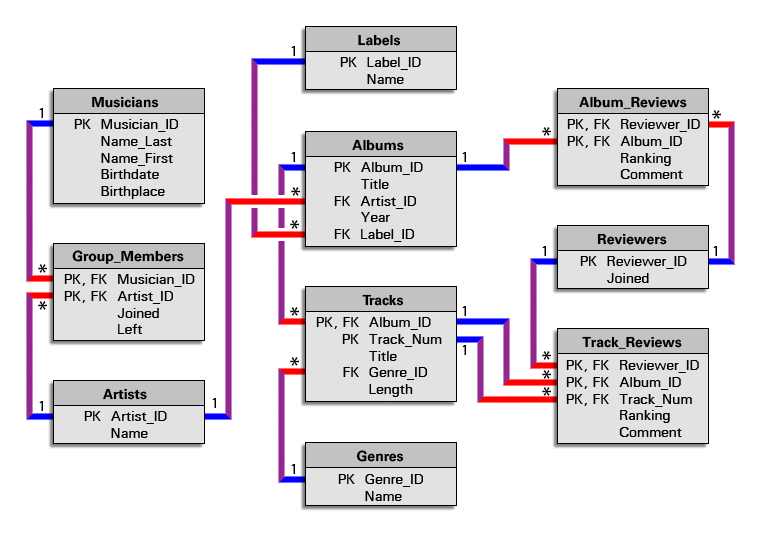
If you have questions about this design or see ways to improve it, please share your thoughts in the Lesson 2 Discussion Forum.
In this part of the lesson, we'll create and populate some of the tables depicted in the diagram above to give you a sense of how to move from the design phase to the implementation phase of a database project. Table creation is something that can be accomplished using SQL, as we'll see later in the course. Most RDBMSs also make it possible to create tables through a GUI, which is the approach we will take right now.
An integral part of creating a table is defining its fields and the types of data that can be stored in those fields. Here is a list of the most commonly used data types available in Access:
- Text - for strings of up to 255 characters
- Memo - for strings greater than 255 characters
- Number - for numeric data
- AutoNumber - for automatically incremented numeric fields; more on this below
- Yes/No - for holding values of 'Yes' or 'No'; equivalent to the Boolean type in other RDBMSs
- Date/Time - for storing dates and times
Beyond the data type, fields have a number of other properties that are sometimes useful to set. Among these are Default Value which specifies the value the field takes on by default, and Required, which specifies whether or not the field is allowed to contain Null values. It is also possible to specify that a field is the table's primary key (or part of a multi-field primary key).
Perhaps the most commonly set field property is the Field Size. For Text fields this property defaults to a value of 255 characters. This property should be set to a lower value when appropriate, for a couple of reasons. First, it will reduce the size of the database, and secondly, it can serve as a form of data validation (e.g., assigning a Field Size of 2 to a field that will store state abbreviations will ensure that no more than 2 characters are entered).
When dealing with a Number field, the Field Size property is used to specify the type of number:
- Byte - for integers ranging from 0 to 255
- Integer - for integers in the range of roughly +/- 32,000
- Long Integer - for integers in the range of roughly +/- 2 billion
- Single - for real numbers in the range of roughly +/- 1038
- Double - for real numbers in the range of roughly +/- 10308
As with Text fields, it is good practice to choose the smallest possible Field Size for a Number field.
With this background on fields in mind, let's move on to implementing the music database.
A. Create a new table
- Open Access and from the opening screen click on the Blank Database icon.
- In the right-hand panel, browse to your course folder and give the database the name music.accdb.
- Click the Create button to create the new empty database. Access will automatically create and open a blank table called Table1.
- Select View > Design View to begin modifying this table to meet your needs.
- Give the table the name Albums.
The Design View provides a grid for you to specify the names, data types and other properties for the fields (columns) you want to have in your table. Note that the table automatically has a field called ID with a data type of AutoNumber. The field is also designated as the table's Primary Key.
Note: Most RDBMSs offer an auto-incrementing numeric data type like this. It's common for database tables to use arbitrary integer fields as their primary key. If you create a field as this AutoNumber type (or its equivalent in another RDBMS), you need not supply a value for it when adding new records to the table. The software will automatically handle that for you.
- Rename the field from ID to Album_ID.
- Beneath that field, add a new one called Title.
With the 2013 version of MS Access the interface has changed some when it comes to the next two settings. The list of data types has become more streamlined and the way Field Size is set for numeric fields is different. I will indicate below what the differences are.
- Set the Title field's Data Type to Text.
In Access 2013 - set the Title field's Type to Short Text.
- Set its Field Size to 200. (This and several other options are found in the Field Properties section at the bottom of the window, under the General tab. Note that the maximum value allowed for this property is 255 characters.)
In Access 2013 - no need to set this, the Short Text type holds up to 255 characters.
FYI, the "Long Text" option in Access 2013 ("Memo" option in older Access versions) can hold up to a Gigabyte and can be configured to hold Rich Text formatted information.
- Repeat these steps to add the other fields defined for the Albums table:
In Access 2013 - To set the type and size for numeric data, you first choose Number from the Type list, then under the General tab click the FieldSize property box. Click the arrow and choose the desired field size (Integer, Long Integer, Float, etc.).Table 2.8: Albums Table Name Type Album_ID AutoNumber Title Text (200) Artist_ID Long Integer Release_Year Integer Label_ID Long Integer Note:
Try adding a field with a name of Year to see why we used the name Release_Year instead.
- When finished adding fields to the Albums table, click the Save button.
- To add the next table to the database design, click the Create tab, then Table Design.
- Repeat the steps outlined above to define the Artists table with the following fields:
Table 2.9: Artists Table Name Type Artist_ID AutoNumber Artist_Name Text (200) Year_Begin Integer Year_End Integer - Before closing the table, click in the small gray area to the left of the Artist_ID field to select that field then click on the Primary Key button on the ribbon.
- Create the Labels table with the following fields:
Table 2.10: Labels Table Name Type Label_ID AutoNumber Label_Name Text (200) - Set Label_ID as the primary key of the Labels table.
B. Establish relationships between the tables
While it's not strictly necessary to do so, it can be beneficial to spell out the relationships between the tables that you envisioned during the design phase.
- Click on Database Tools > Relationships.
- From the Show Table dialog double-click on each of the tables to add them to the Relationships layout.
- Arrange the tables so that the Albums table appears between the Artists and Labels tables.
- Like you did when building queries earlier, click on the Artist_ID field in the Artists table and drag it to the Artist_ID field in the Albums table. You should see a dialog titled "Edit Relationships".
- Check each of the three boxes: Enforce Referential Integrity, Cascade Update Related Fields, and Cascade Delete Related Records.
Checking these boxes tells Access that you want its help in keeping the values in the Artist_ID field in sync. For example:- Let's say your Artists table has only three records (with Artist_ID values of 1, 2 and 3). If you attempted to add a record to the Albums table with an Artist_ID of 4, Access would stop you, since that value does not exist in the related Artists table.
- If you change an Artist_ID value in the Artists table, all records in the Albums table will automatically have their Artist_ID values updated to match.
- If you delete an artist from the Artists table, the related records in the Albums table will be deleted as well.
- Click the Create button to establish the relationship between Artists and Albums.
- Follow the same steps to establish a relationship between Albums and Labels based on the Label_ID field.
- Save and Close the Relationships window.
With your database design implemented, you are now ready to add records to your tables.
Adding Records to a Table
Adding Records to a Table
Records may be added to tables in three ways: manually through the table GUI, using an SQL INSERT query to add a single record, and using an INSERT query to add multiple records in bulk.
A. Adding records manually
This method is by far the easiest, but also the most tedious. It is most suitable for populating small tables.
- Double-click on the Labels table in the object list on the left side of the window to open it in Datasheet mode.
- Try entering a value in the Label_ID field. You're not able to because that field was assigned a data type of AutoNumber.
- Tab to the Label_Name field, and enter Capitol. While typing, note the pencil icon in the gray selection box to the left of the record. This indicates that you are editing the record (it may be yellow depending upon the version of Access).
- Hit Tab or Enter. The pencil icon disappears, indicating the edit is complete, and the cursor moves to a new empty record.
- Add more records to your table so that it looks as follows:
Table 2.11: Label ID and Name Label_ID Label_Name 1 Capitol 2 Pye 3 Columbia 4 Track 5 Brunswick 6 Parlorphone 7 Apple Note:
When a record is deleted from a table with an AutoNumber field like this one, the AutoNumber value that had been associated with that record is gone forever. For example, imagine that the Columbia Records row was deleted from the table. The next new record would take on a Label_ID of 8. The Label_ID of 3 has already been used and will not be used again.
B. Adding a single record using an INSERT query
- Click the Create tab, then Query Design.
- Click Close to dismiss the Show Table dialog.
By default, queries in Access are of the Select type. However, you'll note that other query types are available including Append, Update, and Delete. We will work with the Append type in a moment and check out the Update and Delete types later. - Click on the Append button. You'll be prompted to specify which table you want to append to.
- Choose Artists from the drop-down list, and click OK. Note that an Append To row is added to the design grid.
- In the Field area of the design grid, enter "The Beatles" and tab out of that cell.
- Move your cursor to the Append To cell and select Artist_Name from the drop-down list.
- Move to the next column, and enter 1957 into the Field cell.
- Select Year_Begin as the Append To field for this column.
- Move to the next column, and enter 1970 into the Field cell.
- Select Year_End as the Append To field for this column. Your query design grid should look like this:
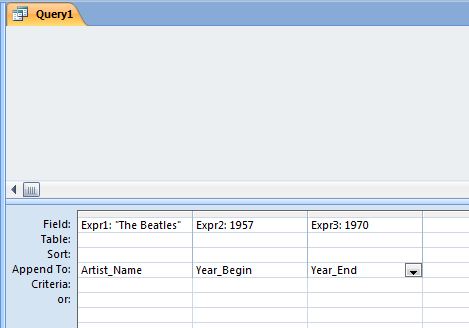 Figure 2.3: MS_Access query design grid GUI showing the layout that will result in appending one record to the database table. Note that an MS-Access Append query is actually translated into an SQL Insert query.
Figure 2.3: MS_Access query design grid GUI showing the layout that will result in appending one record to the database table. Note that an MS-Access Append query is actually translated into an SQL Insert query. - Click the Run button to execute this query. Answer Yes when asked whether you really want to append the record to the table.
- Open the Artists table, and confirm that a record for The Beatles exists.
At this point, you may be wondering why we used an Append query when I said we'd use an Insert query. - Go back to the design view window of your query, select View > SQL View, and note that what Access calls an Append query in its GUI is actually an INSERT query when translated to SQL:
INSERT INTO Artists ( Artist_Name, Year_Begin, Year_End ) SELECT "The Beatles" AS Expr1, 1957 AS Expr2, 1970 AS Expr3;
Check the Artists table to verify the addition of the new record. If your Artists table is still open, in the Home ribbon you can select Refresh then Refresh All.
If you're wondering why we bothered to write this query when we could have just entered the data directly into the table, you're right. That would be a waste of time. However, such statements are critical in scenarios in which records need to be added to tables programmatically. For example, if you've ever created a new account through some websites like amazon.com, it is likely that your form entries were committed to the site's database using an INSERT query like this one.
It is important to note that the syntax generated by the Access GUI does not follow standard SQL. Let's modify this SQL so that it follows the standard (and adds another artist to the table). - Change the query so that it reads as follows:
INSERT INTO Artists ( Artist_Name, Year_Begin, Year_End ) VALUES ( "The Kinks", 1964, 1996 );
- Click the Run button to execute the query.
- Finally, modify the query to add one more artist (and note the removal of the Year_End column and value, since The Who are considered an active band):
INSERT INTO Artists ( Artist_Name, Year_Begin ) VALUES ( "The Who", 1964 );
- Execute the query, then close it without saving.
C. Adding records from another table in bulk
The last method of adding records to a table is perhaps the most common one, the bulk insertion of records that are already in some other digital form. To enable you to see how this method works in Access, I've created a comma-delimited text file of albums released in the 1960s by the three artists above.
- Download the Albums.txt file [8] and save it to your machine.
- In Access, go to External Data > Text File. (Note the other choices available, including Access and Excel.)
- Browse to the text file on your machine and select it.
Note the three options available to you: importing to a new table, appending to an existing table and linking to the external table. The second option would make sense in this situation if the column headings in the text file matched those in the target Access table. They do not, so we will import to a new table and build a query to perform the append. - Confirm that the Import option is selected, and click OK.
- The first panel of the Import Text Wizard prompts you to specify whether your text is Delimited or Fixed Width. Confirm that Delimited is selected, and click Next.
- The next panel should automatically have Comma selected as the delimiter and double quotes as the Text Qualifier (i.e., the character used to enclose text strings). Check the First Row Contains Field Names checkbox, and click Next.
- The next panel makes it possible to override the field names and types. The wizard has correctly identified the field types for all but the Label_ID field. Click on the Label_ID heading, and change its data type to Long Integer. Click Next.
- The next panel provides an opportunity to specify the table's primary key. Options include adding a new AutoNumber field, choosing the key from the existing fields, or assigning no primary key at all. Because this table will be of no use to us after appending its records to the Albums table created earlier, select No primary key, and click Next.
- Finally, the last panel prompts you for the name to give to the table. Enter Albums_temp, and click Finish to complete the import.
- This is a one-time import process, so simply click Close when asked if you want to save the import steps.
- Double-click on Albums_temp to open it in datasheet mode, and confirm that the data imported correctly. You're now ready to build a query that will append the records from Albums_temp to Albums.
Note:
The Albums.txt text file you just imported was written assuming that the records in the Labels table are stored with Label_ID values as specified in the figure in Part A and Artist_ID values of 1 for The Beatles, 2 for The Kinks and 3 for The Who. If your tables don't have these ID values (e.g., if you ran into a problem with one of the inserts into the Artists table and had to add that artist again), you should modify the ID values in the Albums_temp table so that they match up with the ID values in your Labels and Artists tables before building the Append query in the steps below.
- Click Create > Query Design to begin building the query.
- Add the Albums_temp table to the query GUI. Do not add the Albums table. Close the Show Table dialog.
- As before, click the Append button to change the query type. You may have to go back to the Design ribbon.
- Select Albums as the Append to table, and click OK.
- Double-click on each of the fields in the Albums_temp table so that they appear in the design grid. Note that the Artist_ID and Label_ID fields are automatically paired up with the fields having the same name in the Albums table. The title and release year fields have different names, so you will have to match those fields up manually.
- In the Append To cell, select Title under the Album_Title field and Release_Year under the Released field.
If we wanted to append a subset of records from Albums_temp, we could add a WHERE clause to the query. We want to append all the records, so our query is done. - Execute the query, and confirm that the Albums table is now populated with 10 records.
- Close the query without saving. You would consider saving it if you found yourself performing this sort of append frequently.
If you were wondering why we didn't just import the text file and use the table produced by the import, that's a good observation. In this particular scenario, that would have been less work. However, the process we just followed is a common workflow, particularly when you are looking to append new records to a table that is already populated with other records. In that scenario, this methodology would be more clearly appropriate.
Updating Existing Records
Updating Existing Records
As with adding records, updating existing records can be done both manually through the GUI and programmatically with SQL. The manual method simply requires navigating to the correct record (sorting the table can often help with this step) and replacing the old value(s) with new one(s).
SQL UPDATE statements are used in a couple of different scenarios. The first is when you have bulk edits to make to a table. For example, let's say you wanted to add a region field to a states table. You might add the field through the table design GUI, then execute a series of UPDATE queries to populate the new region field. The logic of the queries would take the form, "Update the region field to X for the states in this list Y." We'll perform a bulk update like this in a moment.
The other common usage for the UPDATE statement goes back to the website account scenario. Let's say, you've moved and need to provide the company with your new address. Upon clicking the Submit button, a script will generate and execute an UPDATE query on your record in the table.
A. Performing an UPDATE query
After working with your album database for a while, you notice that you're constantly using string concatenation to add the word "Records" to the names of the companies in the Labels table. You decide that the benefit of adding that text to the label names outweighs the drawback of storing that text redundantly.
- Select Create > Query Design.
- Add the Labels table to the query design GUI, and close the Show Tables dialog.
- In the Query Type section of the Design ribbon, change the query type from Select to Update. Note that the Show and Sort rows in the design grid disappear (this query type doesn't show any results) and an Update To row takes their place.
- Double-click on the Label_Name field to add it to the design grid.
- In the Update To cell, enter the following expression (be sure to include the space before the word Records):
[Labels]![Label_Name] & " Records"
If you needed to, you could specify selection criteria to limit the update to a subset of records. For example, following on the state-region example mentioned above, you might update the region field to "New England" using a WHERE condition of:
WHERE state IN ('CT','MA','ME','NH','RI','VT').
In this case, we want to perform this update on all records, so our query is done. - Execute the query and open, or refresh, the Labels table to confirm that it worked.
- Return to the query and select View > SQL View to see the SQL statement that you created through the GUI:
UPDATE Labels SET Labels.Label_Name = [Labels]![Label_Name] & " Records";
As discussed earlier when we were dealing with SELECT queries, the brackets and exclamation point do not follow the SQL standard. You could also omit the parent table in the field specification if there is no chance of duplicate field names in your query. Thus, the following syntax would also work and be closer to standard SQL:
UPDATE Labels SET Label_Name = Label_Name & " Records";
Also, as mentioned before, concatenation requires a different syntax depending on the RDBMS. - Close the query without saving.
Deleting Records
Deleting Records
When working in Access, deleting records can be as easy as opening the table, navigating to the desired records, selecting them using the gray selection boxes to the left of the records, and hitting the Delete key on the keyboard. Likewise, it is possible to follow the same methodology to delete records returned by a SELECT query (if it's a one-table query).
However, as with the other query types, it is sometimes necessary to write a query to perform the task. For example, if you've ever canceled a hotel reservation or an order from an online vendor, a DELETE query was probably executed behind the scenes. Let's see how such a query can be built using the Access GUI and examine the resulting SQL.
A. Deleting records
Let's say a revised version of the 1001 albums list is released, and the albums recorded by The Who on the Track Records label have dropped off the list. Knowing that Track Records no longer has albums on the list, you decide to delete it from the Labels table.
- Select Create > Query Design.
- Double-click on Labels to add it to the query design GUI, then close the Show Tables dialog.
- Change the query type to Delete. As with the Update query, the Sort and Show rows disappear from the design grid, replaced by a Delete row.
- Double-click * to add it to the design grid. You should see the keyword From appear in the Delete row of the design grid.
While it's possible to bring down an individual field instead of *, which implies that it might be possible to delete values in a particular field only, that's not really the case. Delete queries are used to delete entire rows meeting certain criteria. If you want to wipe out the values in a field, leaving other field values intact, you should use an Update query. - Double-click Label_Name to add it to the design grid. You should see the keyword Where appear in the Delete row of the design grid.
- In the Criteria cell, enter "Track Records".
- Execute the query.
- You should be asked to confirm that you really want to delete the 1 record meeting your criteria. Answer Yes to go ahead with the deletion.
- Open the Labels table and verify that the record has been deleted.
- Open the Albums table and note that The Who Sell Out and Tommy have been deleted from that table also. This deletion was carried out because of the Cascade Delete Related Records setting we made earlier. If we had not checked that box, the two albums would be left in the Albums table referring to a record label that does not exist in the Labels table.
- Return to the query, and select View > SQL View. Note the statement produced by the GUI:
DELETE Labels.*, Labels.Label_Name FROM Labels WHERE (((Labels.Label_Name)="Track Records"));
Again, this statement could be simplified as follows:DELETE * FROM Labels WHERE Label_Name="Track Records";
- Close the query without saving.
One final note before moving on to the graded assignment. I had you delete the record label from the database because I wanted to show you how to write a DELETE query. However, think about other actions you might have taken instead under that scenario. Depending on the circumstance, it might make more sense to leave that label in the database and delete only the albums (in case the label once again has an album on the list). The upside of deleting the label is that answering a question like, "Which record companies released the albums on the list?" requires dealing only with the Labels table. On the other hand, if the Labels table included companies that had no albums on the list, answering that question would require a more complex query, involving a join between Albums and Labels.
Another response to the revised-list scenario might be to make it possible for the database to store all versions of the list, rather than just its current state. Generally speaking, it's better to err on the side of keeping data versus deleting. Doing so makes your database capable of answering a larger array of questions; it's quite common for database users to come up with questions that could not have been predicted in the initial design. The downside to this decision is that it necessitates changes to the database design. What changes would be required in this scenario?
Project 2: Designing a Relational Database
Project 2: Designing a Relational Database
This lesson focused on concepts involved in the design of a relational database. To demonstrate your understanding of these concepts, you'll now complete an exercise in database design. Here is the scenario; you work for a UFO investigation organization that has collected a lot of information related to sightings, and you've been tasked with designing a database that will be used as the back end for a website. The information to be stored in the database includes the following:
- sighting date/time
- object shape (saucer, cigar, etc.)
- sighting coordinates (latitude, longitude)
- witness name, phone # and email address
- textual descriptions of the sighting
In addition to this basic information, the organization has many digital files that must be made available through the website:
- photos
- videos
- drawings
- audio (interviews with witnesses)
While most RDBMSs make it possible to store such data in the form of BLOBs (Binary Large OBjects), doing so can be tricky. An alternative approach is to store the names of the files and use front-end application logic to present the file data appropriately.
If you have access to software that can be used to produce an entity-relationship diagram of your proposed database structure, feel free to use it. However, hand-drawn and scanned diagrams are perfectly acceptable as well. If you don't have access to a scanner at home or work, try your local library or FedEx Office store.
As part of your submission, please include notations of the key fields (primary and foreign), the relationships and cardinality between tables, and a short narrative that explains the thinking that went into your design.
Deliverables
This project is one week in length. Please refer to the Canvas Calendar for the due date.
- Upload your ER diagram and narrative to the Project 2 Dropbox, 100 of 100 points.
- Complete the Lesson 2 quiz.