Why a database?
Reading your web map data from a shapefile or XML file works fine in certain situations. However, it's not difficult to think of scenarios in which using flat files like these presents problems:
- if the data are frequently changing, you'll need to have a step built into your business process that ensures there is an up-to-date copy of the files on the web server;
- if you want to provide the user with the ability to map subsets of a larger dataset, doing so with flat files data can be clunky;
- if you want to make it possible to allow updates of the data.
A major goal of this lesson is for you to learn how to write PHP scripts to extract data from a database and output it in XML form. Once you've built such a script, with just a minor tweak to your map page you can go from reading a static XML file to reading XML data generated on the fly based on up-to-date information from your database. But before we get to that point, let's first go over some basic RDBMS concepts.
Note
If you're experienced in working with relational databases, you can probably skip over the rest of this page.
What is a relational database?
A relational database is a system in which data are stored in tables of rows (records) and columns (fields). The defining characteristic of a relational database is that the full data set is broken down into multiple tables (each representing a single subject) and that relationships can be established between those tables through the use of key fields. Structured Query Language (SQL, sometimes pronounced "sequel") is used in an RDBMS to manipulate the tabular data.
There are many RDBMS software packages to choose from. In the commercial realm, Oracle has long been the most popular, followed by IBM's DB2 and Microsoft's SQL Server. In the open-source realm, MySQL and PostgreSQL are the major players. Microsoft Access is a relatively inexpensive package that is best suited for small datasets. Because of its user-friendly point-and-click environment, it is also frequently used as a "front-end" to more high-powered package — i.e., to connect to and manipulate data that are actually stored in a separate RDBMS.
In this course, we're going to create and populate MySQL databases using MS-Access as a front end.
Using SQL to select data
There are a number of database concepts that we should cover if you're going to build a database-driven mashup. Rather than start with database design concepts, which can be a bit dry, let's begin by looking at how SQL can be used to query an existing database. After getting a feel for the power of SQL, you should be more motivated to work towards understanding the less exciting steps involved in creating and populating a database.
The example queries in this section read data from a simple, two-table database of baseball statistics. Here are excerpts from these tables:
| PLAYER_ID | FIRST_NAME | LAST_NAME |
|---|---|---|
| 1 | Barry | Bonds |
| 2 | Hank | Aaron |
| 3 | Babe | Ruth |
| 4 | Willie | Mays |
| 5 | Sammy | Sosa |
| PLAYER_ID | YEAR | AB | HITS | HR | RBI | TEAM |
|---|---|---|---|---|---|---|
| 1 | 2006 | 367 | 99 | 26 | 77 | SFG |
| 1 | 2007 | 340 | 94 | 28 | 66 | SFG |
| 2 | 1954 | 468 | 131 | 13 | 69 | MLN |
| 2 | 1955 | 602 | 189 | 27 | 106 | MLN |
| 2 | 1956 | 609 | 200 | 26 | 92 | MLN |
First, let's look at a query that simply lists data from three selected columns in the STATS table:
| SELECT PLAYER_ID, YEAR, HR FROM STATS; |
|
Note the basic syntax used to list tabular data. The statement begins with the SELECT keyword and is followed by a list of the desired columns separated by commas. After the list of columns comes the FROM keyword and the name of the table in which the columns are found. The statement ends with a semi-colon. (Note that all columns can be retrieved using the asterisk; e.g., SELECT * FROM STATS;).
We can retrieve records that meet some criteria by adding a WHERE clause. For example, this query lists only those seasons in which the player had more than 50 home runs:
| SELECT PLAYER_ID, YEAR, HR FROM STATS WHERE HR > 50; |
|
This list is begging to be sorted from high to low. To do that, we need to add an ORDER BY clause:
| SELECT PLAYER_ID, YEAR, HR FROM STATS WHERE HR > 50 ORDER BY HR DESC; |
|
If you wanted to sort from low to high, you would replace the DESC keyword with ASC or simply omit that keyword altogether (i.e., ascending order is the default). Also, keep in mind that it is possible to sort by multiple fields. For example, it is common to sort lists of people first by their last name, then by their first name. Such an ORDER BY clause would look like this: ORDER BY LAST_NAME, FIRST_NAME.
By now, I'm sure you're wondering how to view the names of the players along with their stats. This is done by joining the two tables based on the PLAYER_ID column they share in common. The following query brings together the names from the PLAYERS table and the year and HR count from the STATS table for the 50+ HR subset we've been working with:
|
SELECT PLAYERS.FIRST_NAME, PLAYERS.LAST_NAME, STATS.YEAR, STATS.HR |
|
Note that the FROM clause in this statement sandwiches the keywords INNER JOIN between the names of the two tables. The FROM clause is then immediately following by an ON clause in which the key fields to be used to create the join are specified. The field names are prefaced by the names of their parent tables using a "table.field" syntax. You may have noticed that the field names in the SELECT clause were also prefaced by their parent table names. This is not technically necessary if it is clear to the SQL execution engine which table holds each field. In other words, the FIRST_NAME field is found only in the PLAYERS table, so there is no question as to where to find that field. If on the other hand a FIRST_NAME field existed in both tables, it would be critical to include a reference to the appropriate table. This example errs on the side of caution by including the parent table names.
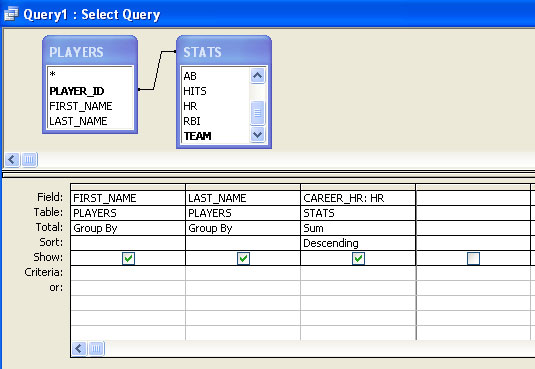
One of the more powerful features of SQL is the ability to group records by one or more fields and calculate summary statistics for each resulting group. In the example below, each player's career home run total is calculated:
|
SELECT PLAYERS.FIRST_NAME, PLAYERS.LAST_NAME, Sum(STATS.HR) AS CAREER_HR |
|
The first item to note in this statement is its GROUP BY clause. This clause specifies that you would like the SQL execution engine to output all of the unique FIRST_NAME/LAST_NAME combinations. The other part of the statement to pay particular attention to is the Sum(STATS.HR) AS CAREER_HR part. This specifies that you would like to have the sum of the values in the HR field for each FIRST_NAME/LAST_NAME combination included in the output under a heading of CAREER_HR.
Earlier I mentioned that MS-Access is frequently used as a "front-end" to more powerful RDBMS packages like Oracle and MySQL. One of the reasons for this is that Access has a user-friendly graphical user interface (GUI) for building queries. For example, here is a look at the Access query GUI after building the previous query:
Database design
When building a relational database from scratch, it is important that you put good deal of thought into the process. A poorly designed database can cause a number of headaches for its users, including:
- loss of data integrity over time
- inability to support needed queries
- slow performance
Entire courses can be spent on database design concepts, but we don't have that kind of time, so let's just focus on some basic design rules that should serve you well. A well-designed table is one that:
- represents a single subject;
- has a primary key (a field or set of fields that uniquely identifies each record in the table);
- does not contain multi-part fields (e.g., "302 Walker Bldg, University Park, PA 16802");
- does not contain multi-valued fields (e.g., an Author field shouldn't hold values of the form "Jones, Martin, Williams");
- does not contain unnecessary duplicate fields (e.g., avoid using Author1, Author2, Author3);
- does not contain fields that rely on other fields (e.g., don't create a Wage field in a table that has PayRate and HrsWorked fields);
- contains a minimum of redundant data.
Let's work through an example design scenario to demonstrate how these rules might be applied to produce an efficient database. Those ice cream entrepreneurs, Jen and Barry, have opened their business and now need a database to track orders. When taking an order, they record the customer's name, the details of the order such as the flavors and quantities of ice cream needed, the date the order is needed, and the delivery address. Their database needs to help them answer two important questions:
- Which orders are due to be shipped within the next two days?
- Which flavors must be produced in greater quantities?
A first crack at storing the order information might look like this:
| Customer | Order | DeliveryDate | DeliveryAdd |
|---|---|---|---|
| Eric Cartman | 1 vanilla, 2 chocolate | 12/1/08 | 101 Main St |
| Bart Simpson | 10 chocolate, 10 vanilla, 5 strawberry | 12/3/08 | 202 School Ln |
| Stewie Griffin | 1 rocky road | 12/3/08 | 303 Chestnut St |
| Bart Simpson | 3 mint chocolate chip, 2 strawberry | 12/5/08 | 202 School Ln |
| Hank Hill | 2 coffee, 3 vanilla | 12/8/08 | 404 Canary Dr |
| Stewie Griffin | 5 rocky road | 12/10/08 | 303 Chestnut St |
The problem with this design becomes clear when you imagine trying to write a query that calculates the number of gallons of vanilla that have been ordered. The quantities are mixed with the names of the flavors and any one flavor could be listed anywhere within the order field (i.e., it won't be consistently listed first or second).
A design like the following would be slightly better:
| Customer | Flavor1 | Qty1 | Flavor2 | Qty2 | Flavor3 | Qty3 | DeliveryDate | DeliveryAdd |
|---|---|---|---|---|---|---|---|---|
| Eric Cartman | vanilla | 1 | chocolate | 2 | 12/1/08 | 101 Main St | ||
| Bart Simpson | chocolate | 10 | vanilla | 10 | strawberry | 5 | 12/3/08 | 202 School Ln |
| Stewie Griffin | rocky road | 1 | 12/3/08 | 303 Chestnut St | ||||
| Bart Simpson | mint chocolate chip | 3 | strawberry | 2 | 12/5/08 | 202 School Ln | ||
| Hank Hill | coffee | 2 | vanilla | 3 | 12/8/08 | 404 Canary Dr | ||
| Stewie Griffin | rocky road | 5 | 12/10/08 | 303 Chestnut St |
This is an improvement because it enables querying on flavors and summing quantities. However, to calculate the gallons of vanilla ordered, you would need to sum the values from three fields. Also, the design would break down if a customer ordered more than three flavors.
Slightly better still is this design:
| Customer | Flavor | Qty | DeliveryDate | DeliveryAdd |
|---|---|---|---|---|
| Eric Cartman | vanilla | 1 | 12/1/08 | 101 Main St |
| Eric Cartman | chocolate | 2 | 12/1/08 | 101 Main St |
| Bart Simpson | chocolate | 10 | 12/3/08 | 202 School Ln |
| Bart Simpson | vanilla | 10 | 12/3/08 | 202 School Ln |
| Bart Simpson | strawberry | 5 | 12/3/08 | 202 School Ln |
| Stewie Griffin | rocky road | 1 | 12/3/08 | 303 Chestnut St |
| Hank Hill | coffee | 2 | 12/8/08 | 404 Canary Dr |
| Hank Hill | vanilla | 3 | 12/8/08 | 404 Canary Dr |
| Stewie Griffin | rocky road | 5 | 12/10/08 | 303 Chestnut St |
This design makes calculating the gallons of vanilla ordered much easier. Unfortunately, it also produces a lot of redundant data and spreads a complete order across multiple rows.
Better than all of these approaches would be to separate the data into four entities (Customers, Flavors, Orders, and Order Items):
If one were to implement a design like this in MS-Access, the query needed to display orders that must be delivered in the next 2 days would look like this in the GUI: 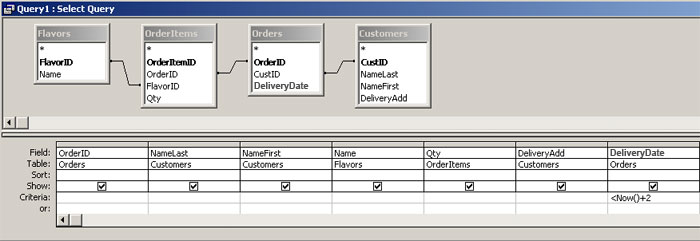
It would produce the following SQL: SELECT Orders.OrderID, Customers.NameLast, Customers.NameFirst, Flavors.Name As Flavor, If you aren't experienced with relational databases, then such a table join may seem intimidating. You probably won't need to do anything quite so complex in this course. The purpose of this example is two-fold:
Try This!To get some practice with building queries, work through this tutorial that references the same baseball statistics database utilized above.
|