The tile cache you just built was pretty straightforward. You just gave the tool a map with symbology defined for each scale level, it created tiles, and within a few minutes, you had your cache. In this case, you were fortunate that you just needed a cache of Little Rock, Arkansas. But what if you needed a cache of the entire United States, or world, down to a large scale like 1:4,500? This could take days or weeks to build, and could require terabytes of disk space. Even if you were successful at building such a cache, would you be able to do it again if the source data were updated?
This section of the lesson discusses strategic approaches for building large caches. These are presented in the order that they should be considered, meaning that if you skip down and implement one of the later strategies first, you still may end up doing things inefficiently.
Using an existing tile cache
If you need a tile cache that covers an enormous area at large scales, it would be worth your while to consider using one that someone else has built. Why go to the trouble if someone else has done it already? You've seen these types of worldwide tiled map services already throughout this course. They include ArcGIS Online, Bing Maps, and Google Maps. The companies who have built these caches have spent many thousands of dollars and hours collecting the data (often competing against each other for the best quality), building the tiles, and purchasing the hardware to serve them out in a rapid way. If you can get away with using them, you may save much time and resources.
The disadvantage of using someone else's tiles is that you cannot guarantee the accuracy or currency of the data. You don't get to choose the symbology or projection of the data either. Usually, you have to work in the Mercator projection.
Finally, if the tiled service goes offline for some reason or you lose your connection, you may have no control over when it will reappear. No server, whether it's maintained by Microsoft, Google, or Esri, can guarantee 100% uptime; however, this applies to your own servers as well. It's likely that these third-party services have better hardware infrastructure than your own when it comes to serving tiles; however, those tiles must still cross the Internet to get to your app, and that opens the door to potential connectivity problems.
Some organizations, especially those in the military and intelligence communities, have much of their network blocked from Internet access. Recognizing this, some tiled map service providers sell an appliance, basically a big server containing all the map tiles that can be plugged into your network. This eliminates the Internet access requirements, but still requires you to load periodic updates to the appliance. The Esri Data Appliance for ArcGIS is an example of this type of appliance.
Creating tiles selectively
Some areas of a web map generate a lot more attention than other areas. Someone looking for directions to a particular house may zoom in down to the largest available scale in an urban area. However, in the middle of the desert where there are few geographic features to see, it's unlikely that someone would ever zoom to a very large scale such as 1:1100 (the largest scale offered by ArcGIS Online/Bing Maps/Google Maps).
Creating tiles at small scales isn't a problem since it takes relatively few tiles to cover the map, but if you are limited on time or disk space, it pays to be selective about which tiles you cache at the largest scales.
Some GIS professionals have a hard time accepting the fact that they don't need to create every tile at every scale. They feel that all places are created equal, and shudder at the idea that someone might zoom to an area of their map and see a "Data not available" image. In fact, such an experience is now commonplace among laypeople who use web maps, who tend to blame themselves when they see a "Data not available" tile ("Oh, I zoomed in too far") as opposed to blaming the server administrator ("Why isn't there a map here!?")
A useful website for countering the idea that "all places are created equal" was Microsoft Hotmap, an old project by Microsoft Researchers to visualize tile usage in Virtual Earth (now Bing Maps). This site is no longer functioning, but a screenshot below will give you an idea of its appearance. You could open Hotmap and zoom into your town, then use the Select Data Level dropdown to visualize tile usage at different levels. At the zoomed out data levels, most of the tiles are requested fairly often. But when you get down to the zoomed in data levels (17 - 19), some clear patterns begin to emerge regarding where people want to see tiles: urban areas, major roads, coastlines, and other areas of interest. There are also some places where people never or rarely view tiles: wilderness areas, bodies of water, and so on. These are the tiles you don't want to spend your resources creating and storing (for more images and analysis see Fisher D 2007 Hotmap: Looking at geographic attention. IEEE Transactions on Visualization and Computer Graphics 13: 1184-91 and Fisher D 2009 The Impact of Hotmap. WWW Document.
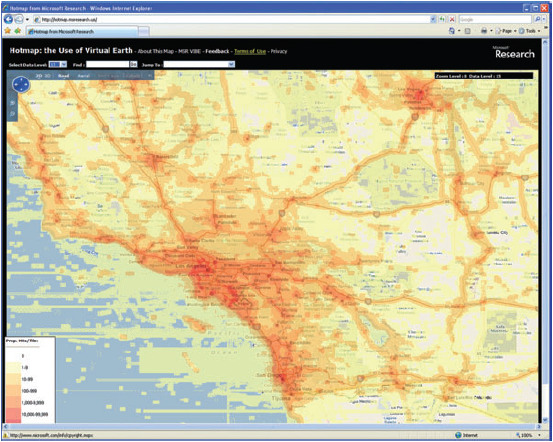
A few years ago, one of the authors of this course undertook a project to selectively cache the state of California using the observed usage patterns in Hotmap. He and his colleague combined urban areas, roads, coastlines, and places of interest into a single vector dataset that covered about 25% of the land area of California, but included about 97% of its population. The use of this dataset to define tile creation, as opposed to the entire state boundary, saved nearly 1 million tiles when caching down to the 1:4500 scale (see Quinn S and Gahegan M 2010 A predictive model for frequently viewed tiles in a web map. Transactions in GIS 14: 193-216).
When using ArcGIS Server to create tiles, there are a couple of settings on the Manage Map Server Cache Tiles tool that allow you to be strategic about which tiles you create. These are the ability to check on and off the scales you want to create, and the ability to pass in a feature class boundary that will define the area of tile creation. For a large caching job, you'll probably run the tool at least twice. The first time, you'll have only the small scales checked, and you won't pass in a feature class, you'll just create all the tiles. The second time, you'll have only the large scales checked, and you will pass in a feature class constraining the area where you want to create tiles, just like you did in the previous section of the lesson where you passed in the urban Little Rock feature class.
Optimizing the map drawing speed
The faster a map draws dynamically, the faster it will create cache tiles. All GIS software has its potential tweaks that can be made to increase performance, and ArcGIS is no exception. You've already learned, for example, that you can analyze your map using the Analyze button and see a list of potential performance issues.
Anything you can do to reduce computation will help your map draw faster. Matching the coordinate system of your source data, your data frame, and your web map will eliminate any costly projection on the fly. Saving out your labels to annotation (a way of storing labels in a database) will relieve the server from having to make label placement decisions while it is drawing your map. Spatial indexes can help your map more quickly find the features that it needs to draw for each requested tile.
Increasing computing resources
The more computing power you can put behind creating tiles, the faster you can build your cache. CPU and memory restraints are often more of a problem than having enough disk space to store the tiles.
There are two ways you can increase your server computing power, scaling up or scaling out. Scaling up means you replace your existing machine with something more powerful, like we did in this lesson. Scaling out means that you add more servers to your architecture, with these servers possibly all having the same size and spec.
The concept of having more than one server working on one job is called distributed computing. Although distributed computing can allow you to do great things, it comes with some unique challenges. All machines have to be able to see the data and access it, which may require some adjustment of paths used in your maps. For example, in a distributed setup, you want to use network paths like \\server\data, instead of local paths like c:\data. Cloud Formation sets up your site so that if you put your data in C:\data on the site server instance (one named SITEHOST, for example), you can reference it through the path \\SITEHOST\data from any machine in your site.
Distributed computing may also require some adjustment of security settings so that the tile creation software has permissions to access the data from any machine. In ArcGIS Server, this is accomplished by giving the ArcGIS Server account permissions to your data folder (Cloud Builder does this for you), and registering the data folder with ArcGIS Server (you did this earlier in the course).
Building a cache in the cloud
Cloud computing can be an attractive environment for building caches, because you can access a higher level of computing power than you might typically have in your office. Usually, you only need it for a short period (a few hours or days to create all the tiles), so the prospect of renting a server by the hour becomes very attractive.
One challenge with building tiles in the cloud is moving them around. First, you have to get your data onto the cloud so that your caching software can quickly get it as the tiles are being drawn. Then you have to move the tiles back to their final home, which may be on premises. Both of these transactions involve moving data across the Internet and can be influenced by your organizations' bandwidth and security policies.
When creating tiles with ArcGIS Server on Amazon EC2, it's a lot easier to scale up than to scale out. As you have seen, Amazon offers the option to change the instance type (in other words, CPU, memory, etc.) without terminating the instance. This is very handy when you start doing something and realize you need a bigger machine, although you are required to stop the instance before you change size. Some of the largest instance types on Amazon EC2 have an enormous degree of CPU power and may negate the need to scale out. Scaling out ArcGIS Server on Amazon EC2 is accomplished by adding more GIS server machines to your site.
Summary
Think back over the above strategies and consider why the techniques at the beginning should be employed before those at the end. It can be exciting to think about how many tiles you can build with distributed computing and all the computing horsepower that's available through the cloud. You may actually save the most time and resources by carefully planning which scales you want to create and selectively generating tiles at the largest scales. If the cache is still going to be overwhelmingly large, consider using an existing cache or a data appliance. By using a combination of the above strategies, you can usually find a way to build the cache you need, whatever the size.