Van Westendorp Meter
Introduction

The Van Westendorp meter (or more properly referred to as the "Van Westendorp Price Sensitivity Meter") is somewhat of an extension of the direct consumer survey we eschewed a few brief topics ago. But, like many methodologies related to pricing and analyzing perceived benefit in offerings, the Van Westendorp offers a few advantages that may make it more appealing in use.
A brief walkthrough of the Van Westendorp in practice from Mike Pritchard:
First, a refresher. Van Westendorp's Price Sensitivity Meter is one of a number of direct techniques to research pricing. Direct techniques assume that people have some understanding of what a product or service is worth, and therefore that it makes sense to ask explicitly about price. By contrast, indirect techniques, typically using conjoint or discrete choice analysis, combine the price with other attributes, ask questions about the total package, and then extract feelings about price from the results.
I prefer direct pricing techniques in most situations for several reasons:
- I believe people can usually give realistic answers about price.
- Indirect techniques are generally more expensive because of setup and analysis.
- It is harder to explain the results of conjoint or discrete choice to managers or other stakeholders.
- Direct techniques can be incorporated into qualitative studies in addition to their usual use in a survey.
Remember that all pricing research makes the assumption that people understand enough about the landscape to make valid comments. If someone doesn't really have any idea about what they might be buying, the response won't mean much regardless of whether the question is direct or the price is buried. Lack of knowledge presents challenges for radically new products. This aspect is one reason why pricing research should be treated as providing an input into pricing decisions, not a complete or absolute answer.
Other than Van Westendorp, the main direct pricing research methods are these:
- Direct open-ended questioning ("How much would you pay for this"). This is generally a bad way to ask, but you might get away with it at the end of an in-depth (qualitative) interview.
- Monadic ("Would you be willing to buy at $10"). This method has some merits, including being able to create a demand curve with a large enough sample and multiple price points. But there are some problems, chief being the difficulty of choosing price points, particularly when the prospective purchaser's view of value is wildly different from the vendor's. Running a pilot might help, but you run the risk of having to throw away results from the pilot. But if you include open-ended questions for comments, and people tell you the suggested price is ridiculous, at least you'll know why nobody wants to buy at the price you set in the pilot. Monadic questioning is pretty simple, but it is generally easy to do better without much extra work.
- Laddering ("would you buy at $10", then "would you buy at $8" or "would you still buy at $12″). Don't even think about using this approach, as the results won't tell you anything. The respondent will treat the series of questions as a negotiation rather than research. If you wanted to ask about different configurations the problem is even worse.
Van Westendorp's Price Sensitivity Meter uses open-ended questions combining price and quality. Since there is an inherent assumption that price is a reflection of value or quality, the technique is not useful for a true luxury good (that is, when sales volume increases at higher prices). Peter Van Westendorp introduced the Price Sensitivity Meter in 1976 and it has been widely used since then throughout the market research industry.
How to Set Up and Analyze Using Van Westendorp Questions:
The actual text typically varies with the product or service being tested, but usually the questions are worded like this:
- At what price would you begin to think product is too expensive to consider?
- At what price would you begin to think product is so inexpensive that you would question the quality and not consider it?
- At what price would you begin to think product is getting expensive, but you still might consider it?
- At what price would you think product is a bargain – a great buy for the money?
There is debate over the order of questions, so you should probably just choose the order that feels right to you.
The questions can be asked in-person, by telephone, on paper or (most frequently these days) via online questionnaire. In the absence of a human administrator who can assure comprehension and valid results, online or paper surveys require well-written instructions. You may want to emphasize that the questions are different and highlight the differences. Some researchers use validation to force the respondent to create the expected relationships between the various values, but if done incorrectly this can backfire (see my earlier post). If you can't validate in real-time (some survey tools won't support the necessary programming), then you'll need to clean the data (eliminate inconsistent responses) before analyzing. Whether you validate or not, remember that the questions use open-ended numeric responses. Don't make the mistake of imposing your view of the world by offering ranges.
Excel formulae make it easy to do the checking, but to simplify things for an eyeball check, make sure the questions are ordered in your spreadsheet as you would expect prices to be ranked, that is Too Cheap, Bargain, Getting Expensive, Too Expensive.
Ensure that the values are numeric (you did set up your survey tool to store values rather than text didn't you?–If not another Excel manipulation is needed), and then create your formula like this:IF(AND(TooCheap<=Bargain,Bargain<=GettingExpensive, GettingExpensive<=TooExpensive), OK, FAIL)
You should end up with something like this extract:
Survey Data ID Too Cheap Bargain GettingExpensive TooExpensive Valid 1 40 100 500 500 OK 2 1 99 100 500 OK 3 10 2000 70000 100 FAIL 4 0 30 100 150 OK 5 0 500 1000 1000 OK Perhaps respondent 3 didn't understand the wording of the questions, or perhaps (s)he didn't want to give a useful response. Either way, the results can't be used. If the survey had used validation, the problem would have been avoided, but we would also have run the risk of annoying someone and causing them to terminate, potentially losing other useful data. Not an easy call.
Now you need to analyze the valid data. Van Westendorp results are displayed graphically for analysis, using plots of cumulative percentages. I use Excel's Histogram tool to generate the values for the plots. You'll need to set up the buckets, so it might be worth rank ordering the responses to get a good idea of the right approach. Or you might have an idea of price increments that make sense.
Create your own buckets, otherwise the Excel Histogram tool will make its own from the data, but they won't be helpful.
Just to make the process even more complicated, you will need to plot inverse cumulative distributions (1 minus the number from the Histogram tool) for two of the questions – Too Cheap and Getting Expensive. Warning: if you search online you may find that plots vary, particularly in which questions are flipped. What I'm telling you here is my approach which seems to be the most common, and is also consistent with the Wikipedia article, but the final cross check is the vocalizing test, which we'll get to shortly.
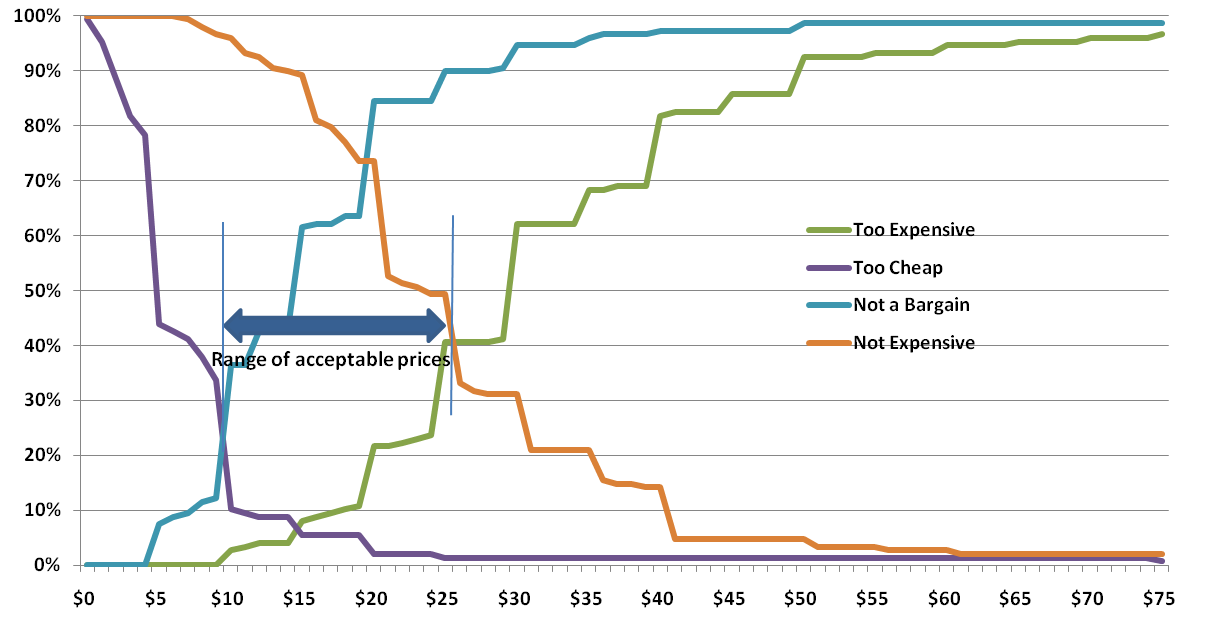 Credit: n.a. “Van Westendorp pricing (the Price Sensitivity Meter).” 5 Circles Research.Click for a text descriptionGraph with % of people on the y-axis and $ on the x-axis. The graph has four lines labeled too cheap, too expensive, not a bargain, and not expensive. Too expensive and not a bargain increase as price increases while not expensive and too cheap drop. Not a bargain intersects too cheap at $10. Too expensive and not expensive intersect at $25. In between $10 & $25 is the range of acceptable prices.
Credit: n.a. “Van Westendorp pricing (the Price Sensitivity Meter).” 5 Circles Research.Click for a text descriptionGraph with % of people on the y-axis and $ on the x-axis. The graph has four lines labeled too cheap, too expensive, not a bargain, and not expensive. Too expensive and not a bargain increase as price increases while not expensive and too cheap drop. Not a bargain intersects too cheap at $10. Too expensive and not expensive intersect at $25. In between $10 & $25 is the range of acceptable prices.Before we get to interpretation, let's apply the vocalization test. Read some of the results from the plots to see if everything makes sense intuitively.
"At $10, only 12% think the product is NOT a bargain, and at $26, 90% think it is NOT a bargain."
"44% think it is too cheap at $5, but at $19 only 5% think it is too cheap."
"At $30, 62% think it is too expensive, while 31% think it is NOT expensive – meaning 69% think it is getting expensive" (Remember these are cumulative – the 69% includes the 62%). Maybe this last one isn't a good example of the vocalization check as you have to revert back to the non flipped version. But it is still a good check; more people will perceive something as getting expensive than too expensive.
Interpretation
Much has been written on interpreting the different intersections and the relationships between intersections of Van Westendorp plots. Personally, I think the most useful result is the Range of Acceptable Prices. The lower bound is the intersection of Too Cheap and Expensive (sometimes called the point of marginal cheapness). The upper bound is the intersection of Too Expensive and Not Expensive (the point of marginal expensiveness). In the chart above, this range is from $10 to $25. As you can see, there is a very significant perception shift below $10. The size of the shift is partly accounted for by the fact that $10 is an even value. People believe that $9.99 is very different from $10; even though this survey used whole dollar numbers, this effect is still apparent. Although the upper intersection is at $25, the Too Expensive and Not Expensive lines don't diverge much until $30. In this case, anywhere between $25 and $30 for the upper bound would probably make little difference – at least before testing demand.
Some people think the so-called optimal price (the intersection of Too Expensive and Too Cheap) is useful, but I think there is a danger of trying to create static perfection in a dynamic world, especially since pricing research is generally only one input to a pricing decision. For more on the overall discipline of pricing, Thomas Nagle's book is a great source.
Going Beyond Van Westendorp's Original Questions
As originally proposed, the Van Westendorp questions provide no information about willingness to purchase, and thus nothing about expected revenue or margin.
To provide more insight into demand and profit, we can add one or two more questions.
The simple approach is to add a single question along the following lines:
At a price between the price you identified as 'a bargain' and the price you said was 'getting expensive', how likely would you be to purchase?
With a single question, we'd generally use a Likert scale response (Very unlikely, Unlikely, Unsure, Likely, Very Likely) and apply a model to generate an expected purchase likelihood at each point. The model will probably vary by product and situation, but let's say 70% of Very Likely + 50% of Likely as a starting point. It is generally better to be conservative and assume that fewer will actually buy than tell you they will, but there is no harm in using what-ifs to plan in case of a runaway success, especially if there is a manufacturing impact.
A more comprehensive approach is to ask separate questions for the 'bargain' and 'getting expensive' prices, in this case using percentage responses. The resulting data can be turned into demand/revenue curves, again based on modeled assumptions or what-ifs for the specific situation.
Again, there are myriad methodologies and submethodologies we may choose to use at this point in our analysis, and many times our selection of methodology may come down to a balance of speed, cost, key research questions to be answered, and other major concerns. The consideration of the use and nuance of all of the methodologies would be a course unto itself, so we have taken a view of the major families of research which may be of value in our work, allowing us to gain some experience for ourselves in the future as to what each of us prefers.
