Innovators in many fields, including engineers, computer scientists, geographers, and others, started developing digital mapping systems in the 1950s and 60s. One of the first challenges they faced was to convert the graphical data stored on paper maps into digital data that could be stored in, and processed by, digital computers. Several different approaches to representing locations and extents in digital form were developed. The two predominant data representation strategies are known as "vector" and "raster."
Recall that data consist of symbols that represent measurements. Digital geographic data are encoded as alphanumeric symbols that represent locations and attributes of locations measured at or near Earth's surface. No geographic data set represents every possible location, of course. The Earth is too big, and the number of unique locations is mathematically infinite. In much the same way that public opinion is measured through polls, geographic data are constructed by measuring representative samples of locations. And just as serious opinion polls are based on sound principles of statistical sampling, so, too, do geographic data represent reality by measuring carefully chosen samples of locations. Vector and raster data are, in essence, two distinct sampling strategies: vector and raster.
The vector approach involves sampling either specific point locations, point intervals along the length of linear entities (like roads), or points surrounding the perimeter of areal entities (like water bodies such as lakes or oceans). When the points are connected by lines or arcs, the sampled points form line features and polygon features that approximate the shapes of their real-world counterparts.
Try This:
Click the graphic above to download and view the animation file (vector.avi, 1.6 Mb) in a separate Microsoft Media Player window. View the same animation in QuickTime format (vector.mov, 1.6 Mb) here. Requires the QuickTime plugin, which is available free at the Apple Quicktime download site.
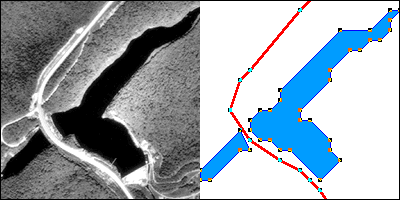
The aerial photograph above left shows two entities, a reservoir and a highway. The graphic above right illustrates how the entities might be represented with vector data. The small squares are nodes: point locations specified by latitude and longitude coordinates. Line segments connect nodes to form line features. In this case, the line feature colored red represents the highway. A series of line segments that begin and end at the same node form polygon features. In this case, two polygons (filled with blue) represent the reservoir.
The vector data model is consistent with how surveyors measure locations at intervals as they traverse a property boundary. The vector strategy is well suited to mapping entities with well-defined edges, such as highways or pipelines or property parcels. Many of the features shown on paper maps, including transportation routes, rivers, and political boundaries, can be represented effectively in digital form using the vector data model.
The raster approach involves sampling attributes for a set of cells having a fixed size. Each sample represents one cell, or pixel, in a checkerboard-shaped grid, as shown in Figure 4.14 below. The cells shown are square, but raster data can be generated with any regular subdivision into interconnected, non-overlapping cells that are identical in shape. While most raster data use square cells, rectangular and hexagonal cells are also encountered.
Try This:
Click the graphic above to download and view the animation file (raster.avi, 0.8 Mb) in a separate Microsoft Media Player window. View the same animation in QuickTime format (raster.mov, 0.6 Mb) here. Requires the QuickTime plugin, which is available free at at the Apple Quicktime download site.
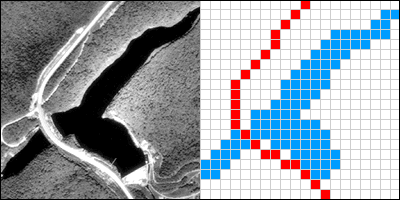
The graphic above illustrates a raster representation of the same reservoir and highway as shown in the vector representation. The area covered by the aerial photograph has been divided into a grid. Every grid cell that overlaps one of the two selected entities is encoded with an attribute that associates it with the entity it represents. Actual raster data would not consist of a picture of red and blue grid cells, of course; they would consist of a list of values (either categorical or numerical), one value for each grid cell, each number representing an entity. For example, grid cells that represent the highway might be represented with the value "1" or “H” (either of which could be used to represent the highway category) and grid cells representing the reservoir might be coded with the value "2" or “R” (representing the reservoir category).
The raster strategy is a smart choice for representing phenomena that lack clear-cut boundaries, such as terrain elevation, vegetation, and precipitation. Digital airborne imaging systems, which are replacing photographic cameras as primary sources of detailed geographic data, produce raster data by scanning the Earth's surface pixel by pixel and row by row. This will be discussed in more detail in Chapter 8, Info Without Being There: Imaging Our World.
Both the vector and raster approaches accomplish the same thing: they allow us to represent the Earth's surface with a limited number of locations. What distinguishes the two is the sampling strategies they embody. The vector approach is like creating a picture of a landscape with shards of stained glass cut to various shapes and sizes. The raster approach, by contrast, is more like creating a mosaic with tiles of uniform size. Neither is well suited to all applications, however. Several variations on the vector and raster themes are in use for specialized applications, and the development of new object-oriented approaches is underway.
Practice Quiz
Registered Penn State students should return now take the Chapter 4 practice quiz in Canvas to take a self-assessment: Vector Versus Raster.
You may take practice quizzes as many times as you wish. They are not scored and do not affect your grade in any way.