Introduction
In this lesson, we will look at data and the databases in which we store our data. It is frequently claimed that 80% of all data has a spatial component. Tracking this claim down turns out to be quite tricky. But there is no doubt that a tremendous amount of data in the contemporary world has a location component of some sort. This makes almost everyone's data a potential geographic resource (good news if you are hoping for job security). In many cases however, simply noting that a dataset has a geographic component just means that there is an address or coordinate pair associated with each record; to treat this data as spatial will require the use of a geocoder which can convert addresses to a spatial locations (or vice versa).
An initial way to approach spatial data handling is to consider formatting; in which format is your data available, and which format would you really like it to be? Once you have managed to coerce the data into a useful format, you need to store it somewhere. You could leave it in local file storage systems, but that can become slow, present a challenge if you need to share the data, and contemporary spatial databases can be huge. In many cases, there are advantages to storing spatial data on a network, either on a server you maintain or via a cloud storage provider. The choices you have for the database structure that collects and organizes everything is what we'll consider later in this lesson. Once you have data storage figured out, it's crucial to consider how well you can retrieve that data later on. Vendor lock-in can play a role here, as some organizations have found themselves paying considerable sums every year in license fees as they are stuck with an expensive database that effectively holds their data hostage.
Data Formats
There is a dizzying range of possible formats in which spatial data might be captured or transformed. As part of its long term digital preservation efforts, the U.S. Library of Congress tries to document as many of these spatial data formats as possible. Their current list documents 38 different major types, many of which have multiple distinct subtypes. Vector and raster types are documented, as are the ways in which files are read. Imagine the challenge the Library of Congress has in doing digital preservation of spatial data sources - if you had to document how things work so that future generations could use your data, how would you go about that task?
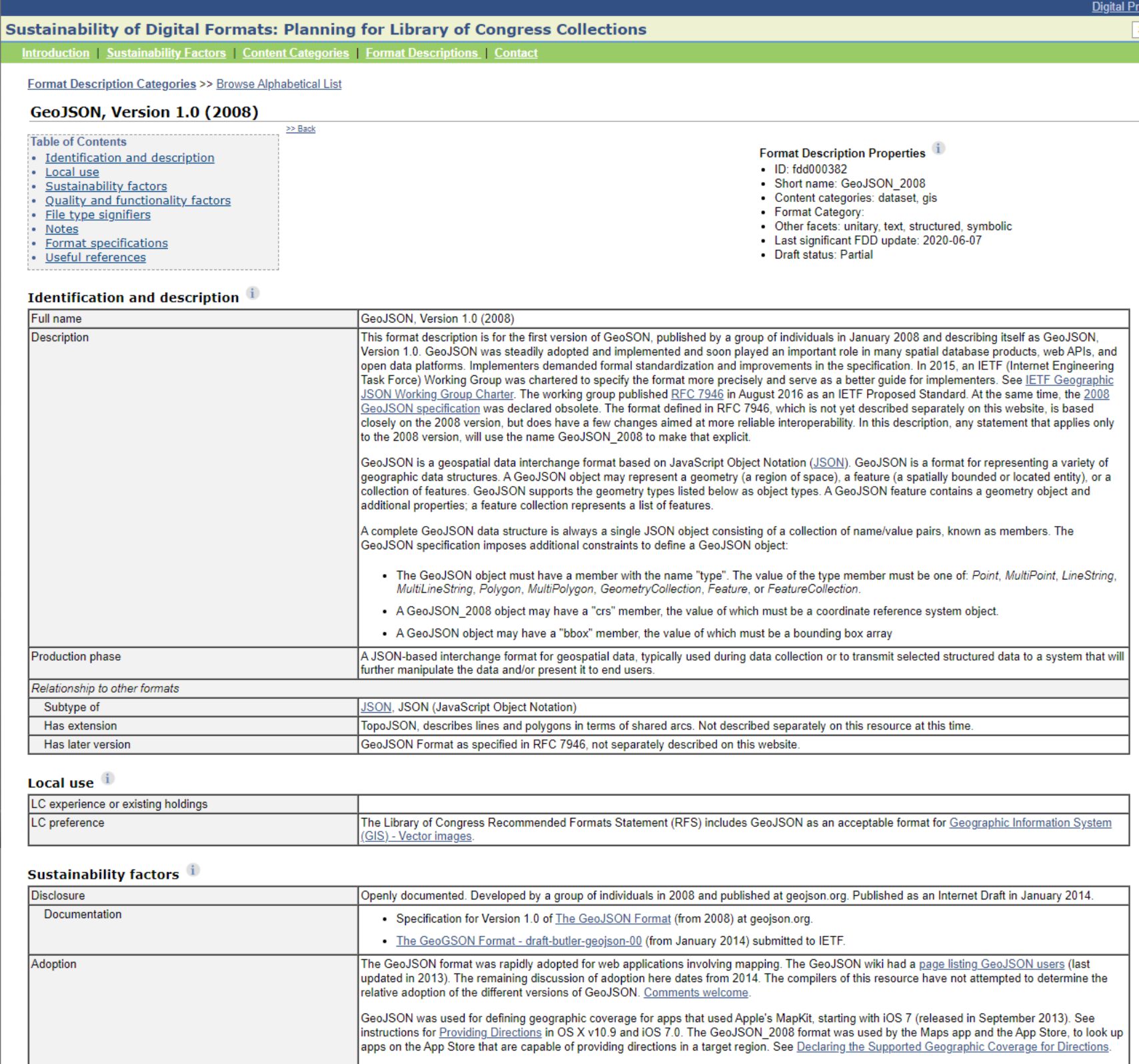
Spatial Data Input
Once you have selected the dataset that you need for your project, the most pressing need is to import this data into your GIS. There are two main problems in this situation. The first relates to what format your data is in and which formats your GIS can handle. For many years, the lingua franca of the vector GIS world has been the Esri shapefile - in large part due to the fact that Esri published the specification online for all to read and implement. This has led to many implementations, both proprietary and open source, which are widely used in GIS tools today. For the raster GIS world, there are many formats in common use. One choice is the GeoTiff, which is a public domain standard that describes how to include georeferencing data in the image file's metadata. For more complex earth science data, a popular choice is the netCDF format, which supports data compression to improve handling of large repositories.
If you are stuck with a dataset in a format your GIS can not import, the open source suite of tools GDAL/OGR provides conversion utilities to read in and write out a wide variety of raster (GDAL) and vector (OGR) formats.
Another common problem in loading data is the need to know what projection and coordinate system corresponds to your dataset. While logically one might think that nobody would ever create a dataset without producing matching metadata, by now you know that this is all too common. This problem is becoming worse. As creating geographic data becomes easier, more and more data is turning up as just a text file or a shapefile with no projection. As a well-trained geographer, you'd never make that mistake, but if you get stuck with a dataset with no projection information, you will probably want to visit spatialreference.org, which provides a searchable list of projections and provides them in a large number of common description formats that you can graft on to your files.
Spatial Data Infrastructure
It's one thing to have your data inputs sorted out, but it's another entirely to develop the means by which others can access what you've collected. An entire class could be taught around the tools and methods that make up contemporary spatial data infrastructures (SDI), but the key ingredients of an SDI include geoportals, metadata standards, and search capabilities. If you've ever used the USGS National Map, then you've interacted with a fully-fledged SDI in action. Collecting and organizing spatial data for a large organization or government isn't enough - you need to deliberately engineer solutions, then, to make sure others can browse, search for, and retrieve those data. I recommend taking a look at how the USGS developed the National Map framework and then comparing what you see there to what the European Union has done with their INSPIRE Geoportal - the latter effort requiring high-level data coordination with 32 different countries in Europe (EU + EFTA members).