Many different systematic classification schemes have been developed. Some produce "optimal" classes for unique data sets, maximizing the difference between classes and minimizing differences within classes. Since optimizing schemes produce unique solutions, however, they are not the best choice when several maps need to be compared. For this, data classification schemes that treat every data set alike are preferred.
Two commonly used schemes are quantiles and equal intervals ("quartiles," "quintiles," and "percentiles" are instances of quantile classifications that group data into four, five, and 100 classes respectively). The following two graphs illustrate the differences.
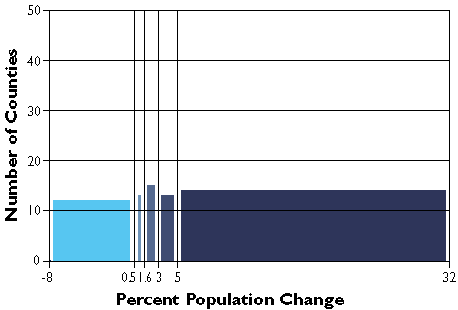
The graph in Figure 3.19.2 groups the Pennsylvania county population change data into five classes, each of which contains the same number of counties (in this case, approximately 20 percent of the total in each). The quantiles scheme accomplishes this by varying the width, or range, of each class.
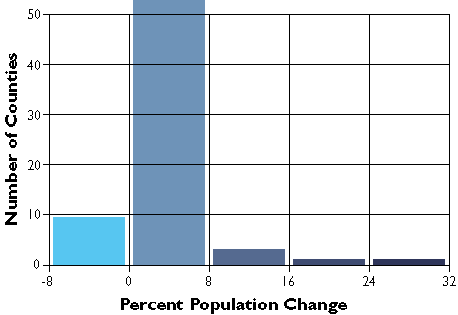
In the second graph, Figure 3.19.3, the width or range of each class is equivalent (8 percentage points). Consequently, the number of counties in each equal interval class varies.
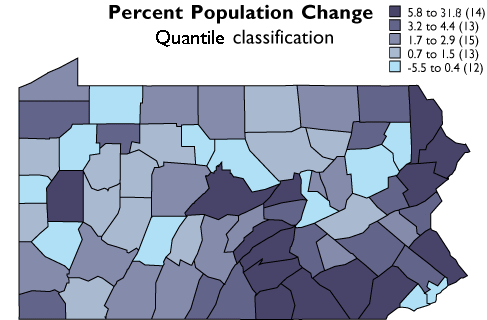
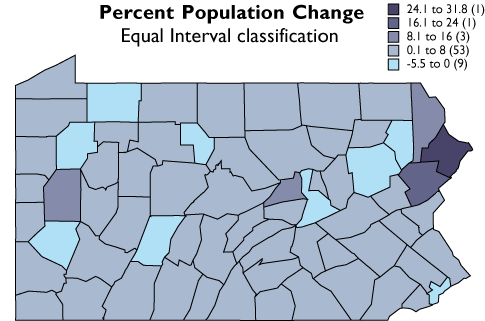
As you can see, the effect of the two different classification schemes on the appearance of the two choropleth maps above is dramatic. The quantiles scheme is often preferred because it prevents the clumping of observations into a few categories shown in the equal intervals map. Conversely, the equal interval map reveals two outlier counties which are obscured in the quantiles map. A good point to take from this little experiment is that it is often useful to compare the maps produced by several different map classifications. Patterns that persist through changes in classification scheme are likely to be more conclusive evidence than patterns that shift.