Sixteen U.S. Marshals and 650 assistants conducted the first U.S. census in 1791. They counted some 3.9 million individuals, although as then-Secretary of State, Thomas Jefferson, reported to President George Washington, the official number understated the actual population by at least 2.5 percent (Roberts, 1994). By 1960, when the U.S. population had reached 179 million, it was no longer practical to have a census taker visit every household. The Census Bureau then began to distribute questionnaires by mail. Of the 116 million households to which questionnaires were sent in 2000, 72 percent responded by mail. A mostly-temporary staff of over 800,000 was needed to visit the remaining households, and to produce the final count of 281,421,906. Using statistically reliable estimates produced from exhaustive follow-up surveys, the Bureau's permanent staff determined that the final count was accurate to within 1.6 percent of the actual number (although the count was less accurate for young and minority residences than it was for older and white residents). It was the largest and most accurate census to that time. (Interestingly, Congress insists that the original enumeration or "head count" be used as the official population count, even though the estimate calculated from samples by Census Bureau statisticians is demonstrably more accurate.)
The mail-in response rate for the 2010 census was also 72 percent. As with most of the 20th century censuses the official 2010 census count, by state, had to be delivered to the Office of the President by December 31 of the census year. Then within one week of the opening of the next session of the Congress, the President reported to the House of Representatives the apportionment population counts and the number of Representatives to which each state was entitled.
In 1791, census takers asked relatively few questions. They wanted to know the numbers of free persons, slaves, and free males over age 16, as well as the sex and race of each individual. (You can view photos of historical census questionnaires here(link is external)) As the U.S. population has grown, and as its economy and government have expanded, the amount and variety of data collected has expanded accordingly. In the 2000 census, all 116 million U.S. households were asked six population questions (names, telephone numbers, sex, age and date of birth, Hispanic origin, and race), and one housing question (whether the residence is owned or rented). In addition, a statistical sample of one in six households received a "long form" that asked 46 more questions, including detailed housing characteristics, expenses, citizenship, military service, health problems, employment status, place of work, commuting, and income. From the sampled data, the Census Bureau produced estimated data on all these variables for the entire population.
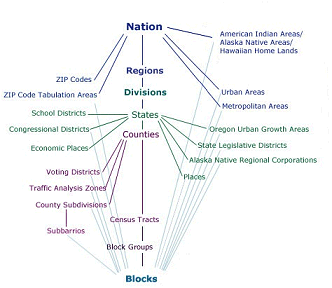
In the parlance of the Census Bureau, data associated with questions asked of all households are called 100% data and data estimated from samples are called sample data. Both types of data are available aggregated by various enumeration areas, including census block, block group, tract, place, county, and state (see the illustration below). Through 2000, the Census Bureau distributes the 100% data in a package called the "Summary File 1" (SF1) and the sample data as "Summary File 3" (SF3). In 2005, the Bureau launched a new project called American Community Survey that surveys a representative sample of households on an ongoing basis. Every month, one household out of every 480 in each county or equivalent area receives a survey similar to the old "long form." Annual or semi-annual estimates produced from American Community Survey samples replaced the SF3 data product in 2010.
To protect respondents' confidentiality, as well as to make the data most useful to legislators, the Census Bureau aggregates the data it collects from household surveys to several different types of geographic areas. SF1 data, for instance, are reported at the block or tract level. There were about 8.5 million census blocks in 2000. By definition, census blocks are bounded on all sides by streets, streams, or political boundaries. Census tracts are larger areas that have between 2,500 and 8,000 residents. When first delineated, tracts were relatively homogeneous with respect to population characteristics, economic status, and living conditions. A typical census tract consists of about five or six sub-areas called block groups. As the name implies, block groups are composed of several census blocks. American Community Survey estimates, like the SF3 data that preceded them, are reported at the block group level or higher.