Back in Chapter 3, we considered the classification of thematic data for choropleth maps. Remember? We approached data classification as a kind of generalization technique, and made the claim that "generalization helps make sense of complex data." The same is true in the context of remotely sensed image data.
A key trend in image classification is the emergence of object-based alternatives to traditional pixel-based techniques. A Penn State lecturer has observed, "For much of the past four decades, approaches to the automated classification of images have focused almost solely on the spectral properties of pixels" (O'Neil-Dunne, 2011). Pixel-based approaches made sense initially, O'Neil-Dunne points out, since "processing capabilities were limited and pixels in the early satellite images were relatively large and contained a considerable amount of spectral information." In recent years, however, pixel-based approaches have begun to be overtaken by object-based image analysis (OBIA) for high-resolution multispectral imagery, especially when fused with lidar data. OBIA is beyond the scope of this chapter, but you can study it in depth in the open-access Penn State courseware GEOG 883: Remote Sensing Image Analysis and Applications.
Pixel-based classification techniques are commonly used in land use and land cover mapping from imagery. These are explained below and in the following case study.
The term land cover refers to the kinds of vegetation that blanket the Earth's surface, or the kinds of materials that form the surface where vegetation is absent. Land use, by contrast, refers to the functional roles that the land plays in human economic activities (Campbell, 1983).
Both land use and land cover are specified in terms of generalized categories. For instance, an early classification system adopted by a World Land Use Commission in 1949 consisted of nine primary categories, including settlements and associated non-agricultural lands, horticulture, tree and other perennial crops, cropland, improved permanent pasture, unimproved grazing land, woodlands, swamps and marshes, and unproductive land. Prior to the era of digital image processing, specially trained personnel drew land use maps by visually interpreting the shape, size, pattern, tone, texture, and shadows cast by features shown in aerial photographs. As you might imagine, this was an expensive, time-consuming process. It's not surprising, then, that the Commission appointed in 1949 failed in its attempt to produce a detailed global land use map.
Part of the appeal of digital image processing is the potential to automate land use and land cover mapping. To realize this potential, image analysts have developed a family of image classification techniques that automatically sort pixels with similar multispectral reflectance values into clusters that, ideally, correspond to functional land use and land cover categories. Two general types of pixel-based image classification techniques have been developed: supervised and unsupervised techniques.
Supervised classification
Human image analysts play crucial roles in both supervised and unsupervised image classification procedures. In supervised classification, the analyst's role is to specify in advance the multispectral reflectance or (in the case of the thermal infrared band) emittance values typical of each land use or land cover class.

For instance, to perform a supervised classification of the Landsat Thematic Mapper (TM) data shown above into two land cover categories, Vegetation and Other, you would first delineate several training fields that are representative of each land cover class. The illustration below shows two training fields for each class; however, to achieve the most reliable classification possible, you would define as many as 100 or more training fields per class.

The training fields you defined consist of clusters of pixels with similar reflectance or emittance values. If you did a good job in supervising the training stage of the classification, each cluster would represent the range of spectral characteristics exhibited by its corresponding land cover class. Once the clusters are defined, you would apply a classification algorithm to sort the remaining pixels in the scene into the class with the most similar spectral characteristics. One of the most commonly used algorithms computes the statistical probability that each pixel belongs to each class. Pixels are then assigned to the class associated with the highest probability. Algorithms of this kind are known as maximum likelihood classifiers. The result is an image like the one shown below, in which every pixel has been assigned to one of two land cover classes.
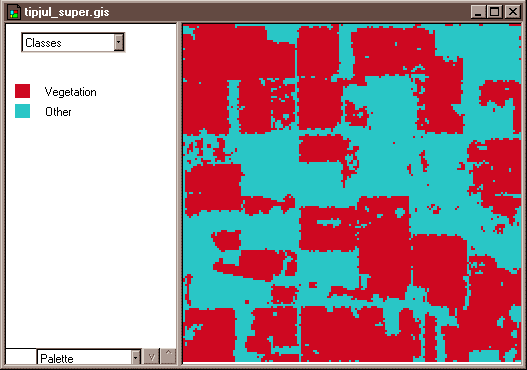
Unsupervised classification
The image analyst plays a different role in unsupervised classification. They do not define training fields for each land cover class in advance. Instead, they rely on one of a family of statistical clustering algorithms to sort pixels into distinct spectral classes. Analysts may or may not even specify the number of classes in advance. Their responsibility is to determine the correspondences between the spectral classes that the algorithm defines and the functional land use and land cover categories established by agencies like the U.S. Geological Survey. The example that follows outlines how unsupervised classification contributes to the creation of a high-resolution national land cover data set.
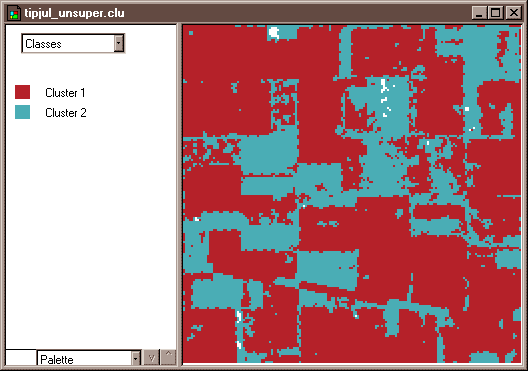
The following case study contrasts unsupervised and supervised classification techniques used to create the U.S. National Land Cover Database.